GBDT原理实例演示 1
考虑一个简单的例子来演示GBDT算法原理
下面是一个二分类问题,1表示可以考虑的相亲对象,0表示不考虑的相亲对象
特征维度有3个维度,分别对象 身高,金钱,颜值

cat dating.txt
#id,label,hight,money,face
_0,1,20,80,100
_1,1,60,90,25
_2,1,3,95,95
_3,1,66,95,60
_4,0,30,95,25
_5,0,20,12,55
_6,0,15,14,99
_7,0,10,99,2
这个例子仅仅为了试验,数据量很小没有更多统计意义。
0,1,2,3对应可以考虑的相亲对象
4,5,6,7 对应不考虑的相亲对象
先看一下gbdt训练的结果
mlt dating.txt -cl gbdt -ntree 2 -nl 3 -lr 0.1 -mil 1 -c train -vl 1 -mjson=1
设置2棵树,叶子节点最多3个 也就是最多2次分裂,learning rate设置为0.1, 叶子节点中的最少样本数设置为1(仅供试验,一般不会设置为1,避免过拟合)
为了打印二叉树设置输出json格式的模型
Per feature gain:
0:face 1
1:hight 0.730992
2:money 0.706716
Sigmoid/PlattCalibrator calibrating [ 8 ] (0.00011 s)100% |******************************************|
I0324 16:57:53.240083 17630 time_util.h:113] Train! finished using: [1.486 ms] (0.001486 s)
I0324 16:57:53.240094 17630 time_util.h:102] Test itself! started
TEST POSITIVE RATIO: 0.5000 (4/(4+4))
Confusion table:
||===============================||
|| PREDICTED ||
TRUTH || positive | negative || RECALL
||===============================||
positive|| 4 | 0 || 1.0000 (4/4)
negative|| 0 | 4 || 1.0000 (4/4)
||===============================||
PRECISION 1.0000 (4/4) 1.0000(4/4)
LOG LOSS/instance: 0.2981
TEST-SET ENTROPY (prior LL/in): 1.0000
LOG-LOSS REDUCTION (RIG): 70.1854%
OVERALL 0/1 ACCURACY: 1.0000 (8/8)
POS.PRECISION: 1.0000
PPOS.RECALL: 1.0000
NEG.PRECISION: 1.0000
NEG.RECALL: 1.0000
F1.SCORE: 1.0000
AUC: [1.0000]
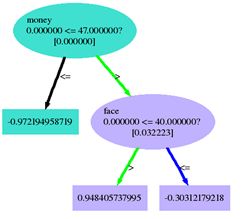
对应这个例子,训练结果是perfect的,全部正确, 特征权重可以看出,对应这个例子训练结果颜值的重要度最大,看一下训练得到的树。
print-gbdt-tree.py --tree -1
Tree 0:
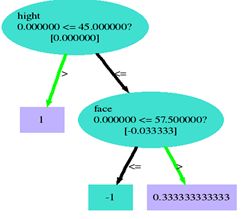
Tree 1: