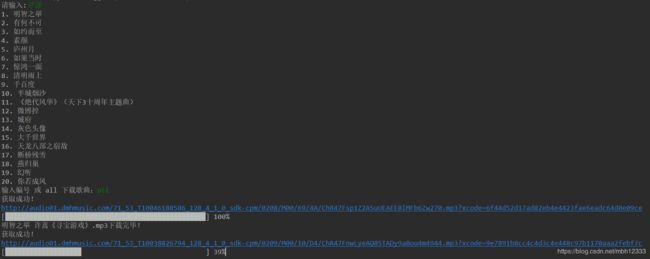
Python实现 百度音乐(千千音乐)音乐批量下载
import html
import json
import re
import requests
from novel.novel.progress import download
# from novel.novel.dam import download
def down_song(song_id):
song_url = 'http://play.taihe.com/data/music/songlink'
song_param = {
'songIds': song_id,
'hq': '0',
'type': 'm4a,mp3',
'rate': '',
'pt': '0',
'flag': '-1',
's2p': '-1',
'prerate': '-1',
'bwt': '-1',
'dur': '-1',
'bat': '-1',
'bp': '-1',
'pos': '-1',
'auto': '-1'
}
song_json = requests.post(song_url, data=song_param).json()
if song_json['errorCode'] == 22000:
print('获取成功!')
data = song_json['data']['songList'][0]
song_file_name = '%s %s' % (data['songName'], data['artistName'])
if data['albumName'] != None and len(data['albumName']) > 0:
song_file_name += '《%s》' % data['albumName']
song_file_name += '.%s' % data['format']
file = r'D:\\%s' % song_file_name
song_link = data['songLink']
print(song_link)
if len(song_link) > 0:
download(song_link, file)
print(song_file_name + "下载完毕!")
else:
print('下载失败!')
else:
print('获取失败!')
search_url = 'http://music.taihe.com/search'
search_param = {
'key': input('请输入:').strip()
}
search_content = requests.get(search_url, params=search_param).content.decode(encoding='utf-8', errors='ignore')
songs = []
regx_song_items = re.findall(r"data-songitem\s*=\s*'.+?'", search_content)
for song_item in regx_song_items:
item = json.loads(html.unescape(re.sub(r"data-songitem\s*=\s*'", '', song_item)[:-1]))
songs.append({'id': item['songItem']['sid'], 'name': item['songItem']['sname']})
if len(songs) > 0:
for song in songs:
print('%s. %s' % (str(songs.index(song) + 1), song['name']))
song_index = input('输入编号 或 all 下载歌曲:')
if song_index == 'all':
for song in songs:
down_song(song['id'])
elif song_index == 'exit':
exit(0)
else:
down_song(songs[int(song_index) - 1]['id'])
else:
print('无结果!')
下面代码是下载,可以用自己的
import sys
import requests
# 屏蔽warning信息,因为下面verify=False会报警告信息
requests.packages.urllib3.disable_warnings()
def download(url, file_path):
headers = {
'Range': 'bytes=0-',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36'
}
# verify=False 这一句是为了有的网站证书问题,为True会报错
r = requests.get(url, headers=headers, stream=True, verify=False)
# 既然要实现下载进度,那就要知道你文件大小啊,下面这句就是得到总大小
total_size = int(r.headers['Content-Length'])
temp_size = 0
with open(file_path, "wb") as f:
# iter_content()函数就是得到文件的内容,
# 有些人下载文件很大怎么办,内存都装不下怎么办?
# 那就要指定chunk_size=1024,大小自己设置,
# 意思是下载一点写一点到磁盘。
for chunk in r.iter_content(chunk_size=2048):
if chunk:
temp_size += len(chunk)
f.write(chunk)
f.flush()
#############花哨的下载进度部分###############
done = int(50 * temp_size / total_size)
# 调用标准输出刷新命令行,看到\r回车符了吧
# 相当于把每一行重新刷新一遍
sys.stdout.write("\r[%s%s] %d%%" % ('█' * done, ' ' * (50 - done), 100 * temp_size / total_size))
sys.stdout.flush()
print() # 避免上面\r 回车符,执行完后需要换行了,不然都在一行显示