SpringBoot集成Elasticsearch6.8.x实战
一、背景
假如你开发了一个博客网站,上线初期网站文章数量不多,这时候网站的上的全站搜索功能,直接依靠数据库查询实现,用于存储用户发表的文章的article表仅有几万条数据,MySQL查询还是轻松的。
 然而,过了一段时间,你打造的博客网站火了起来!!!用户越来越多,发表的文章数量也越来越多,眼看数据库article表,数据量爆炸性增长到上百万、千万,这时候网站的全站搜索响应的越来越慢,用户每点击一次搜索按钮,都是对自己耐心的考验!
然而,过了一段时间,你打造的博客网站火了起来!!!用户越来越多,发表的文章数量也越来越多,眼看数据库article表,数据量爆炸性增长到上百万、千万,这时候网站的全站搜索响应的越来越慢,用户每点击一次搜索按钮,都是对自己耐心的考验!
 作为网站负责人的你彻夜难眠,翻箱倒柜,查找解决方案,功夫不负有心人,终于在落满灰尘的新书看到了一篇关于Elasticsearch的介绍,此刻的你喜极而泣——网站有救了!!!
作为网站负责人的你彻夜难眠,翻箱倒柜,查找解决方案,功夫不负有心人,终于在落满灰尘的新书看到了一篇关于Elasticsearch的介绍,此刻的你喜极而泣——网站有救了!!!

二、ElasticSearch登场
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch能够做到实时搜索并且稳定,可靠。ElasticSearch官网戳这里
上面所描述问题就是一个典型的全文搜索场景。如果你不清楚什么是全文搜索?为什么需要全文全文搜索?那么你可以打开CSDN首页,在右上角的搜一搜里面随便输入一个关键字,比如JVM,搜索后会发现结果都是包含JVM的,并且标题JVM关键字都做了红色高亮。

所以这是怎么实现的呢? 难道是在数据库使用like语句模糊查询出来的?如果你是这想的,那么恭喜你——这是不可能的!因为数据量太大,就算SQL、索引什么的都达到最优,在海量数据面前仍然是杯水车薪。其次数据库扛不住,大量用户同时进行搜索,很容易数据库就给整挂了。
 而ElasticSearch就很容易做到——上亿级别的数据,毫秒级响应。我们需要做的就是为文章数据正确的创建ElasticSearch索引。
而ElasticSearch就很容易做到——上亿级别的数据,毫秒级响应。我们需要做的就是为文章数据正确的创建ElasticSearch索引。
ElasticSearch中有几个很重要的概念,这是我们在使用之前必须要知道的:
- Document 文档 ,一个文档是一个可被索引的基础信息单元,JSON格式
- Index 索引,一个索引就是一个拥有相似特征的document 的集合,一个索引由一个名字来标识(必须全部是小写字母的)
- Type 类型 在一个索引中,可以定义一种或多种类型,类型是索引的一个逻辑上的分类/分区,一个索引中可以存在很多Type
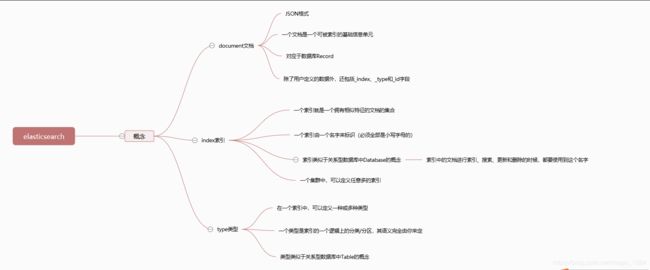 如果你感觉不太好理解,可以按照类比的方法,Index可以看作数据库Database,Type就是里面的表Table,而一个Document就是表中的一条记录。
如果你感觉不太好理解,可以按照类比的方法,Index可以看作数据库Database,Type就是里面的表Table,而一个Document就是表中的一条记录。
ElasticSearch提供了RESTful风格的API,在安装完成后,即可使其用对索引进行操作。另外关于ElasticSearch的安装教程,此处不再叙述。
三、与SpringBoot集成
此处我们的SpringBoot版本是2.2.0.RELEASE。ElasticSearch 6.8.1版本
SpringBoot集成ElasticSearch很简单,只需要引入spring-data-elasticsearch依赖,添加配置即可。spring-data-elasticsearch让我们可以像使用JPA一样去操作ElasticSearch。
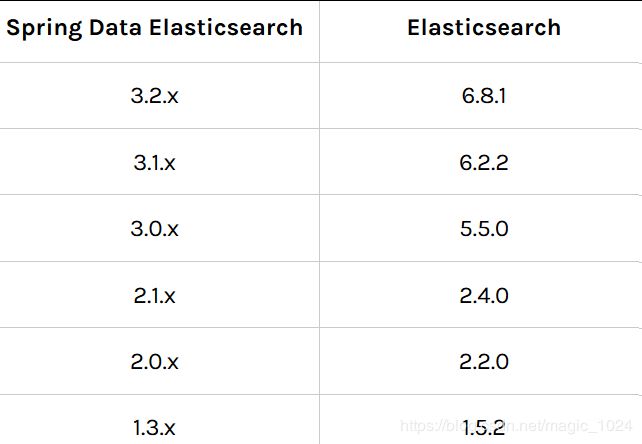
由于Elasticsearch版本较多目前已经7.5.x,spring-data-elasticsearch与对应的版本兼容性如下图:
1.添加spring-data-elasticsearch依赖
<dependency>
<groupId>org.springframework.datagroupId>
<artifactId>spring-data-elasticsearchartifactId>
<version>3.2.1.RELEASEversion>
dependency>
2.application.properties添加ElasticSearch连接信息
#Elasticsearch配置
elasticsearch.host=127.0.0.1
elasticsearch.port=9300
elasticsearch.clustername=myEsApplication
elasticsearch.search.pool.size=5
3.创建Elasticsearch配置类
package com.example.demo.config;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.client.Client;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.repository.config.EnableElasticsearchRepositories;
import java.net.InetAddress;
@Slf4j
@Configuration
@EnableElasticsearchRepositories(basePackages = "com.example.demo.dao")
public class ElasticsearchConfig {
@Value("${elasticsearch.host}")
private String esHost;
@Value("${elasticsearch.port}")
private int esPort;
@Value("${elasticsearch.clustername}")
private String esClusterName;
@Value("${elasticsearch.search.pool.size}")
private Integer threadPoolSearchSize;
@Bean
public Client client() throws Exception {
Settings esSettings = Settings.builder()
.put("cluster.name", esClusterName)
//增加嗅探机制,找到ES集群,非集群置为false
.put("client.transport.sniff", true)
//增加线程池个数
.put("thread_pool.search.size", threadPoolSearchSize)
