kafka源码解析——kafka生产者模块
kafka消息队列主要由生产者(producer)、消费者(consumer)以及消息代理(broker)构成,生产者会源源不断地将消息写入消息代理,然后消费者从消息代理中拉取消息并消费。从功能划分上来看,生产者和消费者都属于客户端(client),消息代理属于服务端(server)。本文主要涉及kafka的生产者模块,从功能和底层原理两个方面对kafka生产的部分进行分析。
1.kakfa生产者的主要流程
首先看一下kafka生产者模块工作的主要流程,下面是流程图:
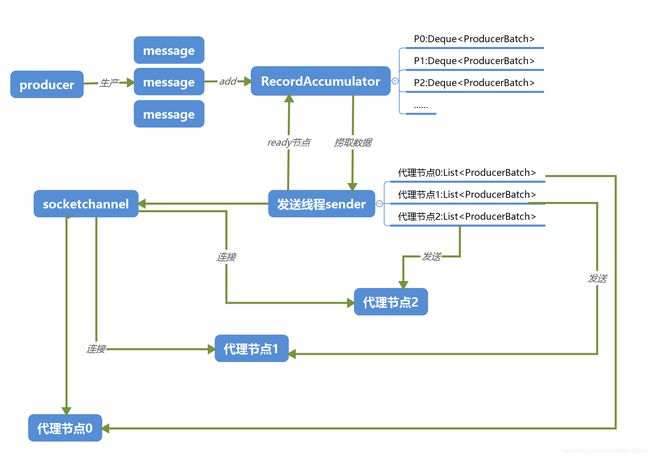
1.应用程序产生消息,调用kafkaproducer的send方法提交message;
2.为message选择一个分区,并将消息序列化;
3.将待发送的message收集到消息收集器RecordAccumulator中,RecordAccumulator中的记录按消息的分区进行划分,不同分区的消息插入不同的队列;
4.发送线程sender定期轮询,从消息收集器中捞出已经准备好的代理节点,并和代理节点建立连接;
5.发送线程sender从消息收集器中捞出发送往建立连接的代理节点的分区批记录,并将这些分区批记录按目标节点划分,发送往同一个代理节点的批记录发送同一个list中,最后构建ClientRequest请求将list中的批记录发送到对应的代理节点上。
下面我们将每一步展开来看里面具体实现的细节。
2.消息发送
应用程序在生产消息,并调用kafkaProducer的send方法时,需要先将消息封装成ProducerRecord,然后再将ProducerRecord传入send方法中。我们首先来看一下ProducerRecord中有些什么:
public class ProducerRecord {
private final String topic;
private final Integer partition;
private final Headers headers;
private final K key;
private final V value;
private final Long timestamp;
省略……
}
ProducerRecrod中的主要参数字段如上面的代码所示,topic字段表示该消息需要发送到哪个主题,partition表示消息需要发送的主题的分区,
这里简单介绍以下分区的概念,分区是对主题的一种划分,用户可以对每个主题指定1至多个分区,生产者产生的消息会被发送到唯一的一个分区中,而消费组可以订阅主题,对每个消费组而言,这个消费组都会消费这个主题的所有分区,但每个分区只会被消费组中的唯一一个消费者消费。
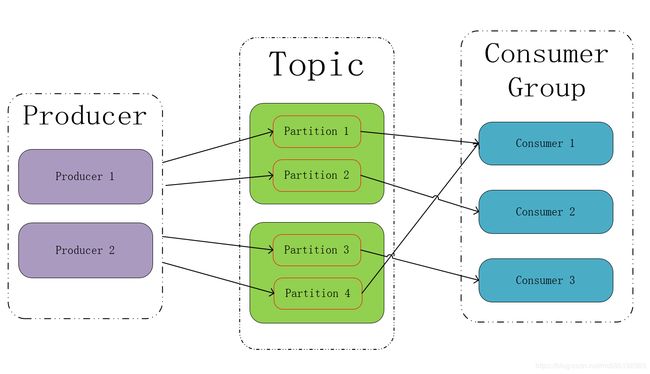
在上图中有两个消费者往主题Topic发送消息,Topic一共有4个分区,分布在两个节点上,有一个消费分组订阅了该主题,消费分组中共有三个消费者。消费者生产的消息会均衡的分布到Topic的四个分区上,每个分区上的消息都不会重复,同时消费分组会消费来自Topic中的所有分区的消息,当对某个分区而言,它只会被消费组中的一个消费者线程消费,例如上图中,P1和P4被分配给Consumer1,P2被分配给Consumer2,P3被分配给Consumer3,他们会一直以这种分配形式进行消费直到触发Rebalance操作。
消息是没有key这个概念的,这里的key主要是用来做均衡字段的,如果没有指定key和partition字段,kafka会采用round-robin方式来将消息均衡的发送到不同的分区;而如果用户指定了partition的值,则就发送到该partition对应的分区主节点;如果用户没有指定partition而指定了key字段,则对key进行散列化,然后将散列化的值与分区的数量进行取模运算,取模运算的结果就是消息需要发往的分区号。
private int partition(ProducerRecord record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
return partition != null ?
