Android性能优化系列一:启动优化
文章目录
- 黑白屏优化
- 冷/热/暖启动
- 代码未优化造成的问题
- App启动时间检测方式
- 方式一:adb命令
- 方式二:手动打点
- 启动优化工具选择
- traceview介绍
- Systrace介绍
- 优雅获取方法耗时
- 异步优化分析
- 异步优化方案优化-启动器
- 启动器的具体使用
- 更优秀的延迟初始化方案
- 更优方案
黑白屏优化
黑白屏原因
在App的启动流程中,我们已知:当系统加载并启动App时,需要消耗相应的时间,即使不到1s,用户也会感觉到当点击App图标时会有“延迟”现象,为了解决这一问题,Google的做法是在App创建的过程中,先展示一个空白页面(实际上就是窗体的默认背景, 启动页面的UI加载绘制完成后显示xml布局内容),就是为了让用户体会到点击图标之后立马就有响应;而这个空白页面的颜色则是根据我们在manifest文件中配置的主题背景色来决定的;一般默认是白色。
解决方案:
方案1:修改AppTheme
在应用默认的AppTheme中,设置系统"取消预览(空白窗体)"为true,或者设置空白窗体为透明;具体代码如下;该两种方式都属于同一种方案:将Theme的背景改为透明,这样用户从视觉上就无法看出黑白屏的存在。简单粗暴的取消了一点击就有响应的初衷,于是在保留google初衷的前提下,考虑其他方案。
<!-- Base application theme. -->
<style name="AppTheme" parent="Theme.AppCompat.Light.NoActionBar">
<!-- Customize your theme here. -->
<item name="colorPrimary">@color/colorPrimary</item>
<item name="colorPrimaryDark">@color/colorPrimaryDark</item>
<item name="colorAccent">@color/colorAccent</item>
<!--设置系统的取消预览(空白窗口)为true-->
<item name="android:windowDisablePreview">true</item>
<!--设置背景为透明-->
<item name="android:windowIsTranslucent">true</item>
</style>
方案2:
- 自定义继承自AppTheme的主题
- 将启动Activity的theme设置为自定义主题
- 在启动Activity的onCreate方法中,在super.onCreate和setContentView方法之前调用setTheme方法,将主题设置为最初的AppTheme,(这一步根据自己的实际情况决定是否添加)
<!-- 1.自定义主题 -->
<style name="AppTheme.LaunchTheme">
<!-- 设置背景图片 -->
<item name="android:windowBackround">@drawable/lauch_layout</item>
<!-- 设置全屏 -->
<item name="android:windowFullscreen">true</item>
<item name="android:windowNoTitle">true</item>
</style>
<!-- 2.设置启动Activity主题 -->
<activity
android:name=".SplashActivity"
android:theme="@style/AppTheme.LaunchTheme">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
<!--3.在代码中将主题设置回来 -->
protected void onCreate(Bundle savedInstanceState) {
setTheme(R.style.AppTheme);
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_splash);
}
冷/热/暖启动
-
冷启动:程序从头开始,系统没有为该应用程序创建进程。一般场景:程序安装后第一次启动;
应用程序被系统完全终止后再打开。 -
热启动:此时程序仍然驻留在内存中,只是被系统从后台带到前台,因此程序可以避免重复对象初始化,加载布局和渲染。需要注意的是,如果程序的某些内存被系统清除,比如调用了onTrimMemeory方法,则需要重新创建这些对象以响应热启动事件
-
暖启动/温启动:它包含热启动和冷启动一系列的操作子集,比热启动的消耗稍微多一点。它与热启动最大的区别在于,它必须通过调用onCreate方法开始重新创建活动,也可以从传递给onCreate方法中保存的实例状态中获得某些对象的恢复。
冷启动流程:加载并启动App—>启动后立即为该App显示一个空白启动窗口—>创建App进程(创建应用程序对象)—>创建主Activity—>加载布局、绘制
有了三种启动的基本认识,那我们启动优化的重点应该关注哪一种启动方式呢?显然是冷启动,它做的事情做多,也最耗时,生命周期方法也调用的最多,由于进程的启动的过程,部分流程对我们来说就像黑匣子,无法针对性的做相关处理,所以我们能想到的的重点就是放在我们能够触及的地方,Application的onCreate和启动页LaunchActivity 的onCreate方法。
代码未优化造成的问题
在构建App时,我们经常需要引用一些第三方SDK,而项目业务越多,引用的第三方也越多,有些第三方会要求在Application的onCreate方法中对其进行初始化。这意味着:在application的onCreate方法中执行的时间会越长,首个Activity布局渲染时间也会相应的拉长。同理,如果我们在Activity的onCreate,onStart、onResume方法中执行任务时间过长,同样也会导致布局被渲染的时间拉长。这样直接导致的问题就是,用户会感觉页面迟迟没有加载出来,大大降低了用户体验。
有了大致的优化方向,我们需要知道启动过程的耗时情况,如何检测App启动的时间呢?有了启动时间的监测
结果,才能根据优化前后的结果对比,具体分析优化效果。
App启动时间检测方式
方式一:adb命令
adb shell am start -W packageName/packageName.MianActivity(首屏Activity)
ThisTime : 最后一个 Activity 的启动耗时(例如从 LaunchActivity - >MainActivity「adb命令输入的Activity」 , 只是统计 adb命令输入的Activity的启动耗时,它之前可能还有SplashActivity、GuideActivity)
TotalTime : 所有Activity的启动总耗时(有几个Activity 就统计几个)
WaitTime : 应用进程的创建过程 + TotalTime .
