摘要:Hadoop,是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。该平台使用的是面向对象编程语言Java实现的,具有良好的可移植性。本文将介绍Hadoop相关的技术框架以及搭建Hadoop平台的详细过程。

文章概览
- Hadoop简介
- Hadoop体系结构
- HDFS分布式文件系统
- MapReduce编程模型
- Hadoop平台搭建
Hadoop简介
Hadoop体系结构
[图片上传失败...(image-b303b6-1543260810471)]
HDFS分布式文件系统
在正式讨论HDFS分布式文件系统之前,我们首先了解一下什么是文件系统。文件系统实际上可以看作是一个用户与底层数据交互的一个接口,对于底层数据而言它定义了数据的存储和组织方式,同时也提供了存储空间的管理功能;而对于用户而言它使用文件和树形目录的抽象逻辑概念代替了存储设备中块的概念,用户使用文件系统来操作数据不必关心数据实际保存在硬盘(或者光盘)的地址为多少的数据块上,只需要记住这个文件的所属目录和文件名(关于文件系统更详细的介绍参见维基百科和这篇博客)。传统文件系统适用于存储容量小等一些没有特殊要求的应用场景。
但是随着信息技术的不断发展,人们可以获取的数据成指数倍的增长,单纯通过增加硬盘个数来扩展计算机文件系统的存储容量的方式,在容量大小、容量增长速度、数据备份、数据安全等方面的表现都差强人意。为了满足这些特殊应用场景的需求,分布式文件系统应运而生。分布式文件系统可以有效解决数据的存储和管理难题:将固定于某个地点的某个文件系统,扩展到任意多个地点/多个文件系统,众多的节点组成一个文件系统网络。每个节点可以分布在不同的地点,通过网络进行节点间的通信和数据传输。人们在使用分布式文件系统时,无需关心数据是存储在哪个节点上、或者是从哪个节点从获取的,只需要像使用本地文件系统一样管理和存储文件系统中的数据(我们需要知道的是在分布式文件系统的每个数据结点上,数据的存储方式是建立在传统文件系统的基础上的,所谓分布式文件系统它提供的是数据宏观上的存储和管理方式)。
HDFS是分布式文件系统的一种,它采用master/slave架构,一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。它可以处理超大规模的数据,并且提供了良好的容错机制,下图是HDFS的基本结构。
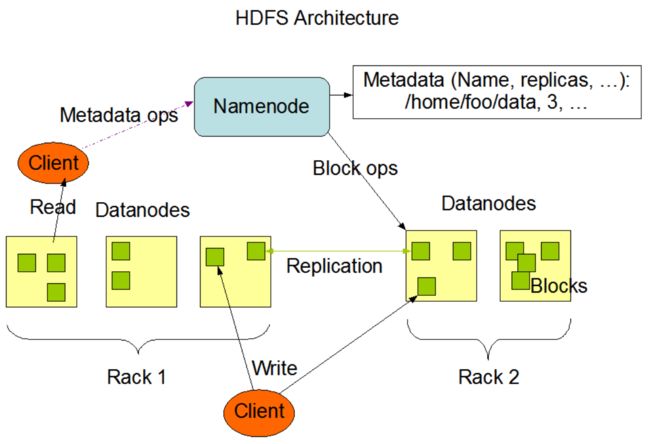
- NameNode: 可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等,NameNode会将文件系统的Meta-data存储到内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
- Datanode: DataNode是文件存储的基本单元,他将Block存储在本地文件系统中,保存了Block的meta-data,同时周期性的将所有存在的Block信息发送给NameNode。slave存储实际的数据块,执行数据块的读写。
- Client: 文件切分与NameNode的交互,获取文件位置信息;与DataNode交互,读取或者写入数据;管理HDFS;访问HDFS。
HDFS读取数据流程
客户端将要读取的文件路径发送给Namenode,Namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应Datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件
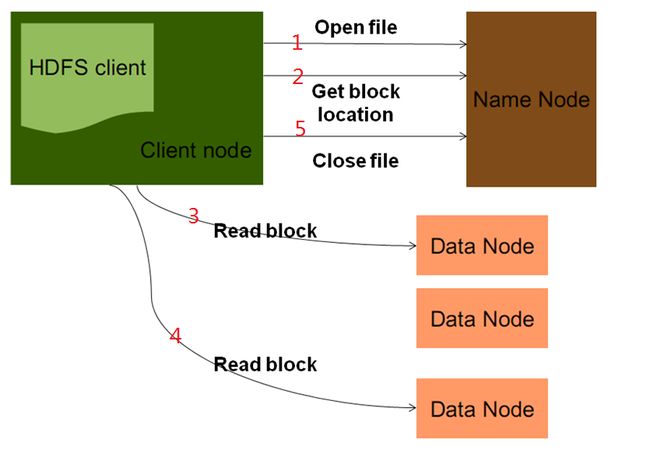
HDFS写数据流程
客户端要向HDFS写数据,首先要跟Namenode通信以确认可以写文件并获得接收文件block的Datanode,然后,客户端按顺序将文件逐个block传递给相应Datanode,并由接收到block的Datanode负责向其他Datanode复制block的副本。

MapReduce编程模型
MapReduce的诞生也是由于对大规模数据处理的需求。在大型的互联网公司,比如说Google、亚马逊等,在他们的平台上每天都会产生大量的数据,单个的处理器不可能在有限的时间内完成计算。根据多线程和并行计算的启发,我们可以将这些计算分布在成百上千的的机器上,这些机器集群就可以看作硬件资源池,将并行的任务拆分,然后交由每一个空闲机器资源去处理,能够极大地提高计算效率。但是由此而来引发的问题是在这个分布式计算系统中应该如何合理的处理并行计算?如何分发数据?如何处理错误?为了避免对这些问题的考虑,我们希望获得这样一个抽象模型,在这个模型中我们只需要关注我们希望执行的任务,而不必关心并行计算、容错、数据分布、负载均衡等复杂的细节,MapReduce就是这样一个抽象模型。