.build();
return new PreBuiltTransportClient(esSettings)
.addTransportAddress(new TransportAddress(InetAddress.getByName(esHost), esPort));
}
@Bean(name="elasticsearchTemplate")
public ElasticsearchOperations elasticsearchTemplateCustom() throws Exception {
ElasticsearchTemplate elasticsearchTemplate;
try {
elasticsearchTemplate = new ElasticsearchTemplate(client());
return elasticsearchTemplate;
} catch (Exception e) {
log.error("初始化ElasticsearchTemplate失败");
return new ElasticsearchTemplate(client());
}
}
}
@EnableElasticsearchRepositories注解的basePackages填写我们的dao层路径
3.创建Article实体类
@Data
@ToString
@Document(indexName = "blog",type = "article")
public class Article {
/**
* 主键ID
*/
@Field(type = FieldType.Keyword)
private String id;
/**
* 文章标题
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word",searchAnalyzer = "ik_max_word")
private String title;
/**
* 文章内容
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word",searchAnalyzer = "ik_max_word")
private String content;
/**
* 创建时间
*/
@Field(type = FieldType.Date,pattern = "yyyy-MM-dd HH:mm:ss",format = DateFormat.custom)
private Date createTime;
}
关于上面类中使用的相关spring-data-elasticsearch注解的解释:
@Document 代表在定义ES中的文档document
- indexName 索引名称,一般为全小写字母,可以看成是数据库名称
- type 类型,可以看成是数据库表名
- useServerConfiguration 是否使用系统配置
- shards 集群模式下分片存储,默认分5片
- replicas 数据复制几份,默认1份
- refreshInterval 多久刷新数据,默认1s
- indexStoreType 索引存储模式,默认FS
- createIndex 是否创建索引,默认True,代表不存在indexName对应索引时,自动创建
@Field 文档中的字段类型,对应的是ES中document的Mappings概念,是在设置字段类型
- type 字段类型,默认按照java类型进行推断,也可以手动指定,通过FieldType枚举
- index 是否为每个字段创建倒排索引,默认true,如果不想通过某个field的关键字来查询到文档,设置为false即可
- pattern 用在日期上类型字段上 format = DateFormat.custom, pattern = “yyyy-MM-dd HH:mm:ss:SSS”
- searchAnalyzer 指定搜索的分词,ik分词只有ik_smart(粗粒度)和ik_max_word(细粒度)两个模式,具体差异大家可以去ik官网查看
- analyzer 指定索引时的分词器,ik分词器有ik_smart和ik_max_word
- store 是否存储到文档的_sourch字段中,默认false情况下不存储
4. 继承ElasticsearchRepository
和JPA类似继承ElasticsearchRepository,我们就可以直接使用自动生成的方法
package com.example.demo.dao;
import com.example.demo.entity.Article;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface ArticleRepository extends ElasticsearchRepository<Article, String> {
}
ElasticsearchRepository的源码如下:
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package org.springframework.data.repository;
import java.util.Optional;
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S var1);
<S extends T> Iterable<S> saveAll(Iterable<S> var1);
Optional<T> findById(ID var1);
boolean existsById(ID var1);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> var1);
long count();
void deleteById(ID var1);
void delete(T var1);
void deleteAll(Iterable<? extends T> var1);
void deleteAll();
}
4. 创建Test类进行测试
package com.example.demo;
import com.example.demo.dao.ArticleRepository;
import com.example.demo.entity.Article;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.index.query.CommonTermsQueryBuilder;
import org.elasticsearch.index.query.MatchPhraseQueryBuilder;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Date;
import java.util.Iterator;
import java.util.Optional;
import java.util.UUID;
@Slf4j
@SpringBootTest
public class ESTest {
