聊聊Java泛型类型擦除及Flink类型暗示(type hint)机制
类型擦除的表现
先通过以下两个例子认识类型擦除(type erasure)。
- 例子一

代码很简单,但无法通过编译,提示两个方法签名冲突,因为擦除类型相同。如果去掉其中一个方法,反编译之后的代码如下。
public void foo(List list) { }
- 例子二
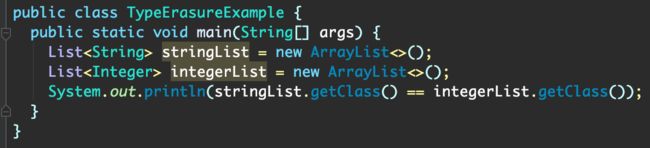
这段代码会返回true。并且Java中只有List.class的写法,没有List
简单解释类型擦除
泛型是高级语言编译器比较头疼的问题,一般来讲要实现泛型有两种方式:
- Code sharing:对同一个原始类型下的泛型类型只生成同一份目标代码(在Java中就是字节码)。
- Code specialization:对每一个泛型类型都生成不同的目标代码。
Java使用的泛型实现是前者,而C++和C#使用的是后者,它们也分别俗称“假”泛型和“真”泛型。因为Code sharing机制的类型擦除,导致程序在运行时对泛型类型没有感知,所以上述例子一的代码反编译后只剩下了List,例子二中的类型比较实际上都是Class的比较。如果Java也采用Code specialization机制(想一想C++的template)的话,所有List
为什么Java要采用Code sharing机制(以及类型擦除)呢?有两点原因:一是Java泛型是到1.5版本才出现的特性,在此之前JVM已经在无泛型的条件下经历了较长时间的发展,如果采用Code specialization,就得对JVM的类型系统做伤筋动骨的改动,并且无法保证向前兼容性。二是Code specialization对每个泛型类型都生成不同的目标代码,如果有10个不同泛型的List,就要生成10份字节码,造成代码膨胀。
由此可见,类型擦除让JVM省了不少事,但是加重了编译器的工作量。编译器必须在运行期之前就进行检查,禁止模糊的或者不合法的泛型使用方式。再举一个例子。

这种用法也是不允许的,换句话说,里氏替换原则不适用于Java的泛型类型参数。这并不难理解:对于一个List
还没完,如果把traverse()方法参数中的List
如果泛型类型有界限,在类型擦除时会根据最左侧的泛型参数来替换,例如下面的泛型类。
class Test {
private T value;
public T getValue() { return value; }
public void setValue(T value) { this.value = value; }
}
类型擦除后就会变成:
class Test {
private Comparable value;
public Comparable getValue() { return value; }
public void setValue(Comparable value) { this.value = value; }
}
同理,如果没有规定T是哪个类的子类或者超类,就会替换为Object。
Flink中的type hint
以Flink自带示例中的SocketWindowWordCount为例(https://github.com/apache/flink/blob/release-1.9/flink-examples/flink-examples-streaming/src/main/java/org/apache/flink/streaming/examples/socket/SocketWindowWordCount.java),如果我们将它的主逻辑改写成Lambda表达式,如下:
DataStream windowCounts = text
.flatMap((String value, Collector out) -> {
for (String word : value.split("\\s")) {
out.collect(new WordWithCount(word, 1L));
}
})
.keyBy("word")
.timeWindow(Time.seconds(5))
.reduce((a, b) ->
new WordWithCount(a.word, a.count + b.count)
);
执行时会抛出如下异常。

这说明程序无法在运行时推断出flatMap()算子的返回类型。为什么之前采用匿名内部类就没有问题?因为匿名内部类会被真正地编译为class文件,而Lambda表达式是在运行时调用invokedynamic指令,亦即在第一次执行其逻辑时才会确定。因此Lambda表达式比起匿名内部类,会丢失更多的类型信息。看一下flatMap()算子的签名:
void flatMap(T value, Collector out);
经过类型擦除,Collector类的泛型参数被抹掉了(The generic type parameters of Collector are missing),自然就会抛出无法确定返回类型的异常。如果我们采用的不是flatMap()算子而是map(),就不会出现这种问题,因为map()的返回类型可以自动推断。
为了克服类型擦除带来的问题,Flink类型系统中提供了类型暗示(type hint)机制。在flatMap()之后调用returns()方法,就可以指定返回类型了。
text.flatMap((String value, Collector out) -> {
for (String word : value.split("\\s")) {
out.collect(new WordWithCount(word, 1L));
}
})
.returns(TypeInformation.of(WordWithCount.class));
但是,如果返回类型本身就有泛型,比如在Flink中常用的元组(TupleX),就得另外换一种写法:
.returns(TypeInformation.of(new TypeHint>() { }))
另外,Eclipse JDT编译器可以在编译期保留Lambda表达式的类型信息,但是不太常用,我们也没有用过。所以在Flink程序中使用Java Lambda表达式时,记得在涉及类型擦除的地方调用returns()方法就好了。