Spatial-aware Graph Relation Network for Large-scale Object Detection
文章目录
- 1. 摘要
- 2. 引言与相关方法
- 2.1 引言
- 2.2 关于视觉推理 Visual Reasoning
- 3. 本文主要方法
- 3.1 Overview
- 3.2 关系学习模块
- 3.3 Visual Embeddings of the Regions
- 3.4 空间感知的图预测模块
- 3.5 SGRN for Multiple Domains
- 4. 实验
- 5. 总结

用于大规模目标检测的空间感知图关系网络
1. 摘要
如何在不需要任何外部知识的情况下在检测系统中正确编码高阶对象关系呢?
如何利用共现和物体位置之间的信息进行更好的推理?
这些问题是面向大规模目标检测系统的关键挑战,其目的是识别出成千上万的目标中的复杂空间信息和语义关系。
提取可能影响目标识别的关键关系至关重要,因为在面对大量长尾数据分布和大量令人困惑的类别时,分别处理每个区域会导致性能大幅下降。最近的研究试图通过构建图来对关系进行编码,例如在类之间使用手工语言知识或隐式学习区域之间的全连通图。
然而,由于语言和视觉语境之间存在语义鸿沟,手工语言知识无法对每一幅图像进行个性化处理,而全连通图由于包含了来自无关对象和背景的冗余和分散的关系/边,效率低下且噪声大。
在这项工作中,本文引入了一个空间感知的图关系网络(SGRN)来自适应地发现和合并关键的语义和空间关系,以便对每个对象进行推理。我们的方法考虑了相对的位置布局和相互作用,可以很容易地注入到任何检测piplines中,以提高性能。
具体来说,本文的SGRN集成了一个图学习模块,学习可交互稀疏图结构来编码相关的上下文区域,以及一个具有可学习空间高斯内核的空间图推理模块来执行具有空间意识的图推理。
2. 引言与相关方法
2.1 引言
近年来,CNN检测器的更新主要集中在一些具有一定局限的数据集上,比如20类的VOC,80类的COCO,但是,实际对于大规模数据集具有越来越多的关注,比如具有3000类的VG数据集,这对于工业上,也更具有实际的价值。目前,检测的piplines主要是分别识别每个目标,因此对于具有长尾效应的数据集来说效果会下降很多。在深度学习普及之前,物体之间的关系可以帮助提高物体的识别能力,这已经得到了社会的广泛认可。通过引入关系的信息可以增加更多的上下文信息,减轻上述存在的问题。因此,如何捕捉并统一语义关系和空间关系,提高性能是大规模对象检测的关键问题。
随着几何深度学习的不断深入,利用图这种灵活的两两互动的建模结构,使图成为一种最合适的关系建模方法。
图1给出了不同设计选择的图解,图中编码了检测任务的两两关系。图1a使用手工语言知识来构建一个类到类的图。例如,Jiang等人最近尝试将语义关系推理引入到不同类型的知识形式的大规模检测中。然而,他们的方法很大程度上依赖于VG数据的属性和关系注释。此外,由于语言语境和视觉语境的语义差异,一些空间关系可能被忽略,固定的图形也不能适应图像。
另一方面,一些作品试图从图1b所示的视觉特征中隐式学习区域间的全连通图。例如,Hu等人介绍了一种关系网络,它使用一个自适应的注意模块来允许对象的视觉特征之间的交互。然而,它们的全连通关系是低效和嘈杂的,通过合并来自不相关的对象和背景的冗余和分心的关系/边缘,而成对的空间信息也没有得到充分利用。
因此,本文的工作目标是开发一个基于图的网络,它可以对空间信息的感知进行建模,并从训练图像中直接有效地学习一个可解释的稀疏图结构。图1c显示,本文的方法利用语义关系和空间关系来学习空间感知的稀疏图。
本文的方法主要包括两个方面:一个是稀疏图学习模块,一个是空间感知图卷积模块。
不同于定义一个类到类的图,而是将建议区域定义为图的节点。一个稀疏图结构是可以通过关系学习模块来进行学习的。这不仅可以识别出图像中最相关的区域,帮助识别图像中的对象,而且避免了不相关区域的不必要开销。
空间感知图卷积模块是通过可学习的空间高斯核进行驱动的。图卷积中的高斯核的设计使得图的传播能够感知不同的空间关系,如图1c所示。最终,每个区域的新的增强后的上下文信息被concat到原来的特征图上来提高分类和定位的能力。本文方法是一种嵌入式的、可以很方便进行插入的模块。
2.2 关于视觉推理 Visual Reasoning
视觉推理的目的是结合不同的信息或物体或场景之间的相互作用。早期的方法主要是使用手工设计的关系,最近的工作开始考虑使用图卷积神经网络。
3. 本文主要方法
3.1 Overview
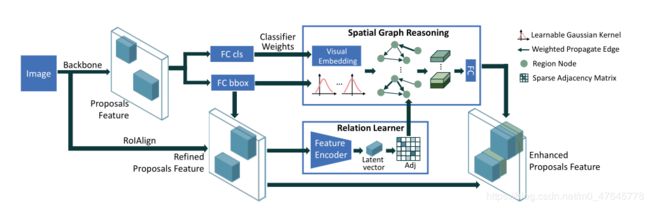
上图所示为本文所提出的SGRN模块,可以嵌入到目前的主流的目标检测网络中,提高检测的效果。
在本文中,关系被定义为一个区域到区域的无向图:![]()
关系图学习模块首先从视觉特征中学习一个可解释的稀疏邻接矩阵,该矩阵只保留与目标识别最相关的连接。然后对前一分类层的权值进行收集,软映射到各个区域,成为每个区域的可视化嵌入。计算区域之间的成对空间信息(距离、角度等),并输入高斯核以确定图的卷积模式。
在空间感知图推理模块中,根据稀疏邻接矩阵和高斯核对不同区域的视觉嵌入进行优化和传播。
3.2 关系学习模块
该模块的目的是生成一个与目标检测相关的建议区域之间关系的图形表示。
使用无向图进行表示![]()
其中, N N N中的每个节点对应每个建议区域, ε \varepsilon ε中的每条边表示两个节点之间的关系, ε ∈ R N r X N r \varepsilon \in R^{N_rXN_r} ε∈RNrXNr.
给出从backbone中提取出的 D D D维区域视觉特征,使用 f = f i i = 1 N r , f i ∈ R D f={{{f_i}}}_{i=1}^{N_r},f_i\in R^D f=fii=1Nr,fi∈RD作为本模块的输入,首先将视觉特征利用非线性转换方式转换到隐藏空间 Z Z Z,
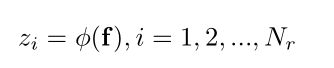
其中, Z i ∈ R L {Z_i} \in R^L Zi∈RL, L L L隐藏空间的维度, ϕ ( . ) \phi(.) ϕ(.)表示非线性函数,本文中,使用两个全连接层和ReLU激活函数作为非线性函数。
使用 Z ∈ R N r X L Z \in R^{N_rXL} Z∈RNrXL作为 z i i = 1 N r , z i ∈ R L {z_i}_{i=1}^{N_r},z_i\in R^L zii=1Nr,zi∈RL的集合,无向图的邻接矩阵可通过矩阵相乘来计算, ε = Z Z T \varepsilon=ZZ^T ε=ZZT,因此 e i , j = z i z j T e_{i,j}=z_iz_j^T ei,j=zizjT。
注意在这个地方,仍有很多背景(负样本)存在于建议区域中。使用一个全连接的邻接矩阵 ε \varepsilon ε可以建立起和负样本之间的关系。一些冗余的边会导致产生较多的计算量。而且,后续的空间感知图的卷积会对信息进行过度传播,所有节点的图的卷积输出将是相同的。
为了解决这个问题,需要在图的稀疏度方面增加一个约束条件。对于每一个区域建议 i i i,只保留每组 ε \varepsilon ε的top t t t个最大值。也就是说,最多 t t t个相关节点被挑选出来作为每个区域建议的邻居:
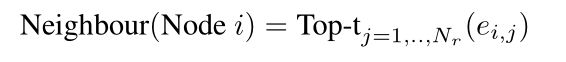
3.3 Visual Embeddings of the Regions
现有的大多数基于图的方法都是根据图的边在各区域之间局部传播视觉特征。然而,当区域视觉特征较差时,这些方法就会失效,导致传播效率低下甚至错误。注意,这种情况经常发生在大规模检测中,当图像中存在严重的遮挡和歧义时。为了缓解这个问题,我们的方法尝试在所有类别上传播信息。换句话说,我们的方法需要为每个类别创建一个高级语义可视化嵌入,它可以被视为一个特定对象类别的理想原型。
在一些 zero/few-shot问题中,使用分类器的权值作为一个不可见/不熟悉类别的嵌入或表示,本文尝试使用权值作为每个类别的视觉嵌入。这是因为分类器的权值实际上包含高级语义信息,因为它们记录了从所有图像中训练出来的特征激活。
W ∈ R C X ( D + 1 ) W\in R^{CX(D+1)} W∈RCX(D+1)表示分类器的权重参数,C是类别数,D表示视觉特征的维度。注意的是,在训练过程中W是更新的,因此视觉嵌入是会随着时间准确率越来越高的。
因为本文中的图G是区域到区域的,需要找出更精确的映射从类别视觉嵌入到节点的区域表示。本文使用一种 soft-mapping的方法来计算映射权重:
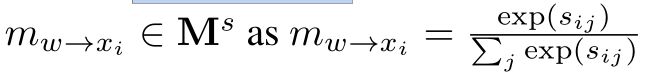
其中, s i , j s_{i,j} si,j表示从区域i到类别j的分类分数。空间感知的图预测模块的输入 X ∈ R N r X ( D + 1 ) X\in R^{N^r}X(D+1) X∈RNrX(D+1)可以通过 X = M s W X = M^sW X=MsW来计算。