@Autowired
private ArticleRepository articleRepository;
/**
* 存储文章到es中
*/
@Test
void saveArticle() {
String title = "谷歌是如何做Code Review的";
String content = "Code Review的主要目的是始终保证随着时间的推移,谷歌代码越来越健康,所有Code Review的工具和流程也是针对于此设计的。";
Article article = createArticle(title, content);
articleRepository.save(article);
System.out.println(article.getId());
title = "iOS 13大更新曝光:苹果手机或要调整位置权限";
content ="据外媒报道称,苹果正在对iOS 13系统进行调整,主要是修复之前出现的Bug,并且还打算iOS 13的位置权限设置进行调整,因为这个细节,他们正在接受反垄断调查。";
Article article2 = createArticle(title,content);
articleRepository.save(article2);
System.out.println(article2.getId());
title = "日媒:中国手机为何在东南亚受欢迎?";
content ="人类可能地球上是最不珍惜粮食的物种之一,根据全球农业与食品营养问题委员会的统计数据,全球每年食物浪费总量达到 13 亿吨,其中超过一半的水果和蔬菜被浪费。";
Article article3 = createArticle(title,content);
articleRepository.save(article3);
System.out.println(article3.getId());
}
public static Article createArticle(String title,String content){
//UUID模拟ID
UUID uuid = UUID.randomUUID();
String id = uuid.toString();
//创建Article
Article article = new Article();
article.setId(id);
article.setTitle(title);
article.setContent(content);
article.setCreateTime(new Date());
return article;
}
/**
* 根据Id查询
*/
@Test
void findArticleById() {
Optional<Article> articleDaoById = articleRepository.findById("14acc2a9-8c2b-49fc-9206-3f17d3c99a46");
System.out.println(articleDaoById.get());
}
/**
* 根据关键字在文章title中进行搜索
* 分词
*/
@Test
void findArticleByTitle() {
String titleKeyWord = "谷歌中国";
//matchQuery 会对关键字分词后进行搜索:谷歌中国---> 谷歌 中国
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", titleKeyWord);
QueryBuilders.commonTermsQuery("title","谷歌中国");
Iterable<Article> search = articleRepository.search(matchQueryBuilder);
Iterator<Article> iterator = search.iterator();
while (iterator.hasNext()){
Article next = iterator.next();
System.out.println(next);
}
}
/**
* 根据关键字在文章title中进行搜索
* 全匹配
*/
@Test
void findArticleByTitle2() {
String titleKeyWord = "谷歌中国";
//matchPhraseQueryBuilder 对关键字不进行分词,全匹配查询
MatchPhraseQueryBuilder matchPhraseQueryBuilder = QueryBuilders.matchPhraseQuery("title", titleKeyWord);
Iterable<Article> search = articleRepository.search(matchPhraseQueryBuilder);
Iterator<Article> iterator = search.iterator();
while (iterator.hasNext()){
Article next = iterator.next();
System.out.println(next);
}
}
/**
* 根据关键字在文章title中进行搜索
* 分页+排序
* es应尽量避免深层分页
*/
@Test
void findArticleByTitlePage() {
Sort createTime = Sort.by("createTime").ascending();
Pageable pageable = PageRequest.of(0,1,createTime);
String titleKeyWord = "谷歌中国";
//matchQuery 会对关键字分词后进行搜索:谷歌中国---> 谷歌 中国
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", titleKeyWord);
QueryBuilders.commonTermsQuery("title","谷歌中国");
Iterable<Article> search = articleRepository.search(matchQueryBuilder,pageable);
Iterator<Article> iterator = search.iterator();
while (iterator.hasNext()){
Article next = iterator.next();
System.out.println(next);
}
}
/**
* 删除所有
*/
@Test
void deleteAllArticle() {
articleRepository.deleteAll();
}
}
QueryBuilders有很多用法,篇幅限制,这里不再赘述。
四、总结
本文演示的是Elasticsearch最基本的用法,关于Elasticsearch的知识还有很多,比如如何重建索引、倒排序的原理,分词器,性能优化等等。接下来的文章里会像大家依次介绍。码字不易,有用记得关注点赞哟~