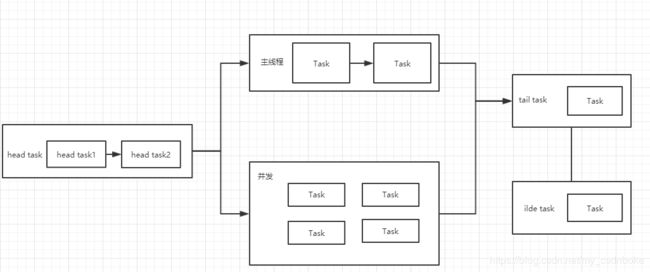
ThisTime 优点:线下使用方便 缺点:不能带到线上使用,非严谨、精确时间 启动时埋点,启动结束埋点,二者差值就是启动时间。我们可以定义一个专门来处理启动时间检测的类 我们能够接触最早的启动相关回调方法就是Application的attachBaseContext方法,在该方法中调用LaunchTimer的startRecord();那么问题来了,在哪里调用启动结束的方法呢?网上不少的资料都是调用onWindowFocusChanged方法作为启动的结束时间点。其实这是一个误区,这个方法调用的时间点仅仅是Activity的首帧时间,即首次进行绘制的时间,并不能表示界面已经真正的展示出来了,性能优化的核心是为了提升用户体验,并不是仅仅在乎数据的好看(这里指的是启动时间表面上的缩短),当然这只是目的之一,所以启动过程开始和结束的埋点就比较重要,应该是应用真实启动结束时即用户真正看到界面时,而不应该只是首帧绘制时间点。正确的做法是,等到真实数据展示,再调用记录启动结束时间的方法endRecord,通常是Feed第一条展示,主页列表展示的第一条。 手动埋点方式可精确的控制开始的位置和结束的位置,可以方便的进行用户启数据的采集,上报给服务器,针对所有的用户上报的数据进行整合,算平均值,根据不同版本进行比对。但是要注意避开埋点误区,采用Feed第一条展示作为启动结束点。另外addOnDrawListener要求API最低版本为16 常用的就是systrace和traceview这两种工具,两种方式互相补充,所以需要正确认识工具及不同场景选择合适的工具(才能发挥工具最大作用)。我们先来了解traceview这个工具 traceview的特点: 使用方式: 如果是采用真机调试,通过adb pull /storage/emulated/0/文件名.trace 将文件拉到电脑的项目目录。拖进as就可以进行分析了。这不是本文重点受篇幅所限,这里提一下分析的注意事项,至于具体使用分析可自行百度。 Top Down 展示函数调用列表如函数A调用了哪些函数,依次展示出来,函数右键Jump to Source 跳转至源码处 需要注意Wall Clock Time和Thread Time的区别,有可能没有获取到锁,线程处于阻塞等待锁,这也是耗时间的,获取到锁后CPU执行任务的时间才是Thread Time,所以说Wall Clock Time大于Thread Time,而Thread Time才是性能优化应该关注的指标,否则容易误导优化方向 Call Chart :函数A调用函数B,A在上面,B在下面 traceview缺点: Systrace特点 结合Android内核的数据,生成Html报告 API18以上使用,推荐TraceCompat向下兼容 使用方式 TraceCompat.beginSection(“xxx”);// 手动埋点起始点 TraceCompat.endSection();// 手动埋点结束点 python systrace.py -b 32768 -t 5 -a packageName -o trace.html sched gfx view wm am app 优势: 轻量级,开销小 直观反映cpu利用率 Systrace具体使用不是本文重点,有兴趣的可参考: Android应用开发性能优化完全分析 背景:需要知道启动阶段所有方法耗时 常规方式 痛点 AOP: Aspect Oriented Progamming 面向切面编程 AspectJ:AspectJ是一个面向切面的框架,它扩展了java语言,所以它有一个专门的编译器用来生成遵守java字节码规范的class文件,它会在编译阶段根据切面点的代码逻辑,在生成的class字节码文件中对应的地方添加相关代码,在运行时实现对切面点的监测。 Join Points:程序运行时的执行点,可以作为切面的地方 PointCut:带条件的JoinPoints Advice:一种Hook,要插入代码的位置 方法耗时监测示例: 自定义获取方法耗时注解 在需要监测的方法处添加注解,针对启动过程中方法耗时监测,可在application的onCreate和LaunchActivity的onCreate和onResume中的方法添加注解,此处以application的onCreate中执行的方法为例 在一个类中统一处理切面点注解,以及添加具体监测的逻辑代码 方法耗时日志 异步优化的核心思想就是子线程分担主线程任务,并行执行任务减少时间。但是尽量避免通过直接new 的方式创建子线程,因为这样比较粗暴,容易造成内存泄露,没有复用的概念。所以考虑采用创建线程池。这里采用FixedThreadPool线程池,它是一种线程固定的线程池,当线程处于空闲状态时,他们并不会被回收,除非线程池被关闭了,由于它只有核心线程并且不会被回收,这意味着它能够更加快速地响应外界的请求,至于核心线程的数量,如果是一个固定值,针对不同设备貌似不友好,所以可以参考AsyncTask的方式进行设定 这里为何不将多个任务放到一个Runnable里面呢?理论上是可以的,但是如果放到一个Runnable里面,就相当于这些任务在一个线程执行,并没有充分利用线程池的其它线程。还是那5个初始化方法,现在再次测一下application的onCreate方法耗时: 21312-21312/com.ixuea.courses.mymusic D/AppContext: cost 6 之前的初始化都在主线程执行,有些单个初始化方法就耗时几百毫秒,采用线程池后,现在application的onCreate在主线程耗时才6毫秒,虽然单个方法在子线程耗时不变,但是主线程耗时减少了啊,虽然子线程还在执行任务,但是主线程可以执行后续操作了,大大降低了启动时间。但是实际情况是总会有些代码逻辑只能在主线程执行,就不能采用这种方式了,还有就是如果后续需要执行的任务必须要在前面的任务执行完毕之后才能执行,有依赖关系,这种情形又改如何处理呢?可以通过CountDownLatch来实现: 举个例子,假如在启动页面要显示网络图片或播放在线视频,需要先确保网络加载工具初始化好,CountDownLatch就好比加了一把锁,第三方工具initDownLoad()初始化没有执行完,就会在await那里等待,知道它执行完,调用countDown方法,满足条件之后才会跳过去,执行后面的任务,显示图片或播放视频。 前面分析的常规异步方案虽然在某种程度上能节省时间,但是仍然有缺陷。主要体现在以下几个方面 启动器介绍 核心思想:充分利用CPU多核,自动梳理任务顺序 启动器流程 启动器的流程图 这比较好理解,可以满足必须在主线程执行的任务Task,更多的是在子线程并发执行,但是某些任务之间有依赖关系,即必须有先后时,可以根据情况设置在头部先执行,或者在尾部后执行,至于ilde task 好比idleHandler,即可以在空闲时执行的任务,以满足多种需求。 启动过程中的单个任务封装为一个Task,可以理解为Runnable,只是做了依赖关系的处理,即对任务的今后进行排序。是否需要等待,选择执行的线程(是否在主线执行),选择IO密集性任务的线程池还是CPU密集型的线程池,等等一系列的封装。下面简单介绍一下启动器的相关类和作用。 TaskDispatcher 是启动器的调用类,通过init方法,需要进行初始化,如全局的上下文。因为把第三方库的初始化,很多时候也需要上下文。这一点应该比较容易理解。addTask方法的作用就是往启动器中添加task,比如可以将每一个第三方库的初始化都封装为一个Task,通过链式调用addTask添加到启动器中,这样还可以避免了在application的onCreate方法中有一大堆初始化的代码。start方法就是开始执行任务,里面的TaskSortUtil类,顾名思义就是对Task排序,看一下里面的getSortResult方法,会生成任务的有向无环图进行拓扑排序。这一部分笔者受能力所限,就不过多分析了,文末会附上启动器的相关代码,全部在launchStarter包下。可自行查阅和进一步封装。 Graph类topologicalSort方法,就是排序算法的具体逻辑。 排序完成后会生成一个有序集合,比如传入的是A,B,C三个Task,但是A依赖B,那么执行顺序就是 前面说了一大推,只是简单的介绍了启动器的基本原理,其实启动的使用是很简单的,将启动过程中的任务封装为一个个的Task,下面举一个简单的例子 通过这个步骤就把Bugly的初始化封装为一个Task了,同样其它的第三方库的初始化过程,或者启动过程的其它任务都可以通过这种形式封装为一个Task,最终会交给线程池执行。然后在Application的onCreate方法中通过链式调用添加Task,然后启动就行。 如果是要在主线程执行的任务,就继承MainTask,返回值为true,即在主线程执行。 此外如果任务Task之间有依赖关系,即先后执行问题,也很好配置,只需要重载dependsOn方法即可,可将需要在自己之前执行的Task全部添加到集合里面集合,那么集合里面的Task都将在自己前面执行。 至于在某个Task执行之前要确保另外一个Task执行完毕,也很容易实现,在Task里面重载needAwait方法即可,默认返回false。返回true,表示该Task需要在调用dispatcher.await()之前执行完毕,比使用CountDownLatch来的方便,因为启动器的调用类TaskDispatcher里面,对CountDownLatch做了简单的封装。 还有一点需要注意的就是,创建线程池的api中需要制定线程数。这个不能胡乱制定否则对服务的性能影响很大,需要根据任务的性质来决定 根据任务所需要的cpu和io资源的量可以分为 DispatcherExecutor主要是对线程池的初始化配置,可返回不同类型的线程池 在什么时候开始延迟,以及延迟多少时间?这是我们要考虑的问题,常规思路就是在Feed的第一条展示出来之后,利用Handler的postDelay方法,固定一个延迟的时间如比如3秒。先看具体的实现,在adapter中设置接口回调,然后在MainActivity中实现OnFeedShowCallBack 接口,在接口方法中添加延迟初始化任务Task的逻辑。 原有的方式中,DelayInitTaskA和DelayInitTaskB采用sleep的方式模拟postDelay,延迟执行任务。 这样的方案有两大痛点: 更优方案的核心思想:对延迟任务进行分批初始化 如何实现呢?在DelayInitDispatcher 中实例化IdleHander对象,创建一个任务队列mDelayTasks,在消息队列中的消息处理完了的时候,即处于空闲状态了,IdleHandler此时开始工作,回调queueIdle方法,从延迟任务队列中取出Task,进行执行。这样就在不影响用户操作的情况下,实现了延迟初始化。 相对于postDelay的方式,这样就明确了执行时间(系统空闲的时候),另一方面也避免了用户操作时执行,在一定程度上降低了卡顿的风险。方式二:手动打点
public class LauncheTimer{
private static long sTime;
// 记录启动开始时间
public static void startRecord() {
sTime = System.currentTimeMillis();
}
// 记录启动结束时间
public static void endRecord(String string) {
long cost = System.currentTimeMillis() - sTime;
Log.d(string , "cost "+ cost);
