Hadoop-2.5.1安装步骤及异常处理
目标
在vmware14.1.1中的三个虚拟机上安装hadoop 2.5.1 稳定版本。
由于hadoop 2.x.x 都是同一个系列,所以其他hadoop 2.x.x版本的安装可以参照这篇步骤来做。
环境介绍
三台vmware-14.1.1中的虚拟机
操作系统:ubuntu 16.04 LTS
网络配置:
- vm-01 /etc/hosts文件
127.0.0.1 localhost
#127.0.1.1 vm-01
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
#set cluster Ip
#192.168.184.131 vm-01
192.168.184.132 vm-02
192.168.184.133 vm-03
192.168.184.131 master
192.168.184.132 slave1
192.168.184.133 slave2
- vm-02 /etc/hosts文件
127.0.0.1 localhost
#127.0.1.1 vm-02
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
#set cluster Ip
192.168.184.131 vm-01
#192.168.184.132 vm-02
192.168.184.133 vm-03
192.168.184.131 master
192.168.184.132 slave1
192.168.184.133 slave2
- vm-03 /etc/hosts文件
127.0.0.1 localhost
#127.0.1.1 vm-03
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
#set cluster Ip
192.168.184.131 vm-01
192.168.184.132 vm-02
#192.168.184.133 vm-03
192.168.184.131 master
192.168.184.132 slave1
192.168.184.133 slave2
上面的三个hosts文件中一定要注意第二行哪个127.0.0.1 vm-x的配置,一定要注释掉,因为后面我们配置hadoop的一些配置文件时会使用到主机名,如果不注释掉那一行,hadoop则会依据主机名找到127.0.0.1这个ip地址,那么最后就是会报错的。
java配置:
三个虚拟机器中java版本都是java version “1.8.0_181”,安装路径都是/opt/java,java的安装步骤可以参看网上等相关资料,或者看自己的笔记,这里就不再细讲了。
用户: hduser
用户组: hadoop
下载hadoop
现在百度搜索"apache官网",进入到官网后,下载路径是:
apache->project->Hadoop->页面的Dowload按钮,可以看到下面的页面:
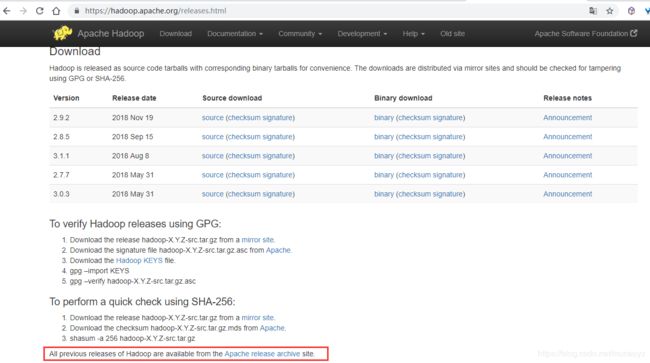
由于我们想安装的是hadoop 2.5.1,在这个页面的下载项中没有这个版本,所以我们点击红框中的那个链接在以前版本中找到hadoop 2.5.1。
点击之后进入到页面https://archive.apache.org/dist/hadoop/common/
然后选择hadoop 2.5.1 项目,进入到下载页面https://archive.apache.org/dist/hadoop/common/hadoop-2.5.1/,页面如下所示:
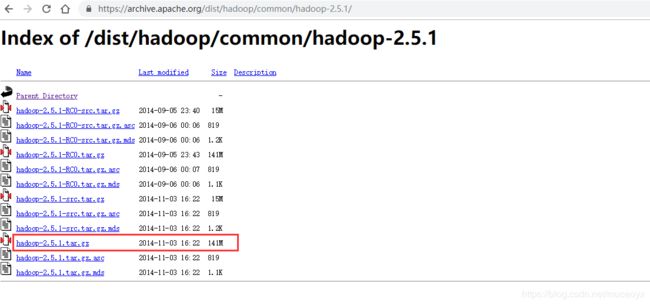
由于打算在ubuntu16.04中使用安装包安装,所以我们选择hadoop-2.5.1.tar.gz文件选项,接下来就是等着下载完成吧。如果想要对下载后的文件进行验证,那么下载这个页面中对应的校验码文件进行验证就可以了。
接下的操作主要是在主机vm-01上执行的。
解压文件并更改权限
在/opt下创建文件夹hadoop
~$ mkdir /opt/hadoop
如果遇到权限问题,那么就在语句的前面加上sudo获得超级权限就好了。
然后对下载的hadoop-2.5.1.tar.gz文件在/opt/hadoop下进行挤压
/opt/hadoop$ tar -zxvf hadoop-2.5.1.tar.gz
将hadoop文件的权限赋给hduser用户:
/opt/$ sudo chown -R hduser:hadoop hadoop/
添加tmp文件夹
因为HDFS默认把namenode的格式化信息存在了系统的tmp目录下,该目录每次开机会被清空,因此每次重新启动机器,都需要重新格式化HDFS。解决方案是配置一个新的tmp目录给hadoop,这样就无需每次重新格式化hdfs。
/opt/$ mkdir /opt/hadoop/hadoop-2.5.1/tmp
修改环境配置
在家目录下的.bashrc文件下配置环境变量:
~$ vim .bashrc
在底部增加下面的内容:
#set hadoop path
export HADOOP_HOME=/opt/hadoop/hadoop-2.5.1
export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
修改hadoop配置
core-site.xml和hdfs-site.xml是站在HDFS角度上的配置文件;core-site.xml和mapred-site.xml是站在MapReduce角度上的配置文件
配置hadoop-env.sh
~$ vim /opt/hadoop/hadoop-2.5.1/etc/hadoop/hadoop-env.sh
在文件钟找到“export JAVA_HOME”,将其更改为:
export JAVA_HOME=/opt/java/jdk1.8.0_181 #自己java的home
配置core-site.xml
核心配置文件,设置临时目录及配置的是HDFS的地址和端口号,注:须将下面配置中的value中ip修改为192.168.184.131,也就是master节点的IP地址。
~$ vim /opt/hadoop/hadoop-2.5.1/etc/hadoop/core-site.xml
在标签configuration中添加如下的内容:
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/hadoop/hadoop-2.5.1/tmpvalue>
<description>A base for other temporary directories.description>
property>
<property>
<name>fs.default.namename>
<value>hdfs://192.168.184.131:9000value>
property>
configuration>
配置hdfs-site.xml
修改Hadoop中HDFS的配置,配置的备份方式默认为3,Salve少于3则会报错
~$ vim /opt/hadoop/hadoop-2.5.1/etc/hadoop/hdfs-site.xml
配置文件内容:
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
configuration>
配置mapred-site.xml
/opt/hadoop/hadoop-2.5.1/etc/hadoop$ cp mapred-site.xml.template mapred-site.xml
添加下面的内容:
<configuration>
<property>
<name>mapred.job.trackername>
<value>http://192.168.184.131:9001value>
property>
configuration>
接下来还要再配置一下yarn-site.xml配置文件,如果不配置yarn-site.xml的相关信息,会导致8088端口网页看不到资源信息,并且nodemanager启动后过一段时间会消失的问题,详情参见[异常1](#1. 8088端口页面上总是没有资源,dataManager进程启动后过一会儿会消失)。对yarn-site.xml文件增加下面的内容:
<configuration>
<property>
<name>yarn.resourcemanager.addressname>
<value>192.168.184.131:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>192.168.184.131:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>192.168.184.131:8031value>
property>
configuration>
上面这个yarn-site.xml配置文件的192.168.184.131就是master的地址,为了防止出错,所以配置成了绝对地址。
配置salves文件
配置salves文件
由于是hadoop-2.5.1版本,所以不再需要配置master文件,直接配置salves文件
Master主机特有:
/opt/hadoop/hadoop-2.5.1/etc/hadoop$ vim salves
如果salves文件里面有localhost,记得一定要移除,然后再添加下面的内容:
192.168.184.132
192.168.184.133
目前是打算让192.168.184.131当作master,其余的192.168.184.132和192.168.184.133当作从节点。
配置Salve的hadoop,可以单机采用上述1-5;也可直接将master节点上的hadoop文件夹复制过去,salve机器上的slaves文件是无需配置的,但无所谓。
分发hadoop文件文件到vm-02
