python 日语转罗马音工具 pykakasi模块使用
翻译文章自:https://qiita.com/komorin0521/items/8cd1eb0cdb4a9ede217e
①下载模块:
pip install pykakasi
pip会自动把依赖库six和semidbm给装上
手动装也可以:
pip install six semidbm pip install pykakasi
模块主页:https://github.com/miurahr/pykakasi
②测试代码:
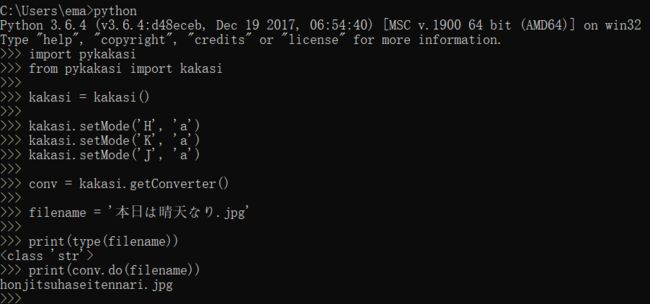
#!/usr/bin/env python3
# coding: utf-8
from pykakasi import kakasi
kakasi = kakasi()
kakasi.setMode('H', 'a')
kakasi.setMode('K', 'a')
kakasi.setMode('J', 'a')
conv = kakasi.getConverter()
filename = '本日は晴天なり.jpg'
print(type(filename))
print(conv.do(filename))③最终结果:
honjitsuhaseitennari.jpg
④效果截图:
⑤参数说明
These switch alphabets are derived from original Kakasi. Now it support following options:
| Option | Description | Values | Note |
|---|---|---|---|
| K | Katakana convertion | a,H,None | roman, Hiragana or noconversion |
| H | Hiragana convertion | a,K,None | roman, Katakana or noconversion |
| J | Kanji conversion | a,H,K,None | roman or Hiragana, Katakana or noconv |
| a | Roman conversion | E,None | JIS ROMAN or noconversion |
| E | JIS ROMAN conversion | a,None | ascii roman or noconversion |
Each character means character sets as follows:
Character Sets a: ascii j: jisroman g: graphic k: kana (j,k defined in jisx0201) E: kigou K: katakana H: hiragana J: kanji (E,K,H,J defined in jisx0208)
上面的参数说明很详细了,如果看不懂看下面的例子就一目了然:
from pykakasi import kakasi,wakati
text = u"かな漢字交じり文"
kakasi = kakasi()
kakasi.setMode("H","a") # Hiragana to ascii, default: no conversion
kakasi.setMode("K","a") # Katakana to ascii, default: no conversion
kakasi.setMode("J","a") # Japanese to ascii, default: no conversion
kakasi.setMode("r","Hepburn") # default: use Hepburn Roman table
kakasi.setMode("s", True) # add space, default: no separator
kakasi.setMode("C", True) # capitalize, default: no capitalize
conv = kakasi.getConverter()
result = conv.do(text)
print(result)
wakati = wakati()
conv = wakati.getConverter()
result = conv.do(text)
print(result)