![]()
是映射矩阵。
3.4 空间感知的图预测模块

基于上述的区域输入 X ∈ R N r X ( D + 1 ) X\in R^{N^r}X(D+1) X∈RNrX(D+1)以及可学习的边的节点 ε ∈ R N r X N r \varepsilon \in R^{N_rXN_r} ε∈RNrXNr,利用边进行主导的图的推理被用来学习一个新的目标表示。由于图像中区域的位置对于图的推理也很重要,因此在我们的图形推理模块中也应该考虑空间信息。
为了捕获成对的空间信息,本文能使用一个伪对等关系坐标 u ( a , b ) u(a,b) u(a,b)来表示,对于每个节点 a a a,通过 u ( a , b ) u(a,b) u(a,b)会返回节点 b b b的坐标。
在本文中,使用极坐标来表示这个伪对等关系 u ( a , b ) = ( d , θ ) u(a,b)=(d, \theta) u(a,b)=(d,θ),返回一个二维项目,分别表示两个中心点的距离和角度:
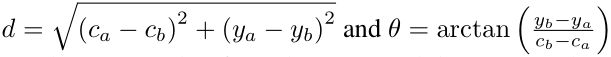
然后,需要通过定义一个patch算子来描述图中每个相邻节点的影响和传播,从而形成空间感知图推理。
通过一组可学习均值和方差的K阶高斯核来定义patch算子的。定义区域语义输入 x i ∈ X x_i\in X xi∈X,图结构 G = < N , ε > G=

其中 N e i g h b o u r ( i ) Neighbour(i) Neighbour(i)表示节点的邻居, w k ( . ) w_k(.) wk(.)表示k阶高斯核:

μ k \mu_k μk表示均值, Σ \Sigma Σ表示方差,矩阵。对于每一个节点 i i i, f k ′ ( i ) f_{k}^{'}(i) fk′(i)表示相邻的语义表示权重和,高斯核 ω k ( . ) \omega_k(.) ωk(.)编码了区域空间信息。对于每个节点的 f k ′ ( i ) f_{k}^{'}(i) fk′(i)concat起来,并进行一个线性变换![]()
E 表示每个区域的输出维度。最终,对于每个区域的 h i h_i hi concat到原始区域特征 f i f_i fi
3.5 SGRN for Multiple Domains
检测器通常基于全监督情况下进行训练,当具有新的数据和类别时必须重新训练。这是非常繁琐和耗时的。由于关系图学习模块和空间感知图推理模块可以在不同的数据集中重用,因此对SGRN的域可移植性特别感兴趣。
为了在新数据集上训练一个新的模型,首先将出去框的回归和类别预测两个层的参数复制,框的回归和类别预测的参数可以通过![]()
转换到目标数据集上。![]()
转换矩阵通过计算类别名称的词向量的cos距离。
4. 实验
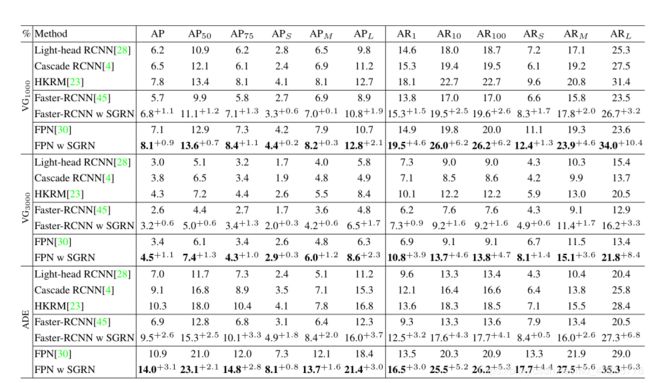
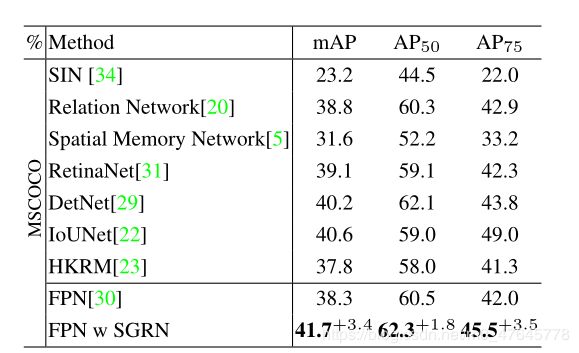
5. 总结
在本文中,提出了一种新的空间感知图关系网络(SGRN),用于在不需要任何外部知识的情况下对检测系统中的对象关系进行编码。方法是到位的,并很容易插入到任何现有的检测管道,赋予其捕捉和统一语义和空间关系的能力。