手动部署安装ceph-fs
手动部署安装ceph-fs
1.手动安装ceph
环境:类centos系统
ceph版本:ceph-luminous-14.2.2
这里yum源使用的是系统默认的。
1.主机名
hostnamectl set-hostname ceph-node1
hostnamectl set-hostname ceph-node2
hostnamectl set-hostname ceph-node3
hostnamectl set-hostname admin
2.关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
3.关闭selinux
sed -i 's/=enforcing/=disabled/' /etc/selinux/config
4.设置时区
timedatectl set-timezone Asia/Shanghai
5.设备列表
cat /etc/hosts
192.168.56.103 ceph-node1
192.168.56.102 ceph-node2
192.168.56.101 ceph-node3
6.时钟同步
yum -y install chrony
vi /etc/chrony.conf
server ntp1.aliyun.com iburst
server 0.centos.pool.ntp.org iburst
allow 10.1.1.0/24
systemctl restart chronyd
chronyc sources
7.配置免密
ssh-keygen
ssh-copy-id ceph-node1
ssh-copy-id ceph-node2
ssh-copy-id ceph-node3
ssh-copy-id admin
8.配置ceph镜像
vim /etc/yum.repos.d/ceph.repo
[ceph]
name=Ceph packages for $basearch
baseurl=https://download.ceph.com/rpm-nautilus/el7/x86_64/
enabled=1
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-noarch]
name=Ceph noarch packages
baseurl=https://download.ceph.com/rpm-nautilus/el7/noarch
enabled=1
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=https://download.ceph.com/rpm-nautilus/el7/x86_64/SRPMS
enabled=0
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
9.安装ceph依赖
yum install -y yum-utils && yum-config-manager --add-repo https://dl.fedoraproject.org/pub/epel/7/x86_64/ && yum install --nogpgcheck -y epel-release && rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 && rm -f /etc/yum.repos.d/dl.fedoraproject.org*
10.安装ceph软件包
yum -y install ceph ceph-radosgw
11.查看ceph版本
ceph-v
12.查看磁盘情况
df -h
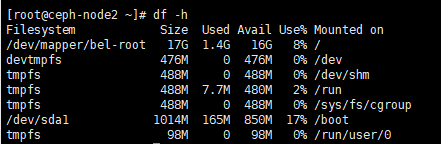
sda1为系统盘
/dev/mapper/vg_localhost-lv_root里面包含了很多系统文件,我们不能直接使用这个盘作为osd盘。
我们需要新增磁盘新建分区,划分出新的分区sdb作为osd盘。
如果是生产环境的话 也需要使用没使用过的独立分区来作为osd盘最好。
新建分区参考链接:(生产环境谨慎操作,如果划分区弄到相关系统文件等系统就启动不了了)
VMware虚拟机添加新硬盘以及对磁盘进行分区挂载:https://blog.csdn.net/zzq900503/article/details/80322220
2.部署mon
2.1安装ceph软件包(a为节点名称,可对应更改)
1.随机生成集群标识ID
# uuidgen
2.d8186da5-b1d3-44de-8b63-9231febf8755
再在ceph1节点创建auth和mon map:
# ceph-authtool /tmp/mon-a.keyring --create-keyring --gen-key -n mon. --cap mon ‘allow *’
# ceph-authtool /etc/ceph/ceph.client.admin.keyring --create-keyring --gen-key -n client.admin --set-uid=0 --cap mon ‘allow *’ --cap osd ‘allow *’ --cap mds ‘allow *’
# ceph-authtool /tmp/mon-a.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring
# monmaptool --create --clobber --add a 192.168.137.6:6789 --fsid d8186da5-b1d3-44de-8b63-9231febf8755 /tmp/mon-a.map
- 其次创建目录和添加该mon:
# mkdir -p /var/lib/ceph/mon/ceph-a
# ceph-mon -i a --mkfs --monmap /tmp/mon-a.map --keyring /tmp/mon-a.keyring(先有配置文件后才能运行)
- 设置本机ceph目录权限:
# chown -R ceph.ceph /var/lib/ceph
# chown -R ceph.ceph /var/log/ceph
# chown -R ceph.ceph /var/run/ceph
5.编辑配置文件/etc/ceph/ceph.conf:
[global]
fsid = d8186da5-b1d3-44de-8b63-9231febf8755 //之前取得的随机值
auth cluster required = none
auth service required = none
auth client required = none
filestore_max_xattr_value_size_other = 65536
[mon]
[mon.a]
host = ceph1
mon addr = 192.168.137.6:6789
- 启动该mon:
# systemctl daemon-reload
# systemctl enable ceph-mon@a
# systemctl start ceph-mon@a
最后添加校验:
- ceph auth import -i /tmp/mon-a.keyring
i. 在其他节点添加其他MON
(mon每个主机最多存在一个,mon总数量推荐为2n+1奇数个,以下以ceph2 mon.b举例)
- 创建work目录# mkdir -p /var/lib/ceph/mon/ceph-b
2.修改ceph1上的配置文件,完成后连同keyring一起同步到新主机(ceph2):
在mon section下添加:
[mon.b]
host = ceph2
mon addr = 192.168.137.7:6789
3.通过配置文件与第一个mon交互直接获取分配的auth和map创建mon:
# ceph auth get mon. -o /tmp/mon-b.keyring
# ceph mon getmap -o /tmp/mon-b.map
# ceph-mon -i b --mkfs --monmap /tmp/mon-b.map --keyring /tmp/mon-b.keyring
4.同理设置本机ceph目录权限:
# chown -R ceph.ceph /var/lib/ceph
# chown -R ceph.ceph /var/log/ceph
# chown -R ceph.ceph /var/run/ceph
5.启动该mon:
# systemctl daemon-reload
# systemctl enable ceph-mon@b
# systemctl start ceph-mon@b
ii. 结构图示
如前述配置用例配置完成ceph1-3的mon.a-c后,视图如下:[外链图片转存失败(img-eELvoDNC-1564134624956)(file:///C:/Users/admin/AppData/Local/Temp/msohtmlclip1/01/clip_image001.png)]
监控集群mon状态:
[root@ceph3 ~]# ceph mon stat
e3: 3 mons at {a=192.168.137.6:6789/0,b=192.168.137.7:6789/0,c=192.168.137.8:6789/0}, election epoch 6, quorum 0,1,2 a,b,c
2.部署osd基于bluestore
vim /etc/ceph/ceph.conf
[global]
fsid = 8c53e77b-6e33-43e9-9860-ac8655f559fe
auth cluster required = none
auth service required = none
auth client required = none
enable experimental unrecoverable data corrupting features = bluestore rocksdb
#filestore_max_xattr_value_size_other = 65536
[mon]
[mon.ceph-node1]
host = ceph-node1
mon addr = 192.168.56.102
[mon.ceph-node2]
host = ceph-node2
mon addr = 192.168.56.103
[mon.ceph-node3]
host = ceph-node3
mon addr = 192.168.56.101
[osd]
[osd.0]
host = ceph-node1
bluestore block db path =/dev/sdb1
bluestore block wal path =/dev/sdb2
bluestore block path = /dev/sdb3
[osd.1]
host = ceph-node1
bluestore block db path =/dev/sdc1
bluestore block wal path =/dev/sdc2
bluestore block path = /dev/sdc3
一、对磁盘进行分区操作(我加的磁盘一般是10G)
parted /dev/sdb -s mklabel gpt
parted /dev/sdb -s mkpart primary 1G 4G
parted /dev/sdb -s mkpart primary 4G 7G
parted /dev/sdb -s mkpart primary 7G 10G
parted /dev/sdc -s mklabel gpt
parted /dev/sdc -s mkpart primary 1G 4G
parted /dev/sdc -s mkpart primary 4G 7G
parted /dev/sdc -s mkpart primary 7G 10G
二、 将主机节点加入crush map
(如前述配置至default root下,default root 默认使用crush ruleset 0)
# ceph osd crush add-bucket ceph-node1 host
# ceph osd crush move ceph-node1 root=default
都配置完成后查看tree如下:
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0 root default
-2 0 host ceph1
-3 0 host ceph2
-4 0 host ceph3
示意图如下:
[外链图片转存失败(img-QYQefWaw-1564134624957)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\1563954710011.png)]
三,单个节点配置
1.获得一个osdid(根据集群现有osd一般从0开始使用)
ceph osd create
0
2.添加至crush表:
ceph osd crush add osd.0 1.0 host=ceph-node1
3.创建work目录:
mkdir -p /var/lib/ceph/osd/ceph-0
4.挂载osd的元数据
mount /dev/sdb1 /var/lib/ceph/osd/ceph-0
5.把osd元数据里的keying去mon里校验
ceph auth add osd.1 osd 'allow *' mon 'allow profile osd' -i/var/lib/ceph/osd/ceph-1/keyring
6.osd目录初始化(5-6可能需要交互一下)
ceph-osd -i 1 --mkfs --mkkey
7.启动OSD
ceph-osd -i 0
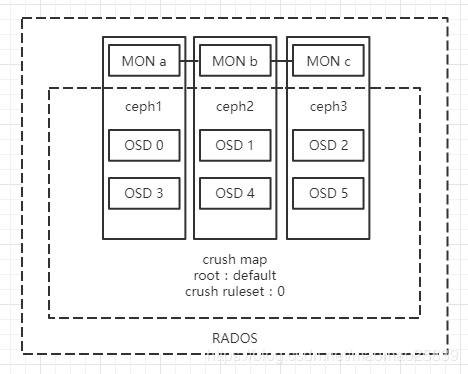
8.结构图示
添加完本例所有osd后,查看tree:
[root@ceph1 cephadm-dev]# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 6.00000 root default
-2 2.00000 host ceph1
0 1.00000 osd.0 up 1.00000 1.00000
3 1.00000 osd.3 up 1.00000 1.00000
-3 2.00000 host ceph2
1 1.00000 osd.1 up 1.00000 1.00000
4 1.00000 osd.4 up 1.00000 1.00000
-4 2.00000 host ceph3
2 1.00000 osd.2 up 1.00000 1.00000
5 1.00000 osd.5 up 1.00000 1.00000
示意图如下:
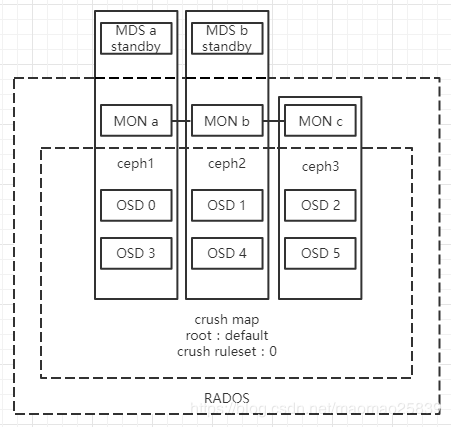
四、部署MDS
- 创建work目录:
# mkdir -p /var/lib/ceph/mds/ceph-a
2.修改并同步config文件:
[mds]
[mds.a]
host = ceph-node1
3.创建auth关系:
ceph --name client.admin --keyring /etc/ceph/ceph.client.admin.keyring auth get-or-create mds.node1 osd 'allow rwx' mds 'allow' mon 'allow profile mds' -o /var/lib/ceph/mds/ceph-node1/keyring
4.设置三个目录owner(不赘述,同一台host只需设置一次)
- 启动mds:
# systemctl daemon-reload
# systemctl enable ceph-mds@node1
# systemctl start ceph-mds@node1
添加完所有mds后示意图如下:
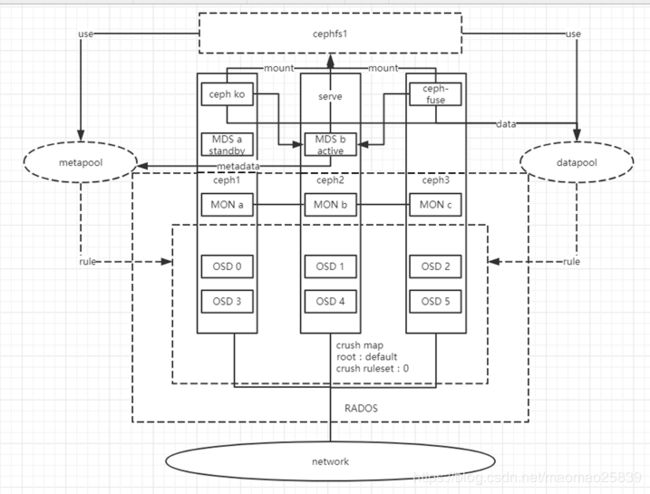
五、部署CEPH FS
i. 创建资源池
(本例中meta及data pool皆使用默认replica 3形式,crush ruleset 0)
# ceph osd pool create metapool 64 64
# ceph osd pool create datapool 64 64
(64为pg数)
示意图如下:

ii. 创建CEPH FILE SYSTEM
# ceph fs new cephfs1 metapool datapool
new fs with metadata pool 1 and data pool 2
查看mds状态:
[root@ceph1 cephadm-dev]# ceph mds stat
e6: 1/1/1 up {0=b=up:active}, 1 up:standby
mds.b已经成为active状态。
示意图如下:

六、创建客户端
1.挂载kernel client:
# mkdir /mnt/mycephfs1
# mount -t ceph 192.168.137.6:6789:/ /mnt/cephfs1 -o name=admin, secret=
或者,设置开机挂载
172.16.70.77:6789:/ /mnt/cephfs1 ceph name=admin,secretfile=/etc/ceph/secret.key,noatime,_netdev 0 2
# ceph-fuse -m 192.168.137.6:6789,192.168.137.7,192.168.137.8 /mnt/cephfs1
2019-07-24 17:28:54.529 7ff070f1ae00 -1 init, newargv = 0x556e7126f110 newargc=7
ceph-fuse[4498]: starting fuse
2.最终结构示意图:
七、ceph源码的分析方法
(摘自:https://blog.csdn.net/a1454927420/article/details/72412278)
1,lttng可以查看IO执行的流程,关于lttng的用法以后会有详解
2,通过lttng分析了大概流程后,可以通过gdb,分析具体细节的流程,gdb的bt命令可以很方便的查看调用关系。
3,通过netstat , tcpdump等网络工具可以配合分析网络层的源码
4,打开日志最高权限20,可以通过日志查看ceph逻辑的执行流程
5,通过admin-socket可以查看ceph各模块经过多少IO了,哪些队列有IO滞留,可以分析性能的瓶颈。