}
}
@Override
public void onBindViewHolder(@NonNull final ViewHolder holder, int position) {
if (position == 0 && !mHasRecorded) {
mHasRecorded = true;
holder.layout.getViewTreeObserver().addOnPreDrawListener(new ViewTreeObserver.OnPreDrawListener() {
@Override
public boolean onPreDraw() {
holder.layout.getViewTreeObserver().removeOnPreDrawListener(this);
LaunchTimer.endRecord("FeedShow");
return true;
}
});
}
启动优化工具选择
traceview介绍
Systrace介绍
优雅获取方法耗时
既然如此,那启动过程耗时监测还用这种方式,那是因为启动过程监测只需要埋两个点,不存在上面说的痛点。所以说没有最优的方案,只有最适合的场景。
/**
* 监测方法耗时注解
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface GetTime {
String value();
}
...
/**
* 初始化极光
*/
@GetTime("initJiguang")
private void initJiguang() {
//初始化极光统计
JAnalyticsInterface.init(getApplicationContext());
//设置极光统计调试模式
JAnalyticsInterface.setDebugMode(LogUtil.isDebug);
//初始化极光IM
JMessageClient.init(getApplicationContext());
//注册极光消息回调
JMessageClient.registerEventReceiver(this);
}
...
/**
* 初始化腾讯Bulgy服务
*/
@GetTime("initBugly")
private void initBugly() {
//更多配置参数
//https://bugly.qq.com/docs/user-guide/instruction-manual-android/
//CrashReport.initCrashReport(getApplicationContext(), Constant.BUGLY_APP_KEY, LogUtil.isDebug);
//初始化Bugly所有服务
//包括异常上报
//更新
Bugly.init(getApplicationContext(), Constant.BUGLY_APP_KEY, LogUtil.isDebug);
}
...
/**
* 通过AOP处理添加注解的切面点,实现方法耗时的监测
*/
@Aspect
public class AppContextAop {
@Pointcut("execution(@com.ixuea.courses.mymusic.launch.aop.GetTime * *(..))")
public void methodAnnotatedWithGetTime(){}
@Around("methodAnnotatedWithGetTime()")
public void handleJointPoint(ProceedingJoinPoint joinPoint) {
MethodSignature methodSignature = (MethodSignature)joinPoint.getSignature();
// 获取注解方法所在的类名
String className=methodSignature.getDeclaringType().getSimpleName();
// 获取注解方法的名称
String methodName=methodSignature.getName();
// 注解传入的值
String funName = methodSignature.getMethod().getAnnotation(GetTime.class).value();
long time = System.currentTimeMillis();
try {
joinPoint.proceed();
} catch (Throwable throwable) {
throwable.printStackTrace();
}
Log.d("AppContextAop",funName + " cost "+(System.currentTimeMillis() - time));
}
}

前面说了这么多,只是启动优化需要了解的基本知识,还没有进入正题,下面开始分析启动的优化的具体措施。启动优化的主要思想就是异步执行、延迟执行、懒加载。下面主要分析前两部分,至于懒加载,比较容易,就是某些功能使用场景较少,可以等到需要使用的时候在进行加载执行。异步优化分析
public class MyApplication extends Application {
private static AppContext mContext;
private static final int CPU_COUNT = Runtime.getRuntime().availableProcessors();
private static final int CORE_POOL_SIZE = Math.max(2, Math.min(CPU_COUNT - 1, 4));
...
@Override
public void onCreate() {
super.onCreate();
mContext = this;
ExecutorService service = Executors.newFixedThreadPool(CORE_POOL_SIZE);
long time = System.currentTimeMillis();
service.submit(new Runnable() {
@Override
public void run() {
// 初始化极光推送
initJPush();
}
});
service.submit(new Runnable() {
@Override
public void run() {
// 初始化Bugly
initBugly();
}
});
...
Log.d(TAG, "cost " + (System.currentTimeMillis() - time));
}
}
public class MyApplication extends Application {
private CountDownLatch mCountDownLatch = new CountDownLatch(1);// 参数表示满足条件次数
@Override
public void onCreate() {
super.onCreate();
mContext = this;
ExecutorService service = Executors.newFixedThreadPool(CORE_POOL_SIZE);
long time = System.currentTimeMillis();
service.submit(new Runnable() {
@Override
public void run() {
// 初始化网络加载
initDownLoad();
mCountDownLatch.countDown();
}
});
...
try {
mCountDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
Log.d(TAG, "cost " + (System.currentTimeMillis() - time));
}
}
异步优化方案优化-启动器
/**
* 启动器调用类
*/
public class TaskDispatcher {
...
private CountDownLatch mCountDownLatch;
private AtomicInteger mNeedWaitCount = new AtomicInteger();//保存需要Wait的Task的数量
private List<Task> mNeedWaitTasks = new ArrayList<>();//调用了await的时候还没结束的且需要等待的Task
private volatile List<Class<? extends Task>> mFinishedTasks = new ArrayList<>(100);//已经结束了的Task
private HashMap<Class<? extends Task>, ArrayList<Task>> mDependedHashMap = new HashMap<>();
private AtomicInteger mAnalyseCount = new AtomicInteger();//启动器分析的次数,统计下分析的耗时;
/**
* 进行初始化
* 初始化全局的上下文
*/
public static void init(Context context) {
if (context != null) {
sContext = context;
sHasInit = true;
sIsMainProcess = Utils.isMainProcess(sContext);
}
}
/**
* 添加任务
*/
public TaskDispatcher addTask(Task task) {
if (task != null) {
collectDepends(task);
mAllTasks.add(task);
mClsAllTasks.add(task.getClass());
// 非主线程且需要wait的,主线程不需要CountDownLatch也是同步的
if (ifNeedWait(task)) {
mNeedWaitTasks.add(task);
mNeedWaitCount.getAndIncrement();
}
}
return this;
}
private void collectDepends(Task task) {
if (task.dependsOn() != null && task.dependsOn().size() > 0) {
for (Class<? extends Task> cls : task.dependsOn()) {
if (mDependedHashMap.get(cls) == null) {
mDependedHashMap.put(cls, new ArrayList<Task>());
}
mDependedHashMap.get(cls).add(task);
if (mFinishedTasks.contains(cls)) {
task.satisfy();
}
}
}
}
/**
* 是否需要wait,即CountDownLatch的功能
*/
private boolean ifNeedWait(Task task) {
return !task.runOnMainThread() && task.needWait();
}
/**
* 开始执行任务
* 类比开启线程调用start执行任务
*/
@UiThread
public void start() {
mStartTime = System.currentTimeMillis();
if (Looper.getMainLooper() != Looper.myLooper()) {
throw new RuntimeException("must be called from UiThread");
}
if (mAllTasks.size() > 0) {
mAnalyseCount.getAndIncrement();
printDependedMsg();
mAllTasks = TaskSortUtil.getSortResult(mAllTasks, mClsAllTasks);
mCountDownLatch = new CountDownLatch(mNeedWaitCount.get());
sendAndExecuteAsyncTasks();
DispatcherLog.i("task analyse cost " + (System.currentTimeMillis() - mStartTime) + " begin main ");
executeTaskMain();
}
DispatcherLog.i("task analyse cost startTime cost " + (System.currentTimeMillis() - mStartTime));
}
public void cancel() {
for (Future future : mFutures) {
future.cancel(true);
}
}
/**
* 在主线程执行任务
*/
private void executeTaskMain() {
mStartTime = System.currentTimeMillis();
for (Task task : mMainThreadTasks) {
long time = System.currentTimeMillis();
new DispatchRunnable(task,this).run();
DispatcherLog.i("real main " + task.getClass().getSimpleName() + " cost " +
(System.currentTimeMillis() - time));
}
DispatcherLog.i("maintask cost " + (System.currentTimeMillis() - mStartTime));
}
/**
* 异步任务
*/
private void sendAndExecuteAsyncTasks() {
for (Task task : mAllTasks) {
if (task.onlyInMainProcess() && !sIsMainProcess) {
markTaskDone(task);
} else {
sendTaskReal(task);
}
task.setSend(true);
}
}
/**
* 查看被依赖的信息
*/
private void printDependedMsg() {
DispatcherLog.i("needWait size : " + (mNeedWaitCount.get()));
if (false) {
for (Class<? extends Task> cls : mDependedHashMap.keySet()) {
DispatcherLog.i("cls " + cls.getSimpleName() + " " + mDependedHashMap.get(cls).size());
for (Task task : mDependedHashMap.get(cls)) {
DispatcherLog.i("cls " + task.getClass().getSimpleName());
}
}
}
}
public void executeTask(Task task) {
if (ifNeedWait(task)) {
mNeedWaitCount.getAndIncrement();
}
task.runOn().execute(new DispatchRunnable(task,this));
}
@UiThread
public void await() {
try {
if (DispatcherLog.isDebug()) {
DispatcherLog.i("still has " + mNeedWaitCount.get());
for (Task task : mNeedWaitTasks) {
DispatcherLog.i("needWait: " + task.getClass().getSimpleName());
}
}
if (mNeedWaitCount.get() > 0) {
mCountDownLatch.await(WAITTIME, TimeUnit.MILLISECONDS);
}
} catch (InterruptedException e) {
}
}
public static Context getContext() {
return sContext;
}
public static boolean isMainProcess() {
return sIsMainProcess;
}
}
public class TaskSortUtil {
private static List<Task> sNewTasksHigh = new ArrayList<>();// 高优先级的Task
/**
* 任务的有向无环图的拓扑排序
*
* @return
*/
public static synchronized List<Task> getSortResult(List<Task> originTasks,
List<Class<? extends Task>> clsLaunchTasks) {
long makeTime = System.currentTimeMillis();
Set<Integer> dependSet = new ArraySet<>();
Graph graph = new Graph(originTasks.size());
for (int i = 0; i < originTasks.size(); i++) {
Task task = originTasks.get(i);
if (task.isSend() || task.dependsOn() == null || task.dependsOn().size() == 0) {
continue;
}
for (Class cls : task.dependsOn()) {
int indexOfDepend = getIndexOfTask(originTasks, clsLaunchTasks, cls);
if (indexOfDepend < 0) {
throw new IllegalStateException(task.getClass().getSimpleName() +
" depends on " + cls.getSimpleName() + " can not be found in task list ");
}
dependSet.add(indexOfDepend);
graph.addEdge(indexOfDepend, i);
}
}
List<Integer> indexList = graph.topologicalSort();
List<Task> newTasksAll = getResultTasks(originTasks, dependSet, indexList);
DispatcherLog.i("task analyse cost makeTime " + (System.currentTimeMillis() - makeTime));
printAllTaskName(newTasksAll);
return newTasksAll;
}
@NonNull
private static List<Task> getResultTasks(List<Task> originTasks,
Set<Integer> dependSet, List<Integer> indexList) {
List<Task> newTasksAll = new ArrayList<>(originTasks.size());
List<Task> newTasksDepended = new ArrayList<>();// 被别人依赖的
List<Task> newTasksWithOutDepend = new ArrayList<>();// 没有依赖的
List<Task> newTasksRunAsSoon = new ArrayList<>();// 需要提升自己优先级的,先执行(这个先是相对于没有依赖的先)
for (int index : indexList) {
if (dependSet.contains(index)) {
newTasksDepended.add(originTasks.get(index));
} else {
Task task = originTasks.get(index);
if (task.needRunAsSoon()) {
newTasksRunAsSoon.add(task);
} else {
newTasksWithOutDepend.add(task);
}
}
}
// 顺序:被别人依赖的————》需要提升自己优先级的————》需要被等待的————》没有依赖的
sNewTasksHigh.addAll(newTasksDepended);
sNewTasksHigh.addAll(newTasksRunAsSoon);
newTasksAll.addAll(sNewTasksHigh);
newTasksAll.addAll(newTasksWithOutDepend);
return newTasksAll;
}
private static void printAllTaskName(List<Task> newTasksAll) {
if (true) {
return;
}
for (Task task : newTasksAll) {
DispatcherLog.i(task.getClass().getSimpleName());
}
}
public static List<Task> getTasksHigh() {
return sNewTasksHigh;
}
/**
* 获取任务在任务列表中的index
*/
private static int getIndexOfTask(List<Task> originTasks,
List<Class<? extends Task>> clsLaunchTasks, Class cls) {
int index = clsLaunchTasks.indexOf(cls);
if (index >= 0) {
return index;
}
// 仅仅是保护性代码
final int size = originTasks.size();
for (int i = 0; i < size; i++) {
if (cls.getSimpleName().equals(originTasks.get(i).getClass().getSimpleName())) {
return i;
}
}
return index;
}
}
/**
* 拓扑排序
*/
public Vector<Integer> topologicalSort() {
int indegree[] = new int[mVerticeCount];
for (int i = 0; i < mVerticeCount; i++) {//初始化所有点的入度数量
ArrayList<Integer> temp = (ArrayList<Integer>) mAdj[i];
for (int node : temp) {
indegree[node]++;
}
}
Queue<Integer> queue = new LinkedList<Integer>();
for (int i = 0; i < mVerticeCount; i++) {//找出所有入度为0的点
if (indegree[i] == 0) {
queue.add(i);
}
}
int cnt = 0;
Vector<Integer> topOrder = new Vector<Integer>();
while (!queue.isEmpty()) {
int u = queue.poll();
topOrder.add(u);
for (int node : mAdj[u]) {//找到该点(入度为0)的所有邻接点
if (--indegree[node] == 0) {//把这个点的入度减一,如果入度变成了0,那么添加到入度0的队列里
queue.add(node);
}
}
cnt++;
}
if (cnt != mVerticeCount) {//检查是否有环,理论上拿出来的点的次数和点的数量应该一致,如果不一致,说明有环
throw new IllegalStateException("Exists a cycle in the graph");
}
return topOrder;
}
B—>A—>C, 你依赖别人,就需要等待别人执行完成才能自己执行。接下来就是具体执行任务,sendAndExecuteAsyncTasks()方法表示执行异步任务,而 executeTaskMain()表示执行需要在主线程完成的任务。启动器的具体使用
/**
* 初始化Bugly
*/
public class InitBuglyTask extends Task {
@Override
public void run() {
// 在启动阶段自己真正要实现的代码
CrashReport.initCrashReport(mContext, "注册时申请的APPID", false);
}
}
@Override
public void onCreate() {
super.onCreate();
...
TaskDispatcher dispatcher = TaskDispatcher.createInstance();
dispatcher.addTask(new InitAMapTask())
.addTask(new InitStethoTask())
.addTask(new InitWeexTask())
.addTask(new InitBuglyTask())
.addTask(new InitFrescoTask())
.addTask(new InitUmengTask())
.addTask(new GetDeviceIdTask())
.start();
// 表示某个或多个Task,需要在onCreate方法走完之前,必须执行完毕
dispatcher.await();
...
}
public abstract class InitXXXTask extends MainTask{
@Override
public boolean runOnMainThread() {
return true;
}
@Override
public void run() {
// 具体要执行的任务
...
}
}
/**
* 需要在getDeviceId之后执行
*/
public class InitJPushTask extends Task {
@Override
public List<Class<? extends Task>> dependsOn() {
List<Class<? extends Task>> task = new ArrayList<>();
task.add(GetDeviceIdTask.class);
return task;
}
@Override
public void run() {
JPushInterface.init(mContext);
PerformanceApp app = (PerformanceApp) mContext;
JPushInterface.setAlias(mContext, 0, app.getDeviceId());
}
}
public class InitWeexTask extends Task {
@Override
public boolean needWait() {
return true;
}
@Override
public void run() {
InitConfig config = new InitConfig.Builder().build();
WXSDKEngine.initialize((Application) mContext, config);
}
}
CPU密集型任务: 主要是执行计算任务,响应时间很快,cpu一直在运行,这种任务cpu的利用率很高
IO密集型任务:主要是进行IO操作,执行IO操作的时间较长,这时cpu出于空闲状态,导致cpu的利用率不高
为了合理最大限度的使用系统资源同时也要保证的程序的高性能,可以给CPU密集型任务和IO密集型任务配置一些线程数。
CPU密集型:线程个数为CPU核数。这几个线程可以并行执行,不存在线程切换到开销,提高了cpu的利用率的同时也减少了切换线程导致的性能损耗
IO密集型:线程个数可以较大。其中的线程在IO操作的时候,其他线程可以继续用cpu,提高了cpu的利用率
启动器中也有执行IO密集型Task的线程池和CPU密集型的线程池。也可通过Task的runOn方法重载进行配置。public class InitFrescoTask extends Task {
@Override
public ExecutorService runOn() {
return DispatcherExecutor.getCPUExecutor();
// return DispatcherExecutor.getCPUExecutor();
}
@Override
public void run() {
// 具体要执行的任务代码
...
