DenseNet论文阅读(ResNet与DenseNet的区别)
论文:Densely Connected Convolutional Networks
论文链接:https://arxiv.org/pdf/1608.06993.pdf代码的github链接:https://github.com/liuzhuang13/DenseNet
近期提高提高准确率的方向主要有两个,一个是加深网络(就像ResNet那样),一个是加宽网络(就像Inception那样)。而DenseNet(Dense Convolutional Network)则是从feature上入手,把feature应用到极致,在减少参数的同时获得较高的准确率。
随着网络的加深,出现的问题就是梯度消失问题。为了解决这个问题,已经出现了很多种网络,比如ResNet等。这些网络的共同点就是会想办法建立前面层与后面层之间的短路连接。而DenseNet的想法是,在保证层与层之间最大程度的信息传输的前提下,将网络种的所有层连接起来。也就是说,网络中每一层的输入来自于之前所有层的输出。
如果原本有N层,那在传统神经网络中,连接数应该是N。但是在DenseNet中,连接数应该是N(N-1)/2。
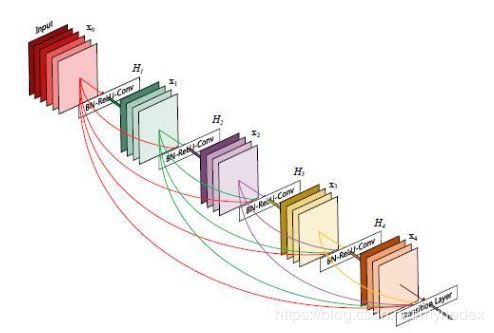
这是一个5-layer的dense block
X0是输入,H1层的输入是X0,输出是X1。
H2层的输入是X0和X1输出是X2
H3层的输入是X0,X1和X2…依此类推
DenseNet和ResNet在结构上有本质的区别。
ResNet:
x l = H l ( x l − 1 ) + x l − 1 x_l=H_l(x_{l-1})+x_{l-1} xl=Hl(xl−1)+xl−1
DenseNet:
x l = H l ( [ x 0 , x 1 , . . . , x l − 1 ] ) x_l=H_l([x_0,x_1,...,x_{l-1}]) xl=Hl([x0,x1,...,xl−1])
l l l代表的是层数, x l x_l xl代表的是l层的输出, H l H_l Hl代表的是一种非线性变换。
从这两个公式可以看出,在ResNet中,l层的输出是(上一层的输出做线性变换后的值)+上一层的输出。这里的加号是值的相加,前后通道数不变。
在DenseNet中,l层的输出是对第0到第l-1层的输出做concatenation(通道融合)之后线性变换的结果。通道数会变多。
前面的图的是一个dense block,下面这个图是一个DenseNet的网络结构图

在这里,在整个网络中使用了3个dense block。相邻block之间的conv和pool层可以看作是转换层,可以调整特征图的大小。
在这里,我认为分成3个是为了调整feture map的大小,让feature map可以逐渐减小。但是在博客上博主写的是这样是为了让各个block中的feature map大小相同,这样在做concatenation的时候就不会产生大小的问题。即要把网络分成dense block和transition layer的原因是transition layer 中的pooling会改变特征图的大小,而dense block中bicultural保持特征图的大小一致。
下图是多种DenseNet的结构图

在这里面,K=32和K=64代表的是feature map的数量。在这里,K都是选的比较小的数,为了防止把网络变得特别宽。在图里面的每一个conv代表的都是BN-ReLU-Conv。在每一个Dense Block中,都使用了1×1卷积进行降维(bottle neck)。为了进一步降维,作者在Translation Layer中又使用了1×1降维。如果使用了bottle neck,那么就记为DenseNet-B,如果使用了Translation layer,就记为DenseNet-C
Dense block里面的1×1卷积核默认把维度变成k*4,translation layer里面的卷积默认是把维度变为原来的一半。
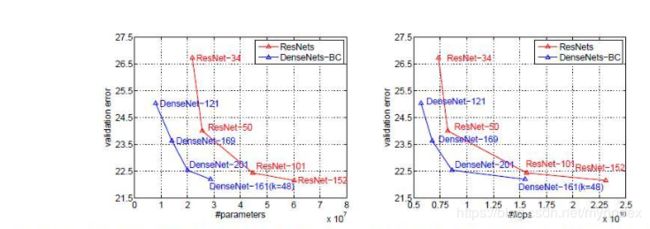
这是在ImageNet上与ResNet的对比。左边是参数复杂度与Top-1错误率的图,右边计算复杂度与TOP-1错误率的图。提升还是很明显的。
DenseNet的优点在于:
1、减轻了vanishing-gradient(梯度消失)
2、加强了feature的传递
3、更有效地利用了feature
4、一定程度上较少了参数数量