通过Ti-One机器学习平台玩转2020腾讯广告算法大赛:数据预处理
准备
查看磁盘的基本信息
!df -hl

!pwd
![]()
我们这里只做最基本的数据处理所以只引入了基本包
另外引入了ti的session后面通过它将数据上传到cos
import os, gc
import pandas as pd
import numpy as np
from ti import session
ts=session.Session()
下载和解压
这里直接下载官方提供的zip包
!wget https://tesla-ap-shanghai-1256322946.cos.ap-shanghai.myqcloud.com/cephfs/tesla_common/deeplearning/dataset/algo_contest/test.zip
!wget https://tesla-ap-shanghai-1256322946.cos.ap-shanghai.myqcloud.com/cephfs/tesla_common/deeplearning/dataset/algo_contest/train_preliminary.zip

因为算是同一个网络,下载速度还是挺快的
下载完成后解压
!unzip train_preliminary.zip

!unzip test.zip

预处理
def reduce_mem_usage(df, verbose=True):
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
start_mem = df.memory_usage().sum() / 1024 ** 2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024 ** 2
if verbose: print('Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)'.format(end_mem, 100 * (
start_mem - end_mem) / start_mem))
return df
参加过kaggle比赛的小伙伴一定很熟悉,这个就是在kaggle比在中常用的对dataframe减小内存的方法,我们直接拿来使用,这个方法也是fastai库中使用的
读取数据
我们将训练和测试数据合并,并打上标签
train_dir = "train_preliminary/"
test_dir = "test/"
click_train = pd.read_csv(train_dir + "click_log.csv")
click_train = reduce_mem_usage(click_train)
ad_train = pd.read_csv(train_dir + "ad.csv")
ad_train = reduce_mem_usage(ad_train)
click_log = click_train.merge(ad_train, how="left", on="creative_id", )
click_log["type"] = "train"
click_test = pd.read_csv(test_dir + "click_log.csv")
ad_test = pd.read_csv(test_dir + "ad.csv")
click_test = reduce_mem_usage(click_test)
ad_test = reduce_mem_usage(ad_test)
click_log_test = click_test.merge(ad_test, how="left", on="creative_id", )
click_log_test['type'] = "test"

click_all = click_log.append(click_log_test)
click_all是包含了所有数据的dataframe,可以先把它存起来,这样以后就拿来直接用了
click_all.to_pickle("all-raw.pkl")
上传到cos留个备份
ts.upload_data("all-raw.pkl",bucket="桶名")
![]()
会返回实际的存储地址,默认会建立一个data目录保存我们上传的数据
如果需要从cos获取数据时我们可以直接使用上面的wget命令进行下载,地址可以在cos里面文件详细信息页面中找到,直接复制对象地址即可
简单分析
已经有了pandas的dataframe,下面就可以对数据进行简单的分析了
比如:
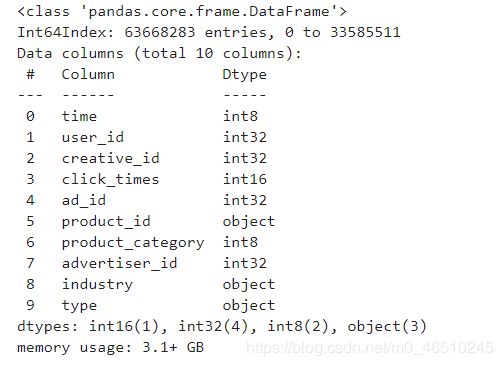
click_all.info()
查看各列的唯一数总数
for col in click_all.columns:
print(col,click_all[col].nunique())

各列的汇总
click_all.describe()

看到统计信息里面不包含product_id 和industry,说明里面可能有字符串信息,肉眼观察发现里面有一些数据被标记为\N,我这里处理的方式比较简单粗暴,就是使用0进行替换
click_all["product_id"]=click_all['product_id'].apply(lambda x : 0 if x == '\\N' else x)
click_all["industry"]=click_all['industry'].apply(lambda x : 0 if x == '\\N' else x)
替换完成后再整理一下数据类型
click_all["product_id"]=click_all["product_id"].astype(np.int32)
click_all["industry"]=click_all["industry"].astype(np.int32)
click_all = reduce_mem_usage(click_all)
click_all.info()

这样就可以了,虽然还有特征工程要做,但是这样的数据已经达到了输入到模型中进行训练的最基本的要求了。
pandas还有一个强大的功能就是可以建立直方图帮我们观察数据的分布
cols=["creative_id", "click_times", "ad_id",
"product_id", "advertiser_id", "industry", ]
for col in cols:
if col=="type":
continue
click_all.hist(col)
这条语句会显示所有列的直方图,我们以一个为例:

点击次数中我们看到大部分数据都分布在25以内,但是他的最大值是185。
我们继续使用箱型图印证对于click_times的观点,使用箱型图可以查看
click_all.boxplot("click_times",vert=False, grid = True)

看到这个图对数据分析有过理解的小伙伴一定就知道了,我们可以看一下
# 上四分位数
cl=click_all["click_times"]
q3 = cl.quantile(q=0.75)
#下四分位数
q1 = cl.quantile(q=0.25)
print(q3,q1)

上四分位数和下四分位数都是1,我们根本就不需要查看异常值了,这就说明都会被算作异常值
#可以试试这个代码,看看怎么判断
cl01 = cl[(cl>q3+1.5*iqr) | (cl看看这些值到底是什么样的
click_all[click_all["click_times"]>100]

大于100的click大部分都是test数据集的,这里肯定是一个坑。
这里我们指定了click_times,如果不指定pandas会绘制所有列的箱型图,但是由于数据级数不一样,所以合并看意义不大。
最后我们来看一下对于每个用户,每天都有多少次点击:
user=click_all.groupby(["time","user_id"])['click_times'].count().reset_index(name="count")
user[user["count"]>2000]
还有每天点击大于2000的用户

user.boxplot("count",vert=False, grid = True)

# 上四分位数
cl=user["count"]
q3 = cl.quantile(q=0.75)
#下四分位数
q1 = cl.quantile(q=0.25)
print(q3,q1)
iqr = q3-q1
print("上四分位数:{}\n下四分位数:{}\n四分位差{}".format(q3,q1,iqr))
cl01 = cl[(cl>q3+1.5*iqr) | (cl
异常值我们先不管,这里能明显的看出,肯定有一部分数据是垃圾数据,或者说一部分用户是干扰用户,可以再深入研究下将其删除
本篇文章就先讲这么多吧,最后祝大家比赛取得好成绩