1. 简介
Conflux利用DAG结构并行出块提升比特币性能。在800个亚马逊EC2上部署2W个全节点,吞吐量高达6400笔每秒,处理速度为5.76GB/h。
中本聪共识:一次产生一个区块,一个区块接着一个区块形成链式结构
Conflux默认出块的时候交易不冲突,允许并发出块;后一个区块必须指向前一个区块,形成DAG图。如何保证不可逆转呢?选择一条主链,对区块链进行拓扑排序以确定所有区块的编号,将区块从DAG结构变成串联结构;因此,conflux使用修改后的基于链的中本聪共识来解决链式共识问题。
在20Mbps的网络带宽限制下,Conflux每5秒可以处理4MB的区块。在40Mbps的网络带宽限制下,Conflux每2.5秒可以处理4MB的区块。在20Mbps的网络带宽限制下,Conflux每7.6-13.8分钟确认交易,处理速度为4MB/5s。在20Mbps的网络带宽限制下,Conflux每4.5-7.4分钟确认交易,处理速度为4MB/2.5s。
2.1 Conflux结构
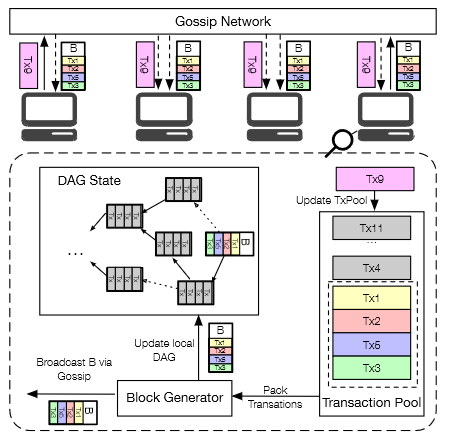
由于网络延迟,短时间内各个节点的DAG结构内容可能不同,Conflux的目的是维持节点之间的一致性。
- Gossip Network:采用比特币Gossip协议进行广播
- Pending Transaction Pool:采用比特币交易池存放未处理交易
- Block Generator:采用Pow共识生成区块,支持扩展其他共识协议
- Local DAG State:采用DAG结构并行出块
2.2 Conflux共识
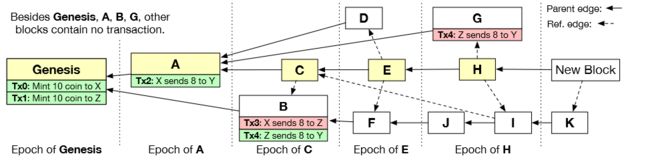
两种边:
- Parent Edge:每个区块只有一个Parent Edge(实线),代表投票关系。 C->A: C认可A的交易
- Reference Edge:每个区块可以有多个Reference Edge(虚线),代表区块生成的顺序。
主链: 不同于比特币的longest chain,Conflux采用Ghost协议选取主链,从Genesis区块开始,计算每个节点的子树大小,拥有largest subtree成为主链的一个节点。在图2中,Conflux选取Genesis, A, C, E, and H作为主链,而不是Genesis, B, F, J, I, K。因为A的子节点比B多?只看实线?论文没说清楚,暂时认为只看实线关系。
生成区块:一个节点生成区块的时候会计算当前DAG图的主链,将主链的最后一个节点作为parent block,生成一条parent edge。通过这种机制,节点间更加倾向于生成一致的主链。然后遍历DAG图中没有incoming edge的block,并生成一条reference edge指向这些入度为0的block。
Epoch: 通过pivot chain, parent edges, and reference edges将Conflux分隔成各个Epoch。如图2,主链上每一个节点代表一个Epoch。一个Epoch中的区块包含当前主链节点通过parent edges和reference edges可到达的区块并且没有被包含在上一个Epoch中。例如 J 属于 H 的Epoch,因为 E 不能到达 J ,主链中 H 第一个到达 J 。同理,F属于E的Epoch但不属于H的Epoch。