partition :
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
上面的代码是用于计算消息需要发送的分区号的,我们可以看出,如果用户指定了partition就直接用这个指定的分区号,如果没有指定,则会调用partitioner.partition方法计算分区号,我们来看一下这个分区算法的细节:
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
//获取指定主题的所有分区
List partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
//如果没有指定key,则调用nextValue方法获取topic的下一个自增数,并通过这个自增数同分区总数取余得到对应的分区号
int nextValue = nextValue(topic);
List availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// 如果指定了key则通过key的散列化值与分区总数取余计算得到分区号
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
上面的PartitionInfo对象表示一个分区的分布信息,PartitionInfo的主要成员变量如下:
public class PartitionInfo {
private final String topic; //主题名称
private final int partition;//分区编号
private final Node leader;//分区的主副本节点
private final Node[] replicas;//分区的所有副本节点
private final Node[] inSyncReplicas;
private final Node[] offlineReplicas;
以下省略……
}
PartitionInfo中包含了主题名称、分区编号、分区主副本节点等重要信息,有了这些重要信息kafkaProducer就可以确定消息需要被发送到哪个主题的哪个分区节点了。
在知道消息发往的分区节点之后,send方法进行了如下的操作:
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
tp = new TopicPartition(record.topic(), partition);
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
this.sender.wakeup();
}
return result.future;从代码中我们可以看出,send方法将key和value序列化之后将消息添加到RecordAccumulator中,然后判断RecordAccumulator的状态,如果已经装满了,则唤醒sender线程。也就是说,在kafkaProducer.send方法中,其实是没有真正发送的,只是将消息添加到RecordAccumulator,然后等待sender线程来执行这个发送。
3.消息收集器
在上一节中我们提到kafkaProducer只是将消息缓存到RecordAccumulator中,然后判断批记录是否已经存满了来触发发送线程Sender执行发送操作。

生产者在发送消息时会按照上一节中分配到的分区添加到队列中,添加消息时首先根据入参的分区获取分区所属的队列,然后从队列中取出最后一个批记录(上图中的recordBatch,黄色表示已经填充的部分),如果队列中没有批记录或者取出来的批记录已经存满了,则创建一个新的recordBatch添加到队列中,并加入队尾。
将消息添加到RecordAccumulator中的主要代码如下:
//根据主题分区信息获取队列
Deque dq = getOrCreateDeque(tp);
synchronized (dq) {
//尝试将消息添加到队列中
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}
//添加失败,创建新的批记录
buffer = free.allocate(size, maxTimeToBlock);
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
在添加消息时,第一步是取出分区对应的队列,然后尝试先队列中的最后一个批记录中添加消息,如果添加失败,tryAppend方法会返回null,表明队列为空或者队列中最后一个批记录已经存满,无法容纳这条消息。然后给buffer分配空间,创建新的批记录对象,并将这条消息添加到新的批记录中,最后将这个批记录对象添加到dq的尾部。如果在成功往旧的批记录对象添加消息成功后,会返回
return new RecordAppendResult(future, deque.size() > 1 || last.isFull(), false);
public RecordAppendResult(FutureRecordMetadata future, boolean batchIsFull, boolean newBatchCreated) {
this.future = future;
this.batchIsFull = batchIsFull;
this.newBatchCreated = newBatchCreated;
}
RecordAppendResult的第二个参数表示表示该队列是否装满,我们可以看出,当队列中的对象数大于1或者队尾批记录装满时,这个参数为true,在kafkaProducer的send方法中:
if (result.batchIsFull || result.newBatchCreated) {
this.sender.wakeup();
}
如果RecordAppendResult返回批记录已满,则会唤醒发送线程Sender,通过这个线程来完成消息的发送。
4.发送线程Sender
由于在往RecordAccumulator添加消息的时候已经按照分区来进行分组,因此,在发送线程发送消息时,属于同一个分区队列的消息是一起发的。每个分区都对应一个代理节点,但是如果分区数多的情况下,多个分区可能会对应同一个代理节点,如果一个一个发送的话,会引起较大的网络开销,kafka在这里也进行了优化,它在发送前会先将代理节点相同的分区的批记录集合起来,一次性发送出去,这样就可以节省大量的网络开销资源。发送情况如图所示:

图中生产者的消息被均衡的分布到4个分区中,而P1和P3的主副本节点是代理节点1,P2和P4的主副本节点是代理节点2,因此,sender线程中将属于同一个代理节点的批记录聚合起来发送,原本需要发送四次网络请求,现在只需要发送两次请求即可。
