机器学习入门研究(六)-KNN算法
目录
转换器和预估器
转换器
预估器
KNN算法
定义
算法伪代码描述
k值的选择
几个距离计算
实例
sklearn中的API
实例
优缺点
转换器和预估器
转换器
主要用于特征工程。
我们之前在特征工程中介绍了好几个转换器,像DictVectorizer、StandardScaler等。这些转换器类都是继承Transformer。在使用的过程中我们的一般步骤如下:
(1)实例化一个转换器
(2)调用fit_transform()得到最后的结果
那在调用这个fit_transform()有哪几个过程呢?我们举例StandardScaler,我们知道该转换器的作用就是将数据进行无量纲化,其原理就是将通过下面的公式 将原数据进行标准化。
将原数据进行标准化。
fit():就是计算每一列的平均值、标准差
transform():就是调用进行最终转换。
fit、transform、fit_transform区别
(1)fit、transform仅仅是数据处理的两个环节,fit_transform是两个一起的调用
- 数据预处理
像归一化MinMaxScaler、标准化StandardScaler等,fit、transform在这两个环节的作用:
- fit:计算训练集的均值、方差、最大值、最小值等
- transform:在fit的基础上进行标准化、归一化等,完成最后的转换
- fit_transform:就是既包括计算又包括转换
通常在进行数据预处理的时候,需要对训练数据进行fit_transform(train_data),对测试数据进行transform(test_data),例如:
# 实例化转换器类
scaler = MinMaxScaler()
# 调用fit_transform进行转换
x_train = scaler.fit_transform(x_train)
x_test = scaler.fit_transform(x_test)
- 算法调用
sklearn中封装的各种算法使用之前都要fit,然后在进行各种API方法的调用。而transform仅仅是其中的API的一个方法。
像特征提取中的统计文本词频CountVectorizer在这两个环节中的作用如下:
- fit:根据规则进行统计操作,比如过滤停用词、生成有价值的词汇表等
- transform:在fit的基础上将符合的词汇表转换成词频矩阵
- fit_transform:就是既包括计算又包括转换
(2)必须先用fit_transform(train_data),然后在进行transform(test_data)
(3)如果先用fit_transform(train_data),然后在进行fit_transform(test_data),但是两个结果和(2)中提到的不是在同一个标准下,有明显的差别。
后续补充:
因为fit()就是以train_data里面的所有数据生成一种对于这些数据的标准,所以对于train_data数据fit()之后,还需要在进行transform()来进行转换,所以在对test_data在进行转换的时候,不能在进行fit(),否则会又以test_data里面的数据生成新的标准,对于train_data和test_data两个转换的标准不在一样。
预估器
主要用于算法实现。在sklearn中封装的算法API

这些类都是继承于Estimator,我们在使用过程中的一般步骤如下:
(1)实例化一个Estimator实例
(2)调用fit(x_train,y_train)计算最后的结果
在该过程中主要完成的将训练集的特征和目标值代入(1)中实例化的算法,完成训练,在调用完fit()方法之后,则模型生成。
(3)评估模型,主要有两种方式
- 直接对比真实值和预测值
y_predict = Estimator.predict(x_test)
y_test == y_predict- 计算准确率等其他参数
可参见https://blog.csdn.net/nihaomabmt/article/details/102741743
后面主要去学习其中的涉及的各种算法
KNN算法
定义
K Nearest Neighbor。如果一个样本在特征空间的k个最相似(即特征空间中最邻近)的样本的大多数属于某一个类别,则该昂本也属于该类别
简单的说就是根据邻居推断出类别
算法伪代码描述
(1)计算已知类别数据集中点与当前点之间的距离
(2)按照距离进行递增排序
(3)选取距离最小的k个点
(4)确定前k个点所在类别的频率
(5)返回前k个点出现最高频率的类别作为当前点的预测分类
k值的选择
k值太小,譬如为1,如果恰好该点为异常点,如果恰好与异常值点相似,则引起类别判断错误。k值太小,容易受异常值的影响
k值太大,则学习的近似误差也大,容易受样本不均衡的影响
所以k要选择合适的参数
几个距离计算
在算法的伪代码中我们可以看到要计算点与点的距离,主要介绍几种距离的计算过程。
- (1)欧式距离
二维空间中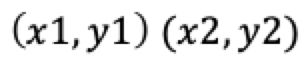 ,则欧式距离如下:
,则欧式距离如下:

n维空间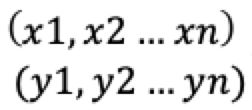 ,则欧式距离如下:
,则欧式距离如下:

- (2)余弦值cos
机器学习中可以把两个点看成空间中的两个向量
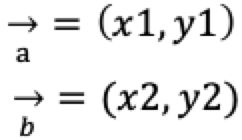
二维空间的余弦值cos距离为:

n维空间的余弦值cos距离为:

- (3)曼哈顿距离(Manhattan distance)
也被称为曼哈顿街区距离
在二维空间上的曼哈顿距离为:

在n维空间的曼哈顿距离为:

我们可以看到其实就是两个点在各个维度上的距离之和

网上有这么一张图来对比欧式距离和曼哈顿距离。
- (4)切比雪夫距离
对应各个维度上的距离的最大值
在二维空间上的切比雪夫距离为

在n维空间的切比雪夫距离为

- (5)明可夫斯基距离
距离的总称。公式如下
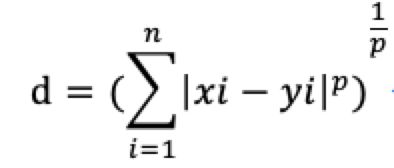
其中p>0
当p=1时,曼哈顿距离
当p=2时,欧式距离
当p= 时,切比雪夫距离
时,切比雪夫距离
p值越大,越容易受异常值越厉害
实例
sklearn中的API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,weights='uniform',
algorithm='auto', leaf_size=30,p=2, metric='minkowski', metric_params=None, n_jobs=None)其中参数如下:
| 参数 | 含义 |
| n_neighbors | 邻居数,就是上面提到的k的取值,默认为5 |
| weights | 预测的权重。 默认的为uniform:统一权重。在每个邻居区域里的点的权重都是一样的 distance:权重点等于他们距离的倒数。更近的邻居对预测点影响大 [callable]:自定义的方法,传入的是距离数组,返回的是相同形状的包含权重的数组 |
| algorithm | 对邻居进行排序时用到的算法。 默认为auto:根据传递给fit()的值来决定最合适的算法 ball_tree BallTree算法 kd_tree KDTree算法 brute 暴力搜索 |
| leaf_size | 叶子的数量,默认为30。和algorithm配合使用,传入的是ball_tree或kd_tree的时候,关系到BallTree或KDTree的速度以及所需要的内存大小 |
| p | 计算距离公式的选择,默认为2,即上面提到的欧式距离 |
| metric | 用于树的距离矩阵 |
| metric_params | 矩阵参数 |
| n_jobs | 搜索邻居可并行的任务数量,默认为1 |
实例
按照一个机器学习的基本流程来看下这个KNN算法的实际应用
- (1)获取数据
我们使用sklearn.datasets鸢尾花数据集,使用KNN算法来进行分类。根据数据集的四个特征来推断属于的鸢尾花的类别。
该数据集中提供的数据集中有四个特征:花萼的长度(sepal length),花萼的宽度 (sepal width), 花瓣的长度(petal length), 花瓣的宽度(petal width)来推断该鸢尾花属于哪个种类。
其中包括的三个类别为:0(山鸢尾 setosa)、1(变色鸢尾 versicolor)、2(维吉尼亚鸢尾 virginica)。
通过sklearn中的load_iris()来进行获取该数据集
from sklearn.datasets import load_iris
# 从sklearn.datasets中获取到鸢尾花的数据集,使用load_*方法说明是一个比较小的数据集
iris = load_iris()
print("每个类别下前10个样本的鸢尾花的数据集")
print(iris["feature_names"])
print(iris["data"][0:10])
print("输出的数据集的对应着标签:")
print(iris.target[0:10])
print("每个类别下前10个样本的鸢尾花的数据集")
print(iris.data[50:60])
print("输出的数据集的对应着标签:")
print(iris.target[50:60])
print("每个类别下前10个样本的鸢尾花的数据集")
print(iris.data[100:110])
print("输出的数据集的对应着标签:")
print(iris.target[100:110])
print("返回所有的样本数为:{:}".format(len(iris["data"])))
print(iris.target_names)这里采用的是load_*来获取的数据集,说明返回的是一个比较小的数据集,默认返回的类别为3个,每个类别都50个样本,一共返回150个样本,每个样本有4个特征。我们看下输出的数据为:
每个类别下前10个样本的鸢尾花的数据集
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]]
输出的数据集的对应着标签:
[0 0 0 0 0 0 0 0 0 0]
每个类别下前10个样本的鸢尾花的数据集
[[7. 3.2 4.7 1.4]
[6.4 3.2 4.5 1.5]
[6.9 3.1 4.9 1.5]
[5.5 2.3 4. 1.3]
[6.5 2.8 4.6 1.5]
[5.7 2.8 4.5 1.3]
[6.3 3.3 4.7 1.6]
[4.9 2.4 3.3 1. ]
[6.6 2.9 4.6 1.3]
[5.2 2.7 3.9 1.4]]
输出的数据集的对应着标签:
[1 1 1 1 1 1 1 1 1 1]
每个类别下前10个样本的鸢尾花的数据集
[[6.3 3.3 6. 2.5]
[5.8 2.7 5.1 1.9]
[7.1 3. 5.9 2.1]
[6.3 2.9 5.6 1.8]
[6.5 3. 5.8 2.2]
[7.6 3. 6.6 2.1]
[4.9 2.5 4.5 1.7]
[7.3 2.9 6.3 1.8]
[6.7 2.5 5.8 1.8]
[7.2 3.6 6.1 2.5]]
输出的数据集的对应着标签:
[2 2 2 2 2 2 2 2 2 2]
返回所有的样本数为:150
['setosa' 'versicolor' 'virginica']- (2)数据处理