Block Total Order: 首先按照Epoch对节点进行排序。然后对同一个Epoch内部的节点进行拓扑排序。 If two blocks in an epoch have no partial order relationship, Conflux breaks ties deterministically with the unique ids of the two blocks。例如在图2中,区块顺序为A, B, C, D, F, E, G, J, I, H, and K
Transaction Total Order: 交易的顺序由包含这笔交易的区块的Block Total Order确定先后顺序。如果两笔交易在同一个区块内,按照交易出现的顺序(appearance order)排序。在排序(deriving the orders)的时候,Conflux会检查交易是否冲突,如果两笔交易发生冲突,只会保留最早出现的那笔交易,丢弃其他交易。
2.3 安全分析
- 攻击者将Genesis block作为parent block,并生成一条parent edge指向Genesis block。由于攻击者的Block(下面简称AT.Block)没有子节点,AT.Block的Epoch由后面指向他的Future Block决定,所以攻击无效。因此,攻击者想要发起重放攻击只能节点主链一致性。
- 攻击者制造新的主链,这种情况的分析类似中本聪共识。由于在网络中大多数为诚实节点,随着时间的推移,没有足够的算力,攻击者不可能修改主链。
3.算法实现
在Bitcoin Core codebase v0.16.0上实现Conflux和GHOST。
Block Header: 在Header中加入每个32字节的reference edges的Hash。实验表明,加入reference hashes后 一个区块大小增加不到960字节。如果使用工作量证明(PoW)方案生成新块,则必须将这些reference hashes作为puzzle的一部分包含在内,以避免攻击者能够以基本上零成本的方式生成具有不同引用的块。
Glossy Network: Conflux和GHOST都需要维护block/树的DAG的完整结构,而比特币核心只传播识别最长的链中的block。因此,我们修改了比特币核心的Gossip网络层,以广播和转发所有block。 为了确保当block传递到共识层时,其所有过去的block已经传递,Conflux保持每个block的有效性。 每当收到一个block时,它就会使用广度搜索(BFS)遍历DAG结构,并更新每个遍历block的有效性。 当且仅当Conflux已收到block的所有过去block时,block才有效(i.e可通过parent edges and reference到达的block)。 然后,Conflux将所有新验证的block传递到共识层。
Detecting Stale Blocks: 比特币核心具有以下机制来检测陈旧的块(例如,由攻击者生成和隐藏的块)。每个节点周期性地与其对等节点同步以维持网络调整时间,该时间是其对等体返回的时间戳的中值。 比特币核心中的每个块也带有时间戳。 如果新块的时间戳早于前11个块的中间时间戳,或者新块的时间戳比网络调整时间晚两个小时,则新块将被标记为无效。
利用和比特币中使用相同的机制,具有以下修改。 首先,按照在实验中使用的块生成率按比例修改规则。 例如,如果系统每20秒生成一个块(即,比比特币快30倍),则如果其时间戳早于先前330个块的中值时间戳,则认为该块无效。 其次,Conflux不会删除具有无效时间戳的块。 在计算子树中用于选择主链的块数时,它会忽略此无效块。 基本原理是:只要无效块不再影响已经稳定的时期的分区方案,就可以将块包含在未来的时期中,处理块内的事务是安全的。
- Bootstrapping a Node: 当一个节点启动时,它将与每个节点握手并运行一个单向同步过程来更新其本地状态。对于GHOST和Conflux,节点需要从其对等体下载树/ DAG中的所有块,而不仅仅是主链。为了实现这种单向同步,我们使用四种额外的消息类型增强了比特币核心代码库:gettips,tips,getchains和chains。为简单起见,让我们考虑节点A尝试从另一节点B下载块的情况。首先发送B请求提示列表的gettips消息,即(父节点)树中的叶块(由他们的32字节哈希)。提示用于响应gettips以检索B知道的所有tip的块哈希。对于B的每个tip,A检查这是否是未知块并将所有答案打包在getchains消息中。收到此getchains消息后,对于A的每个新的tip,B计算从创世块到此提示的链中最后一个已知块,并发送一个链消息,其中包含从最后一个已知块之后开始的块列表。
4. 实验结果
在多达800个Amazon EC2 m4.2xlarge虚拟机(VM)上部署了Conflux,每个虚拟机具有8个内核和1Gbps网络吞吐量。 默认情况下,在每个VM中运行25个Conflux完整节点,并将每个完整节点的带宽限制为20Mbps。
用inter-city延迟测量,将每个VM分配给20个主要城市之一。 插入人工延迟来模拟城市间的延迟。 对于每个完整节点连接到平均10个随机选择的对等体。 为所有完整节点分配了相等的块生成功率。 对于每个生成的块,使用比特币核心代码库中的测试实用程序来完成具有人工事务的块。 为了避免不必要的PoW计算,我们使用泊松过程模拟挖掘。
对于所有实验,监控了Conflux引入的开销,因为Conflux采用了基于DAG的方法。 与PoW相比,计算开销可以忽略不计,并且空间开销最大为每块960字节,与几MB中的典型块大小相比较小。
4.1 吞吐量
为了评估吞吐量的提高,在以下两个配置下允许10k个完整节点,每个配置运行每个协议两个小时:
1)将块大小限制从1MB增加到8MB,固定块生成率为20s/块;
2)将块生成速率从每块5秒减少到每块80秒,固定块大小限制为4MB。
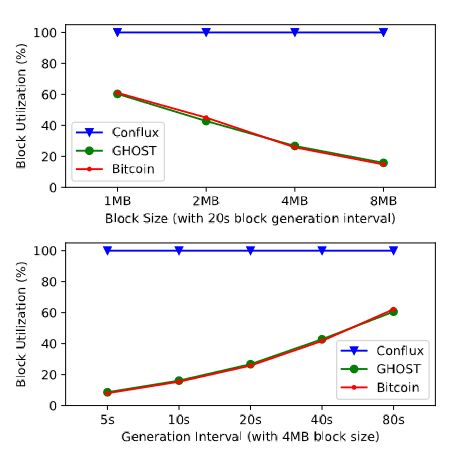
在块生成设置为4MB / 5s时,Conflux实现了2.88GB / h的吞吐量。假设与真实世界的比特币网络具有相同的交易规模,那么Conflux可以每秒处理3200个交易。并且结果随着块大小和块生成速率的增加,并行生成更多的块。
4.2 交易确认时间
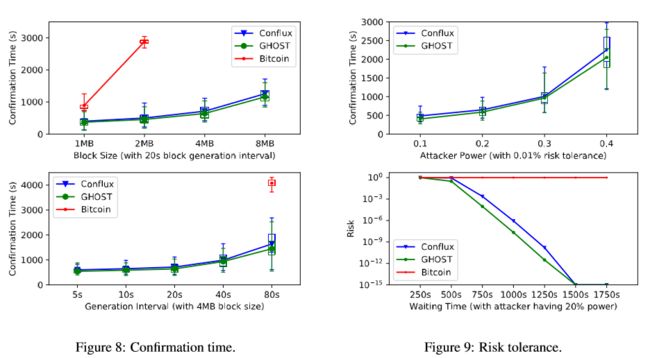
确认时间是用户必须等待以获得块的总顺序不会改变的高信度的持续时间。结果表明,Conflux可以在几分钟内确定块。 当使用4MB / 5s的块生成设置时,Conflux平均在10.0min内确认块。 在所有配置下,Conflux中的用户等待与GHOST类似的确认时间。
结果还表明,随着块大小的增加,块需要更长时间得到确认。 这是因为使用较大的块将导致并行生成更多块。 某些节点可能会生成不在链的最后一个块下的块(parent block不是最后一个块)。增加块的产生将使链更快地生长,交易更快得到确认。但是随着块生成速率接近单个节点的处理能力,这种影响会减小,因为频繁的并发块和分支将减慢确认速度。
结果表明,即使用户假设攻击者控制了30%的块生成功率,Conflux仍然可以在16.8分钟的介质中确认块,并且可以获得99.99%的置信度。