}
}
public class DispatcherExecutor {
private static ThreadPoolExecutor sCPUThreadPoolExecutor;
private static ExecutorService sIOThreadPoolExecutor;
private static final int CPU_COUNT = Runtime.getRuntime().availableProcessors();
// We want at least 2 threads and at most 4 threads in the core pool,
// preferring to have 1 less than the CPU count to avoid saturating
// the CPU with background work
public static final int CORE_POOL_SIZE = Math.max(2, Math.min(CPU_COUNT - 1, 5));
private static final int MAXIMUM_POOL_SIZE = CORE_POOL_SIZE;
private static final int KEEP_ALIVE_SECONDS = 5;
private static final BlockingQueue<Runnable> sPoolWorkQueue = new LinkedBlockingQueue<>();
private static final DefaultThreadFactory sThreadFactory = new DefaultThreadFactory();
private static final RejectedExecutionHandler sHandler = new RejectedExecutionHandler() {// 一般不会到这里
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
Executors.newCachedThreadPool().execute(r);
}
};
/**
* 返回CPU密集型任务线程池
* @return
*/
public static ThreadPoolExecutor getCPUExecutor() {
return sCPUThreadPoolExecutor;
}
/**
* 返回IO密集型任务线程池
* @return
*/
public static ExecutorService getIOExecutor() {
return sIOThreadPoolExecutor;
}
/**
* The default thread factory.
*/
private static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "TaskDispatcherPool-" +
poolNumber.getAndIncrement() +
"-Thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
static {
sCPUThreadPoolExecutor = new ThreadPoolExecutor(
CORE_POOL_SIZE, MAXIMUM_POOL_SIZE, KEEP_ALIVE_SECONDS, TimeUnit.SECONDS,
sPoolWorkQueue, sThreadFactory, sHandler);
sCPUThreadPoolExecutor.allowCoreThreadTimeOut(true);
sIOThreadPoolExecutor = Executors.newCachedThreadPool(sThreadFactory);
}
}
更优秀的延迟初始化方案
public class NewsAdapter extends RecyclerView.Adapter<NewsAdapter.ViewHolder> {
...
private OnFeedShowCallBack mCallBack;
public void setItems(List<NewsItem> items) {
this.mItems = items;
notifyDataSetChanged();
}
public void setOnFeedShowCallBack(OnFeedShowCallBack callBack) {
this.mCallBack = callBack;
}
...
@Override
public void onBindViewHolder(@NonNull final ViewHolder holder, int position) {
if (position == 0 && !mHasRecorded) {
mHasRecorded = true;
holder.layout.getViewTreeObserver()
.addOnPreDrawListener(new ViewTreeObserver.OnPreDrawListener() {
@Override
public boolean onPreDraw() {
holder.layout.getViewTreeObserver().removeOnPreDrawListener(this);
LogUtils.i("FeedShow");
LaunchTimer.endRecord("FeedShow");
// 延迟初始化的回调接口
if (mCallBack != null) {
mCallBack.onFeedShow();
}
return true;
}
}
});
}
}
public class MainActivity extends AppCompatActivity implements OnFeedShowCallBack{
...
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
...
}
public void onFeedShow() {
// 以下两行是原有方式,延迟执行任务
new DispatchRunnable(new DelayInitTaskA()).run();
new DispatchRunnable(new DelayInitTaskB()).run();
// 优化后的方案
DelayInitDispatcher delayInitDispatcher = new DelayInitDispatcher();
delayInitDispatcher.addTask(new DelayInitTaskA())
.addTask(new DelayInitTaskB())
.start();
}
public class DelayInitTaskA extends MainTask {
@Override
public void run() {
// 模拟一些操作
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
LogUtils.i("DelayInitTaskA finished");
}
}
更优方案
public class DelayInitDispatcher {
// 需要延迟执行的任务队列
private Queue<Task> mDelayTasks = new LinkedList<>();
/**
* queueIdle方法在消息队列中的消息处理完毕时调用,如果返回true,表示让IdleHandler继续存活,
* 如果返回false,就把idleHandler移除。所以根据我们延迟执行的任务队列中是否还有需要的处理
* 的任务,来决定是否让idleHandler继续存活
*/
private MessageQueue.IdleHandler mIdleHandler = new MessageQueue.IdleHandler() {
@Override
public boolean queueIdle() {
if(mDelayTasks.size()>0){
// 一次从队列中取出一个任务,可以避免造成额外性能消耗
Task task = mDelayTasks.poll();
// Runnable调用run方法,较好比一个普通类调用的普通方法,不涉及线程问题。
new DispatchRunnable(task).run();
}
return !mDelayTasks.isEmpty();
}
};
public DelayInitDispatcher addTask(Task task){
mDelayTasks.add(task);
return this;
}
public void start(){
Looper.myQueue().addIdleHandler(mIdleHandler);
}
}
启动器代码链接:https://github.com/mitufengyun/LaunchStarter/tree/master/app/src/main/java/com/example/launch