搜索关键字爬取前程无忧职位信息,保存至csv文件,并进行数据清洗,可视化(数据清洗+可视化篇)
搜索关键字爬取前程无忧职位信息,保存至csv文件,并进行数据清洗,可视化(数据清洗+可视化篇)
- 二、 数据清洗+可视化篇
- 1.代码部分(pandas+pyecharts)
- 2.可视化结果
二、 数据清洗+可视化篇
1.代码部分(pandas+pyecharts)
以下代码包含数据清洗和可视化内容
(1)工资与学历关系:
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
#
# @Version : 1.0
# @Time : xxx
# @Author : xxx
# @File : 公司与学历关系.py
import pandas as pd
import re
df = pd.read_csv(r'.\爬虫数据(脏数据)\python招聘职位.csv', encoding='utf-8')
df1 = df.loc[:, [i for i in df.columns if i not in 'company+release_date+address+company_type']]
df2 = df1.dropna()
df3 = df2.iloc[:2000, :]
def wish(a): # 数据清洗自定义函数(udf)
a = a[0]
if '元/天' in a or '千以下/月' in a or '万以上/月' in a or '万以上/年' in a or '万以下/年' in a:
wage = re.findall('[.\d]+', a)
if '元/天' in a:
wage = float(wage[0])*30
elif '万以上/年' in a or '万以下/年' in a:
wage = round((float(wage[0])*10000) / 12, 0)
else:
wage = [float(i) * 1000 if '千' in a else float(i) * 10000 for i in wage][0]
return wage
else:
wages = re.findall('([.\d]+)-([.\d]+)', a)
if '千/月' in a or '万/月' in a:
wages = [((float(i[0]) + float(i[1])) / 2) * 1000 if '千' in a else ((float(i[0]) + float(i[1])) / 2) * 10000 for i in wages][0]
wage = wages
else:
wages = ((float(wages[0][0]) + float(wages[0][1])) / 2) * 10000
wage = round(wages / 12, 0)
return wage # 返回处理完的薪资
df3['wages'] = df3.loc[:, ['wages']].apply(wish, axis=1) # apply
index = df3.groupby(by=['education']).mean()['wages'].index.values # 获取学历分类
value = df3.groupby(by=['education']).mean()['wages'].values.tolist() # 获取各分类的值
value = [int(i) for i in value] # 去掉小数
from pyecharts import Bar
bar = Bar("工资与学历关系")
bar.add("", index, value, is_stack=True, mark_line=["average"], is_label_show=True)
bar.render("工资与学历关系.html")
(2)工作经验与薪资关系:
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
#
# @Version : 1.0
# @Time : xxx
# @Author : xxx
# @File : 工作经验与薪资关系图.py
import pandas as pd
from pyecharts import Bar, Line, Overlap
import re
df = pd.read_csv(r'.\爬虫数据(脏数据)\python招聘职位.csv', encoding='utf-8') # 读取爬虫数据
df1 = df.loc[:, [i for i in df.columns if i not in 'company+release_date+address+company_type']]
df2 = df1.dropna()
df3 = df2.iloc[:2000, :]
def wish(a): # 数据清洗自定义函数(udf)
a = a[0]
if '元/天' in a or '千以下/月' in a or '万以上/月' in a or '万以上/年' in a or '万以下/年' in a:
wage = re.findall('[.\d]+', a)
if '元/天' in a:
wage = float(wage[0])*30
elif '万以上/年' in a or '万以下/年' in a:
wage = round((float(wage[0])*10000) / 12, 0)
else:
wage = [float(i) * 1000 if '千' in a else float(i) * 10000 for i in wage][0]
return wage
else:
wages = re.findall('([.\d]+)-([.\d]+)', a)
if '千/月' in a or '万/月' in a:
wages = [((float(i[0]) + float(i[1])) / 2) * 1000 if '千' in a else ((float(i[0]) + float(i[1])) / 2) * 10000 for i in wages][0]
wage = wages
else:
wages = ((float(wages[0][0]) + float(wages[0][1])) / 2) * 10000
wage = round(wages / 12, 0)
return wage # 返回处理完的薪资
df3['wages'] = df3.loc[:, ['wages']].apply(wish, axis=1)
df4 = df3.groupby(by='work_experience').mean()[['wages']]
index = list(df4.index)
value = [int(i[0]) for i in df4.values.tolist()]
attr = [] # 这个列表在后面会作为后面画图的x轴标签
v1 = [] # 这个列表在后面会作为后面画图的y轴标签
# 下面这一段是对我们上面拿到的index和value,做一个对应排序,使可视化出呈现出好一些的效果
dic = {} # 用于存储index和value的对应元素作为键值对
for i in zip(index, value):
dic[i[0]] = i[1]
d_order = sorted(dic.items(), key=lambda x: x[1], reverse=False) # 使用sorted方法对字典的值进行排序,返回的结果是一个列表,包含多个二元列表
for i in d_order: # 使用for循环遍历d_order列表,取出对应值
attr.append(i[0])
v1.append(i[1])
# 下面进行可视化
bar = Bar("工作经验与薪资关系图") # 初始化柱状图对象,起个标题名字
bar.add("柱状图", attr, v1, is_stack=True, # 数据堆叠,同个类目轴上系列配置相同的 stack 值可以堆叠放置,这里开不开无所谓,有多个y轴就能看出效果
xaxis_name='工作经验', # 设置x轴名字
yaxis_name='平均薪资', # 设置y轴名字
yaxis_name_gap=55, # 设置y轴与轴线的距离
label_color=['#D15B8F'], # 设置柱状颜色,这里使用的是类似粉红色
is_xaxislabel_align=True, # 设置显示x轴标签
is_yaxislabel_align=True, # 设置显示y轴标签
xaxis_rotate=20, # x 轴刻度标签旋转的角度,在类目轴的类目标签显示不下的时候可以通过旋转防止标签之间重叠。
mark_point=['min', 'max'], # 设置两个图形标记点,最大最小值
mark_point_textcolor='#0A0A0D', # 设置标记点文本的颜色
mark_line=['average']) # 另外画出一条直线,表示平均薪资
line = Line() # 初始化折线对象
line.add("折线图", attr, v1) # 由于这里画折线图是辅助我们理解图形,所以没有进行过多的修饰
overlap = Overlap() # 初始化Overlap对象,用于结合上面两种图形进行展示
overlap.add(bar) # 添加柱状图
overlap.add(line) # 添加折线图
overlap.render(path="工作经验与薪资关系图.html") # 生成html可视化结果,path可随意配置路径
(3)一线城市公司规模雷达:
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
#
# @Version : 1.0
# @Time : xxx
# @Author : xxx
# @File : 一线城市公司规模雷达图.py
import pandas as pd
from pyecharts import Radar
df = pd.read_csv(r'.\爬虫数据(脏数据)\python招聘职位.csv', encoding='utf-8')
df1 = df.loc[:, [i for i in df.columns if i not in 'company+release_date+address+company_type']]
df2 = df1.dropna()
df3 = df2.iloc[:2000, :]
# 该自定义清洗函数是为了处理城市(place)字段
def wish(a):
a = a[0]
a = a.split('-')
return a[0]
df3['place'] = df3.loc[:, ['place']].apply(wish, axis=1)
v1 = [] # 这列表要存储雷达图中一线城市对应公司规模的数值
# func函数的作用是统计分析出一线城市各种公司规模的数量
def func():
for city in ['北京', '上海', '广州', '深圳']:
v = []
a = ['少于50人', '50-150人', '150-500人', '500-1000人', '1000-5000人', '5000-10000人', '10000人以上']
dic = {}
df4 = df3[df3['place'] == '{}'.format(city)].groupby(by='company_size').count() # 匹配对应城市按公司规模(company_size)字段进行分组,然后统计数量
index = list(df4.index)
value = [int(i[0]) for i in df4.values.tolist()]
for t in zip(index, value):
dic[t[0]] = t[1]
for i in a: # 这个for循环的作用是按a列表的顺序在字典进行取值,画图可以看出层次感
if i in dic:
v.append(dic[i])
v1.append(v)
func()
# 下面就是可视化工作
schema = [
("少于50人", 150), ("50-150人", 150), ("150-500人", 150),
("500-1000人", 50), ("1000-5000人", 50), ('5000-10000人', 50), ("10000人以上", 50)
] # schema结构根据数值范围自定义,一定要大于画图的数值
# 下面四个v是各个城市的值列表
v2 = [v1[0]]
v3 = [v1[1]]
v4 = [v1[2]]
v5 = [v1[3]]
radar = Radar('一线城市公司规模雷达图') # 初始化雷达图对象
radar.config(schema) # 配置雷达图的结构
# 下面进行画图,分为四个城市
# 参数说明(label_color表示城市标记的颜色;item_color表示雷达线条的颜色;legend_selectedmode表示图例选择的模式,控制是否可以通过点击图例改变系列的显示状态。默认为'multiple',可以设成 'single' 或者 'multiple' 使用单选或者多选模式。也可以设置为 False 关闭显示状态。)
radar.add("北京", v2, label_color=["#4e79a7"], item_color=["#4e79a7"], legend_selectedmode='single')
radar.add("上海", v3, label_color=["#AB2524"], item_color=["#AB2524"], legend_selectedmode='single')
radar.add("广州", v4, label_color=["#F7BA0B"], item_color=["#F7BA0B"], legend_selectedmode='single')
radar.add("深圳", v5, label_color=["#904684"], item_color=["#904684"], legend_selectedmode='single')
radar.render(path='一线城市公司规模雷达图1.html') # 生成雷达图html结果
(4)职位信息词云:
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
#
# @Version : 1.0
# @Time : xxx
# @Author : xxx
# @File : 职位信息词云图.py
import pandas as pd
import jieba
from wordcloud import WordCloud
df = pd.read_csv(r'.\爬虫数据(脏数据)\python招聘职位.csv', encoding='utf-8')
df1 = df.loc[:, [i for i in df.columns if i not in 'companyrelease_dateaddresscompany_type']]
df2 = df1.dropna()
df3 = df2.iloc[:2000, :]
text = "" # 定义空字符,用于下面拼接所有有关职位信息的描述
for i in df2['point_information']: # 取出所有职位信息的描述拼接到text变量
text += i
cut_text = jieba.cut(text) # 使用jieba对text进行分词,结果是一个列表
result = " ".join(cut_text) # 以空格拼接起来
# 下面生成词云
wc = WordCloud(
font_path=r'C:\Windows\Fonts\simkai.ttf', # 字体路径
background_color='black', # 背景颜色
width=1000, # 图片宽度
height=600, # 图片高度
max_font_size=50, # 字体大小范围
min_font_size=10, # 字体大小范围
max_words=1000 # 设置最大现实的字数
)
wc.generate(result)
wc.to_file('jielun.png') # 图片保存
2.可视化结果
(1)工资与学历关系图:
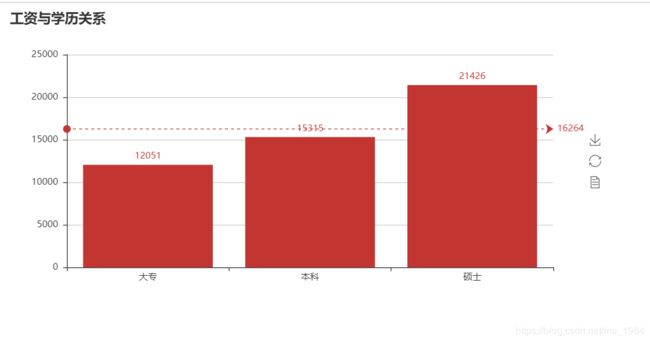
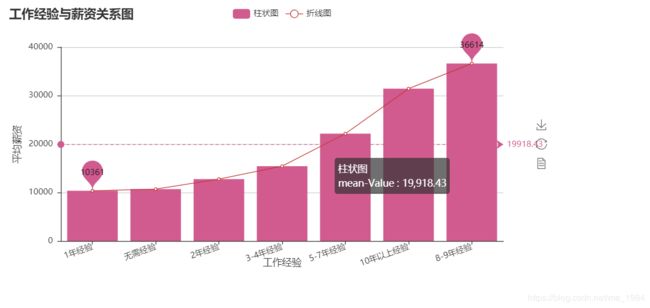
(2)工作经验与薪资关系图:
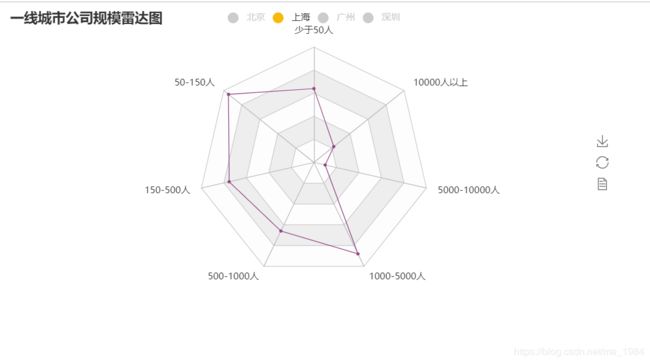
(3)一线城市公司规模雷达图:
(4)职位信息词云图:
可视化到这里就结束了,本人才疏学浅,有写的不准确的地方望见谅,有兴趣的朋友可以找我讨论,q群:995811075