下面我们来看一下sender线程中发送消息的具体实现:
//获取集群的信息,包括了代理节点、主副本节点等关键信息
Cluster cluster = metadata.fetch();
//获取准备发送的分区(存在主副本节点)
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
//对那些没有找到主副本节点的分区,发起主题分区元数据请求
if (!result.unknownLeaderTopics.isEmpty()) {
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
this.metadata.requestUpdate();
}
//建立到主副本节点的连接,如果还没有准备好,则移除这个节点
Iterator iter = result.readyNodes.iterator();
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.connectionDelay(node, now));
}
}
//读取记录收集器,返回的是每个主副本节点和与之对应的批记录列表
Map> batches = this.accumulator.drain(cluster, result.readyNodes,
this.maxRequestSize, now);
sendProduceRequests(batches, now);
private void sendProduceRequests(Map> collated, long now) {
//以代理节点为级别进行发送
for (Map.Entry> entry : collated.entrySet())
sendProduceRequest(now, entry.getKey(), acks, requestTimeout, entry.getValue());
}
//对每个节点构建ClientRequest请求,并将请求放队列中等待发送
private void sendProduceRequest(long now, int destination, short acks, int timeout, List batches) {
Map produceRecordsByPartition = new HashMap<>(batches.size());
final Map recordsByPartition = new HashMap<>(batches.size());
for (ProducerBatch batch : batches) {
TopicPartition tp = batch.topicPartition;
MemoryRecords records = batch.records();
if (!records.hasMatchingMagic(minUsedMagic))
records = batch.records().downConvert(minUsedMagic, 0, time).records();
produceRecordsByPartition.put(tp, records);
recordsByPartition.put(tp, batch);
}
//构建请求必须的参数
ProduceRequest.Builder requestBuilder = ProduceRequest.Builder.forMagic(minUsedMagic, acks, timeout,
produceRecordsByPartition, transactionalId);
//构建回调处理函数
RequestCompletionHandler callback = new RequestCompletionHandler() {
public void onComplete(ClientResponse response) {
handleProduceResponse(response, recordsByPartition, time.milliseconds());
}
};
String nodeId = Integer.toString(destination);
//构建ClientRequest请求
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0, callback);
//加入待发送队列
client.send(clientRequest, now);
log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
}
这里总结一下发送线程Sender做的一些工作:
- 迭代消息收集器中的每个分区,找出那些存在主副本节点的分区
- 对那些没有找到主副本节点的分区,发送获取元数据请求(下一轮执行中才能得到)
- 尝试对每个主副本节点建立连接,移除那些没有做好准备的主副本节点
- 将消息收集器中的批记录,以主副本节点为维度进行分组,得到Map
- 迭代上述数据结构的key,对每个主副本节点构建ClientRequest请求,并将请求加入带发送队列中,最后调用客户端网络对象将请求发送出去
5.客户端网络对象
在上一节发送线程Sender中,并没有真正的将消息发送出去,没错,它还是没有真正的发送出去,只是将消息构建ClientRequest请求加入到队列中,然后交给客户端网络线程处理。在Sender的run方法中用到了客户端网络对象的三个方法,分别是ready()、send()和poll()方法。
下面是sender中用到上述三个方法的地方:
//遍历从收集器中拿到的已经准备好的节点,并尝试连接,将那些连接失败的节点移除
Iterator iter = result.readyNodes.iterator();
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
}
}
//为每个代理节点构建一个ClientRequest请求,并通过客户端网路对象的send方法将ClientRequest请求存到发送队列中
String nodeId = Integer.toString(destination);
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0, callback);
client.send(clientRequest, now);
//调用client的poll方法间接地调用选择器将请求发送给节点