我们拿到数据集之后,一般要把数据集分成训练集和测试集,通过测试集来看看我们模型训练的效果。同样sklearn中提供API将数据集划分为训练集和测试集
sklearn.model_selection.train_test_split(train_data,train_target,test_size, random_state)其中参数如下:
| 属性 | 含义 |
| train_data | 被划分的样本的特征 |
| train_target | 被划分的样本的标签 |
| test_size | 0~1之间,样本的占比;如果是整数,则是样本的数量 |
| random_state | 随机数的种子。在重复实验的时候,保证得到一组一样的随机数。如果有值,在其他参数一致的情况下,产生的随机数是一样的。如果是0或者不填,每次产生的随机数会不一致。 |
返回值为:
训练子集的特征,测试子集的特征,训练子集的标签,测试子集的标签
from sklearn.model_selection import train_test_split
# 数据分成训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=10)
print("前10个样本的训练集的特征值x_train")
print(x_train[0:10])
print("前10个样本的训练集的标签y_train")
print(y_train[0:10])前10个样本的训练集的特征值x_train
[[6.6 2.9 4.6 1.3]
[6.2 2.9 4.3 1.3]
[7.2 3. 5.8 1.6]
[5.8 2.8 5.1 2.4]
[6.3 2.5 5. 1.9]
[4.6 3.2 1.4 0.2]
[6.7 3.3 5.7 2.1]
[6.9 3.2 5.7 2.3]
[7.7 2.6 6.9 2.3]
[6.9 3.1 5.1 2.3]]
前10个样本的训练集的标签y_train
[1 1 2 2 2 0 2 2 2 2]- (3)特征工程
有了训练集之后,为了防止每个特征的数量级差别造成该特征无法对预测类别起作用,所以需要将数据进行无量纲化,一般有归一化和标准化,标准化会比归一化更不容易受异常值的影响。其中的一些方法可以参见机器学习入门研究(六)-特征工程之特征预处理
from sklearn.preprocessing import StandardScaler
# 为防止数据量级差别比较大,所以将数据进行无量纲化,这里采用标准化
standard = StandardScaler()
x_train = standard.fit_transform(x_train)
print("前10个样本的训练集的特征值x_train")
print(x_train[0:10])
x_test = standard.fit_transform(x_test)看下标准化之后的数值如下:
前10个样本的训练集的特征值x_train
[[ 0.87110766 -0.39891058 0.46061935 0.10579946]
[ 0.39378839 -0.39891058 0.29192864 0.10579946]
[ 1.58708656 -0.16765807 1.13538218 0.49445053]
[-0.08353087 -0.63016309 0.74177053 1.53085339]
[ 0.51311821 -1.32392062 0.68554029 0.8831016 ]
[-1.51548867 0.29484695 -1.3387482 -1.31925447]
[ 0.99043748 0.52609946 1.07915194 1.14220232]
[ 1.22909711 0.29484695 1.07915194 1.40130303]
[ 2.18373564 -1.09266811 1.75391477 1.40130303]
[ 1.22909711 0.06359444 0.74177053 1.40130303]]- (4)训练模型
1)有了训练集和测试集之后,就可以代入到KNN算法进行训练模型。其步骤就是:
2)实例化预估器
3)将训练集代入到预估器进行训练
4)将测试集代入到模型进行预测
其代码如下:
# 传入到knn进行训练,得到模型
classifier = KNeighborsClassifier(n_neighbors=3)
classifier.fit(x_train, y_train)
# 根据模型进行预测
y_predict = classifier.predict(x_test)
print("测试集中的样本预测之后的标签为:")
print(y_predict)
print("测试集中的样本预测之前的标签为:")
print(y_test)运行之后得到的结果为:
测试集中的样本预测之后的标签为:
[2 2 0 1 0 1 2 1 0 1 2 2 1 0 0 2 1 0 0 0 2 2 2 0 2 0 1 1 1 2]
测试集中的样本预测之前的标签为:
[1 2 0 1 0 1 1 1 0 1 1 2 1 0 0 2 1 0 0 0 2 2 2 0 1 0 1 1 1 2]
输入的测试样本的个数:30- (5)模型评估
在预估器KNeighborsClassifier中提供了score()方法来计算该模型的准确率,通过查看源码可以看到,其实就是在机器学习入门研究(四)-评价指标-自我感觉总结的还不错的在这个里面提到的准确率。另外刚才提到的在划分测试集和训练集的时候会对模型的准确率等评估指标产生影响。
def score(self, X, y, sample_weight=None):
from .metrics import accuracy_score
return accuracy_score(y, self.predict(X), sample_weight=sample_weight)那结合着刚才提到的评估指标,在来复习下这几个评价指标,因为刚开始看的时候,只知道有了预测值和实际值进行比较,但不清楚是怎么来的,就想着找一个例子来看看 。现在通过前四步拿到了预测值和实际值,接下来具体分析下上次提到的这几个评价指标。
1)混淆矩阵
预测值和实际值如下:

根据之前总结过的总结这个混淆矩阵为(鸢尾花的种类我们用0、1、2表示),统计的表格如下:
| 预测类型 实际类别 |
0 | 1 | 2 |
| 0 | 10 | ||
| 1 | 9 | 4 | |
| 2 | 7 |
我们的代码如下:
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_curve, roc_auc_score, confusion_matrix
matrix = confusion_matrix(y_test,y_predict,labels=[0,1,2])
print("matrix:")
print(matrix)通过程序运行之后的矩阵如下:
matrix:
[[10 0 0]
[ 0 9 4]
[ 0 0 7]]我们看到跟我们推算的结果是一致的。
2)准确率
就是所有的被正确分类的样本占所有样本的比例。在预估器值的score()返回值是同一个值
accuracy=(10+9+7)/30=0.8666666666666667
通过代码:
accuracy = accuracy_score(y_test, y_predict)
print("accuracy:")
print(accuracy)输出的结果如下:
accuracy:
0.86666666666666673)精确率
就是被正确分类的样本占所有被预测为类别的样本的比例。也就是该类别占所在类别的列的比例
其中
precision0=10/(10+0+0)=1.0
precision1=9/(0+9+0)=1.0
precision2=7/(0+4+7)=0.63636363
代码如下:
precision = precision_score(y_test, y_predict, average=None)
print("precision:")
print(precision)输出的结果如下:
precision:
[1. 1. 0.63636364]4)召回率
就是被正确分类的样本占实际为该样本的比例。也就是该类别占该类别所在行的比例
recall0=10/(10+0+0)=1.0
recall1=9/(0+9+4)= 0.69230769
recall2=7/(0+0+7)=1.0
代码如下:
recall = recall_score(y_test, y_predict, average=None)
print("recall:")
print(recall)运行结果如下:
recall:
[1. 0.69230769 1. ]5)F1-score
F1-Score为精确率和召回率的调和均值。计算公式为:

公式计算过程忽略,上面几个都计算正确,这个代入公式肯定也是正确的,直接看运行结果
代码如下:
f1 = f1_score(y_test, y_predict, average=None)
print("f1:")
print(f1)运行过程如下:
f1:
[1. 0.81818182 0.77777778]6)ROC曲线和AUC
根据ROC曲线的生成原理,需要分类器得到每一个测试样本的分概率输出,然而没有找到比较好的knn概率输出,并且现在在sklearn中没有对应的decision_function()方法。所以这里以后在理解这个地方。暂时还无法理解
上述几个值都是越接近1越好。
- (6)应用
直接把经过特征工程处理之后的数据代入模型,即可得出对应分类。
优缺点
- 优点:
简单易于理解,基本流程就是算距离,然后对距离进行排序
- 缺点:
计算量大,对测试样本分类时,需要计算每一个点与点之间的距离
受k值影响比较大,k值太小,容易受异常值的影响;k值太大,容易受样本不均衡的影响
- 使用场景
小数据场景,几千~几万样本