Python + Selenium(十)元素对象操作
WebElement 是 WebDriver 中另一个重要的类,通过 find_element() 方法找到的元素对象就是 WebElement 类型。
WebElement 中定义了页面元素对象的操作方法。比如点击click(),输入文本send_keys()。
常用操作
元素点击
找到元素后可以对元素进行点击,模拟的是鼠标单击操作。
driver.find_element_by_id('su').click()
点击的时候,点击的是元素的正中心位置,这一点需要注意。
输入文本
Web 页面上的操作,除了点击基本上就是输入了。
输入通过 WebElement 中提供的 send_keys()方法实现。
# 在百度输入框中输入“测试”
driver.find_element_by_id('kw').send_keys('测试')
清空输入框
在输入框中输入内容时,有时候会存在输入框中已有文字,再输入就会追加再后面,造成输入内容可能并不是你想要的。那么就需要先清空当前输入框后再进行输入。
# 先清空,再在百度搜索框中输入“测试”
driver.find_element_by_id('kw').clear()
driver.find_element_by_id('kw').send_keys('测试')
滚动屏幕至元素可见
如果一个页面较长,某些元素没有出现在当前屏幕,可能会导致无法点击。那想要点击到,就需要滚动页面直至该元素出现在屏幕上。
location_once_scrolled_into_view就是用来实现该操作的,执行该操作就会滚动屏幕,将指定的元素展示在当前屏幕。注意,此方法作为一个属性来用,所以没有括号。
# 京东页面底部有很多链接,通过此属性滚动到该元素所在的位置
driver.find_element_by_link_text('合作招商').location_once_scrolled_into_view
注意,由于该方式使用了 JavaScript 中的
scrollIntoView()方法,可能后续会更改。代码中有这样一句警告:THIS PROPERTY MAY CHANGE WITHOUT WARNING(此属性可能会在没有任何提醒的情况下被更改).
获取元素内容
在自动化测试中,需要获取一些页面上的文本或者元素的属性进行断言。
手工测试的时候,我们通过肉眼去对比实际结果与预期结果的差异来判断是否存在 bug;而自动化测试的时候这种核实的过程只有交给代码来处理了,所以需要从页面上来提取一些关键字段作为实际结果来和预设的预期结果进行对比,以此来判断是否可能出现 bug。
WebElement 中提供了这些方法来获取页面上的值,可以根据需要取用。
获取元素文本
通过元素的text属性类获取页面上的文本。下面是一个登录成功的提示信息:
<div class="alert alert-success">登录成功div>
我们可以获取文本来断言:
a_info = driver.find_element_by_class_name("alert-success").text
# 预期的"登录成功"与实际取出来的文本做断言
assert '登录成功' == a_info
获取元素属性
在 HTML 元素的属性有三种:
attribute由 HTML 提供,就是我们之前看到的属性如 id、name、class等;property是 JavaScript 对每个元素定义的属性,通过开发者工具可以查看到这些 property;
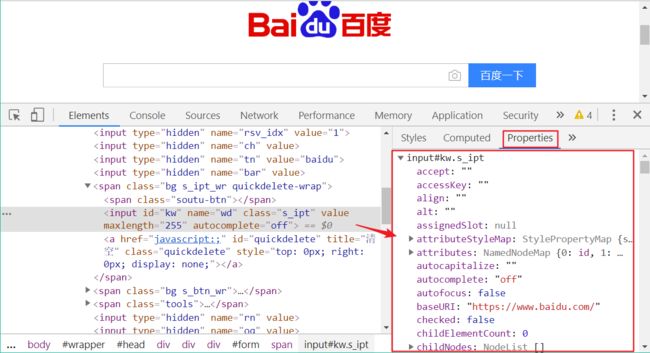
css property是 css 的属性,在开发者工具中也能看到:

通过get_attribute(name)可以获取 HTML 页面元素属性:
# 获取百度一下按钮的value属性值
driver.find_element_by_id('su').get_property('value')
## 百度一下
通过 get_property(name) 获取元素的 JavaScript 属性:
# 获取百度一下按钮的baseURI的值
driver.find_element_by_id('su').get_property('value')
## https://wwww.baidu.com
通过value_of_css_property(property_name)返回元素的 css 属性值,比如针对上面图中的二维码,二维码的 url 是放在 css 的 background 属性值中。要想获取二维码的 url :
bg = driver.find_element_by_class_name('qrcode-img').value_of_css_property('background')
## 'rgba(0, 0, 0, 0) url("https://ss1.bdstatic.com/.../zbios_09b6296.png")'
上面的结果省略了一些,如果你想要拿到 url 可以通过字符串切片或者正则表达式:
url = bg.split('("')[1].split('")')[0]
# 或正则表达式
import re
url = re.search(r'\("(.+?)"\)', bg).group(1)
获取元素位置、大小
location属性用于获取元素左上角所在的坐标点,以字典形式返回x,y的值:
driver.find_element_by_id('su').location
## {'x': 738, 'y': 223}
屏幕的横向坐标位置用 x 表示,纵向坐标点的位置用 y 表示
通过size属性可以获取元素的像素大小:
driver.find_element_by_id('su').size
## {'height': 36, 'width': 100}
rect 属性,以字典形式返回元素大小和左上角的位置,相当于上面两个属性的综合:
driver.find_element_by_id('su').rect
## {'height': 36, 'width': 100, 'x': 737.8108520507812, 'y': 223.1344451904297}
元素标签
tag_name 属性用于获取元素标签名:
driver.find_element_by_id('su').tag_name
## input
元素父级元素对象
parent 属性用于获取元素的父级元素对象:
driver.find_element_by_id('su').parent
## 元素截图
以下三种方式用于对元素截图,注意这里只会截取对应的元素,并且元素必须要可见。
| 截图方法 | 说明 |
|---|---|
| screenshot_as_base64 | 以base64位返回元素截图,可用于 HTML 报告 |
| screenshot_as_png | 返回元素截图二进制图片数据,可通过文件读写生成文件 |
| screenshot(filename) | 返回元素截图到指定路径,保存到本地 |
元素状态判断
有一些返回 bool 类型的方法,用来判断元素的一些状态。比如是否被选中,是否可见等等。
| 方法 | 说明 |
|---|---|
| is_selected() | 元素是否被选中 |
| is_enabled() | 元素是否可用 |
| is_displayed() | 元素是否可见 |
查找元素
通过 find_element() 方法查找到的元素,可以视为一个局部的 HTML 页面。这部分的 HTML 页面也还可以进行元素查找,相当于缩小了查找范围。因为 WebElement 元素对象还可以进行 find_element()。
<div id="u1">
<a href="http://news.baidu.com" name="tj_trnews" class="mnav">新闻a>
<a href="https://www.hao123.com" name="tj_trhao123" class="mnav">hao123a>
<a href="http://map.baidu.com" name="tj_trmap" class="mnav">地图a>
div>
以上面的 HTML 片段做一个简单的演示:
u1 = driver.find_element_by_id('u1')
news = u1.find_element_by_link_text('新闻')
注意,第二句是对找到的元素进行查找。
获取页面 title 和 URL
还有一部分内容,由 WebDriver 提供的方法获取。这部分内容也会用于断言,由于这部分内容不属于某个具体的元素,所以是由 WebDriver 类来提供。
- 获取页面的 title,也就是 head 中的 title:
driver.title
## 百度一下,你就知道
- 获取当前 url:
driver.current_url
## https://www.baidu.com