client.poll(pollTimeout, now);
下面我们来仔细看一下这三个部分
5.1建立连接
建立连接的过程主要在客户端网络对象的ready方法中完成,他对消息收集器中已经准备好的节点尝试建立连接,并将失败的节点移除出去,在后面的发送流程中就不会对该节点进行发送。ready方法的代码如下:
public boolean ready(Node node, long now) {
//已经连接成功返回true
if (isReady(node, now))
return true;
//允许连接但是还没有连接上,则初始化连接
if (connectionStates.canConnect(node.idString(), now))
initiateConnect(node, now);
//不允许连接
return false;
}
//当metaData不需要更新且当前节点可以发送请求表示连接已经准备好
public boolean isReady(Node node, long now) {
return !metadataUpdater.isUpdateDue(now) && canSendRequest(node.idString());
}
//当节点连接状态已经准备好,节点对应的连接器通道准备好且节点有数据要发送时表示当前节点可以发送请求
private boolean canSendRequest(String node) {
return connectionStates.isReady(node) && selector.isChannelReady(node) && inFlightRequests.canSendMore(node);
}
//初始化连接
private void initiateConnect(Node node, long now) {
String nodeConnectionId = node.idString();
//更新节点连接状态为连接中
this.connectionStates.connecting(nodeConnectionId, now);
//选择器连接到代理节点
selector.connect(nodeConnectionId,
new InetSocketAddress(node.host(), node.port()),
this.socketSendBuffer,
this.socketReceiveBuffer);
}
5.2 暂存请求
这个部分是由客户端对象的send方法完成的,这个方法比较简单,就是将客户端请求加入到inFlightRequests列表中,然后调用选择器的send将待发送的请求设置到对应的通道中去,具体的代码实现如下:
public void send(ClientRequest request){
//用于缓存还没有收到响应的客户端请求
this.inFlightRequests.add(inFlightRequest);
selector.send(inFlightRequest.send);
}
public void send(Send send) {
String connectionId = send.destination();
KafkaChannel channel = openOrClosingChannelOrFail(connectionId);
if (closingChannels.containsKey(connectionId)) {
this.failedSends.add(connectionId);
} else {
//将请求设置到通道中
channel.setSend(send);
}
}
5.3客户端轮询
最后一步是通过调用客户端网络对象的poll方法来间接地调用选择器的poll方法将请求发送出去,并且在发送请求之后通过多个处理方法来对发送请求和接受到的响应等进行处理。poll方法的主要代码如下:
public List poll(long timeout, long now) {
long metadataTimeout = metadataUpdater.maybeUpdate(now);
//轮询选择器的key,将请求发送出去
this.selector.poll(Utils.min(timeout, metadataTimeout, requestTimeoutMs));
long updatedNow = this.time.milliseconds();
List responses = new ArrayList<>();
//对发送进行处理,将需要响应的请求添加到responses中
handleCompletedSends(responses, updatedNow);
//对响应进行处理,根据接收到的响应更新相应列表
handleCompletedReceives(responses, updatedNow);
//选择器中断开的连接进行响应的断开处理
handleDisconnections(responses, updatedNow);
//对选择器中处于连接状态的节点进行连接处理
handleConnections();
//对需要获取ApiVersion信息的节点发送响应的请求
handleInitiateApiVersionRequests(updatedNow);
//对超时请求进行相应处理
handleTimedOutRequests(responses, updatedNow);
//响应回调处理
for (ClientResponse response : responses) {
response.onComplete();
}
return responses;
}
客户端有需要响应结果和不需要响应结果两种场景,两种响应场景的流程如下:
- 不需要响应:将客户端请求添加到队列->发送请求->从队列中删除请求->构造客户端响应
- 需要响应:将客户端请求添加到队列->发送请求->等待接受响应->接受完成的响应->从队列中删除请求->构造客户端响应
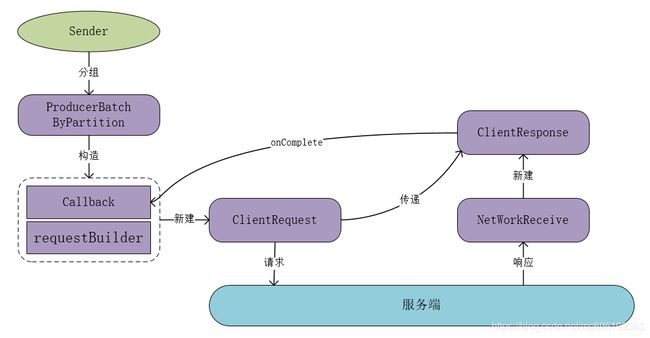
客户端响应(ClientResponse)需要从队列中获取客户端请求,客户端请求(ClientRequest)是客户端响应(ClientResponse)的一个成员变量,这么设计的原因是因为回调函数在客户端请求中,这样客户端响应就可以通过自己的成员变量来调用回调函数了。客户端请求和客户端响应的关系如下图所示:
6.选择器
在kafka中,真正与网络进行交互的是选择器Selctor,上节中提到了客户端网络对象的三个重要方法,ready、send和poll,分别实现了连接网络、添加发送对象以及轮询发送的功能。但实际上这三个方法都是调用了Selector来实现。