/opt$ scp -r hadoop/ hduser@vm-02:software/
由于vm-02上的/opt是root用户所拥有,所以不能直接拷贝到vm-02的/opt下。先拷贝到vm-02的~/software,然后再进行移动到/opt/下。
ssh登录到slave机器vm-02上。如果没有配置三台机器的免密码登陆,可以参看百度的“配置ssh免密码登录”教程。这里不再细说。
/opt$ ssh vm-02
在vm-02上配置环境:
~$ vim .bashrc
在底部加入:
#set hadoop path
export HADOOP_HOME=/opt/hadoop/hadoop-2.5.1
export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
然后保存并退出。
要想让上面配置的环境生效,可以执行. ~/.bashrc或source ~/.bashrc命令,或者重新登陆终端。
启动和验证
启动hadoop
(1) 格式化namenode
hduser@vm-01:~/ hadoop namenode -format
(2)启动
hduser@vm-01:~/ start-all.sh
验证是否启动成功
使用jps命令来查看相关进程是不是已经都启动了。
master显示:
hduser@vm-01:~$ jps
98468 Jps
95757 ResourceManager
95420 NameNode
95615 SecondaryNameNode
slave显示:
vm-02上:
hduser@vm-02:~$ jps
32353 NodeManager
32535 Jps
32251 DataNode
vm-03上:
hduser@vm-03:~$ jps
12338 DataNode
12698 Jps
12430 NodeManager
也可以运行命令查看各个节点信息:
hadoop dfsadmin -report
或者登录信息网页检测:
http:192.168.184.131:50070
运行mapreduce示例程序(wordcount)
启动hadoop集群
hduser@vm-01:~$ start-all.sh
创建hdfs目录
hduser@vm-01:~$ hadoop fs -mkdir /input
上传文件
hadoop fs -put pg132.txt /input/
hduser@vm-01:~/tmp/$ hadoop fs -put pg132.txt /input/
查看文件
hduser@vm-01:~/tmp/$ hadoop fs -ls /input
输出文件夹为output,无需新建,若已存在需删除
运行hadoop自带例子
hduser@vm-01:~/tmp/$ hadoop jar /opt/hadoop/hadoop-2.5.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.1.jar wordcount /input/ /output/
查看文件输出结果
hduser@vm-01:~/tmp/$ hadoop fs -ls /output
查看词频统计结果
hduser@vm-01:~/tmp/$ hadoop fs -cat /output/part-r-00000
将hdfs上文件导出到本地
hduser@vm-01:~/tmp/$ hadoop fs -get /output/part-r-00000 ./
异常问题解决
1. 8088端口页面上总是没有资源,dataManager进程启动后过一会儿会消失
分布式搭建成功后,发现在8088端口的页面上总是没有资源。查看从节点上的datanodemanager的相关的以yarn开头的日志文件有:
org.apache.hadoop.ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8031异常。
这个异常也会导致调用start-all.sh脚本后,虽然可以在从节点上看见datamanager进程,但是过一会儿它就会消失。
解决方法
在 hadoo的etc/hadoop/yarn-site.xml配置下面的参数即可以解决问题:
<property>
<name>yarn.resourcemanager.addressname>
<value>linux321:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>linux321:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>linux321:8031value>
property>
注意主机名linux321的替换,最好是换成绝对的IP地址。
总结
到这里就完成在vmware14.1.1的三台ubuntu 16.04 LTS 虚拟机上对hadoop-2.5.1的搭建了。在搭建的过程中一定要慢一点,遇到问题一定要看看日志信息。