6.1网络连接
NetWorkClient.ready的调用链路是NetWorkClient.ready->NetWorkClient.initiateConnect->Selector.connect,ready方法是调用Select.connect方法来实现网络连接的。下面我们来看一下这个方法的实现:
public void connect(String id, InetSocketAddress address, int sendBufferSize, int receiveBufferSize) throws IOException {
SocketChannel socketChannel = SocketChannel.open();
socketChannel.configureBlocking(false);
Socket socket = socketChannel.socket();
//连接网络
connected = socketChannel.connect(address);
//注册到nio选择器,并返回选择键
SelectionKey key = socketChannel.register(nioSelector, SelectionKey.OP_CONNECT);
KafkaChannel channel = channelBuilder.buildChannel(id, key, maxReceiveSize, memoryPool);
key.attach(channel);
this.channels.put(id, channel);
}
public KafkaChannel buildChannel(String id, SelectionKey key, int maxReceiveSize, MemoryPool memoryPool) throws KafkaException {
//创建传输层,传输层TransportLayer中封装了SocketChannel
PlaintextTransportLayer transportLayer = new PlaintextTransportLayer(key);
PlaintextAuthenticator authenticator = new PlaintextAuthenticator(configs, transportLayer);
//将传输层封装到KafkaChannel中
return new KafkaChannel(id, transportLayer, authenticator, maxReceiveSize,
memoryPool != null ? memoryPool : MemoryPool.NONE);
}
从上面的代码中我们可以看到选择器的connect方法创建了客户端到服务器之间的网络连接,这个连接动作是通过Socketchannel来完成的,然后它将SocketChannel注册到了nioSelector上,通过选择键来与socketChannel关联。除此之外,为了更好的封装底层的一些操作,这里创建了KafkaChannel,将SocketChannel封装在传输层中,然后将传输层作为KafkaChannel的成员变量,这样KafkaChannel就间接的持有了SocketChannel,并通过key.attach(channel)将选择键与KafkaChannel关联起来。这样选择器在进行轮询操作时,就可以通过key.attachment来获取绑定到选择键上的KafkaChannel。同时它也将KafkaChannel和节点id放入到map中,方便根据代理节点来获取kafkaChannel。
6.2添加待发送的请求
第五节中提到发送者线程sender调用的networkClient.send方法并没有真正将请求发送出去而是创建了InFlightRequest对象放入队列中,并通过selector.send方法将需要发送的send对象放入kafkachannel中,我们先看一下kafkaChannel的成员变量:
private final String id;
//传输层,里面持有socketChannel
private final TransportLayer transportLayer;
private long networkThreadTimeNanos;
private final int maxReceiveSize;
private final MemoryPool memoryPool;
//用于存放响应
private NetworkReceive receive;
//存放待发送请求
private Send send;
//通道状态
private ChannelState state;
kafkaChannel持有了传输层对象、响应对象、待发送请求等,我们可以看到这里的send是一个单独的成员变量,不是队列也不是列表,表明每个kafkaChannel一次只能发送一次send请求。这里的send对象是怎么来的呢?我们来看一下selector的send方法就明白了:
public void send(Send send){
String connectionId = send.destination();
KafkaChannel channel = openOrClosingChannelOrFail(connectionId);
channel.setSend(send);
}
private KafkaChannel openOrClosingChannelOrFail(String id) {
KafkaChannel channel = this.channels.get(id);
if (channel == null)
channel = this.closingChannels.get(id);
if (channel == null)
channels.keySet());
return channel;
}
selector.send方法中通过节点的id找出代理节点对应的kafkaChannel,这里是通过6.1中提到的map来实现的,拿到kafkaChannel之后,将待发送的send对象设置进去,就完成了第二步的工作。
6.3真实的发送请求
在6.2中将发送完各个代理节点的请求set到对应代理节点的kafkaChannel中后,还要进行最后一步工作,调用networkClient的轮询方法poll,但networkClient的poll方法其实也没做什么事,它主要还是间接地调用selector的poll方法:
public List poll(long timeout,long now){
省略......
this.selector.poll(Utils.min(timeout, metadataTimeout, requestTimeoutMs));
省略......
}
public void poll(long timeout) throws IOException{
long startSelect = time.nanoseconds();
//获取准备好的选择键的数量
int numReadyKeys = select(timeout);
if (numReadyKeys > 0 || !immediatelyConnectedKeys.isEmpty() || dataInBuffers) {
//取出所有已经准备好的选择键
Set readyKeys = this.nioSelector.selectedKeys();
keysWithBufferedRead.removeAll(readyKeys); //so no channel gets polled twice
if (!keysWithBufferedRead.isEmpty()) {
Set toPoll = keysWithBufferedRead;
keysWithBufferedRead = new HashSet<>(); //poll() calls will repopulate if needed
pollSelectionKeys(toPoll, false, endSelect);
}
//遍历每个选择键并发送请求
pollSelectionKeys(readyKeys, false, endSelect);
pollSelectionKeys(immediatelyConnectedKeys, true, endSelect);
//清空处理完的选择键
readyKeys.clear();
}
}
void pollSelectionKeys(Set selectionKeys,boolean isImmediatelyConnected,long currentTimeNanos) {
Iterator iterator = determineHandlingOrder(selectionKeys).iterator();
//遍历每个准备好的选择键
while (iterator.hasNext()) {
//获取对应的kafkaChannel
SelectionKey key = iterator.next();
KafkaChannel channel = channel(key);
//发送前先读取响应,如果有响应则将服务端响应添加到队列中
if (channel.ready() && (key.isReadable()){
NetworkReceive networkReceive;
while ((networkReceive = channel.read()) != null) {
madeReadProgressLastPoll = true;
addToStagedReceives(channel, networkReceive);
}
}
//如果key是写状态,则调用kafkaChannel的写方法将send发送出去
if (channel.ready() && key.isWritable()) {
Send send = channel.write();
//发送成功则将结果添加到成功发送列表
if (send != null) {
this.completedSends.add(send);
}
}
}
}
简单介绍一下上面代码的功能,networkClient.poll调用selector的轮询方法poll,selector.poll从nioSelector中获取已经准备好的选择键,并遍历每个选择键。然后根据选择键获取与之关联的kafkaChannel对象,每个代理节点都对应唯一的kafkaChannel对象。根据选择键的状态来进行相应的处理,如果key上注册的是读事件,则从通道中读出服务端的响应并存储在队列中待networkClient.poll方法进行后续处理;如果key上注册的是写事件,则通过kafkaChannel将send请求发送出去,由于send对象和传输层对象都是kafkaChannel的成员变量,在kafkaChannel.write方法中,就是通过将send中的信息写入到传输层transport中来实现请求的发送。到这一步我们就将kafka消费者完成的主要工作都介绍了一遍。
最后我们在整体把从发送线程sender轮询到将请求发送出去这中间的流程梳理一遍,流程图如下:

- sender从消息收集器中捞取待发送消息,消息按照发送代理节点进行分组
- sender调用networdClient的ready方法对代理节点建立连接,连接方式是通过nio的方式进行连接,每个代理节点node建立一个socketChannel,并将socketChannel注册到nioSelector得到绑定键key
- 键socketChannel封装成传输层,并构建kafkaChannel对象,将传输层transportLayer作为KafkaChannel的成员变量
- networkClinet将客户端请求ClientRequest通过Selector转换成send,并将send设置为kafkaChannel的成员变量
- selector轮询所有准备好的选择键,根据选择键拿到绑定的kafkaChannel,并将成员变量send通过成员变量transportLayer间接地调用socketChannel将消息写入网络中发送出去,到这里就完成了生产者地整个发送流程。