MapReduce 是一个编程模型,也是一个处理和生成超大数据集的算法模型的相关实现。用户首先创建一 个 Map 函数处理一个基于 key/value pair 的数据集合, 输出中间的基于 key/value pair 的数据集合; 然后再创建 一个 Reduce 函数用来合并所有的具有相同中间 key 值的中间 value 值。MapReduce 架构的程序能够在大量的普通配置的计算机上实现并行化处理。这个系统在运行时只关心: 如何分割输入数据,在大量计算机组成的集群上的调度,集群中计算机的错误处理,管理集群中计算机之间 必要的通信。采用 MapReduce 架构可以使那些没有并行计算和分布式处理系统开发经验的程序员有效利用分布式系统的丰富资源。
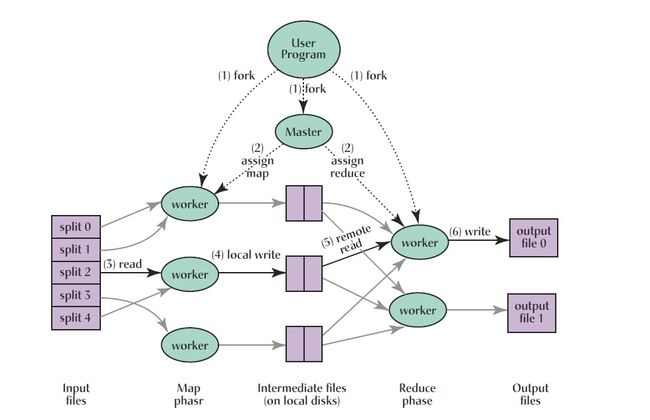
执行过程
- 用户程序首先调用的 MapReduce 库将输入文件分成 M 个数据片度,每个数据片段的大小一般从 16MB 到 64MB(可以通过可选的参数来控制每个数据片段的大小)。然后用户程序在机群中创建大量 的程序副本。
- 这些程序副本中的有一个特殊的程序–master。副本中其它的程序都是 worker 程序,由 master 分配 任务。有 M 个 Map 任务和 R 个 Reduce 任务将被分配,master 将一个 Map 任务或 Reduce 任务分配 给一个空闲的 worker。
- 被分配了 map 任务的 worker 程序读取相关的输入数据片段,从输入的数据片段中解析出 key/value pair,然后把 key/value pair 传递给用户自定义的 Map 函数,由 Map 函数生成并输出的中间 key/value pair,并缓存在内存中。
- 缓存中的 key/value pair 通过分区函数分成 R 个区域,之后周期性的写入到本地磁盘上。缓存的 key/value pair 在本地磁盘上的存储位置将被回传给 master,由 master 负责把这些存储位置再传送给 Reduce worker
- 当 Reduce worker 程序接收到 master 程序发来的数据存储位置信息后, 使用 RPC 从 Map worker 所在的磁盘上读取这些缓存数据。当 Reduce worker 读取了所有的中间数据后,通过对 key 进行排序 后使得具有相同 key 值的数据聚合在一起。由于许多不同的 key 值会映射到相同的 Reduce 任务上, 因此必须进行排序。如果中间数据太大无法在内存中完成排序,那么就要在外部进行排序。
- Reduce worker 程序遍历排序后的中间数据, 对于每一个唯一的中间 key 值, Reduce worker 程序将这 个 key 值和它相关的中间 value 值的集合传递给用户自定义的 Reduce 函数。Reduce 函数的输出被追加到所属分区的输出文件。
- 当所有的 Map 和 Reduce 任务都完成之后,master 唤醒用户程序。在这个时候,在用户程序里对 MapReduce 调用才返回。
Hadoop平台搭建
Hadoop有三种安装模式:本地模式安装、伪分布模式安装和完全分布式安装。本文主要介绍Hadoop完全分布式安装,真实环境下都是以这种方式部署(1台Master,2台Slave)。
部署环境
- Hadoop2.8.5
- VMware14
- ubuntu16.04
- jdk11.01
第一步:安装ubuntu
虚拟机的安装教程网上很多,这里不在赘述,注意这里只需要安装一个虚拟机,虚拟机的网络连接方式为NAT。
第二步:在虚拟机中安装jdk
我使用的jdk版本是jdk11.01,建议使用jdk1.8。jdk安装完成后需要配置环境变量,jdk的默认安装路径是
/usr/lib/jvm/jdk-11.01
编辑用户目录下.bashrc文件,在文件末尾添加
export JAVA_HOME=/usr/lib/jvm/jdk-11.01
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
第三步:克隆虚拟机
利用VMware的克隆功能,克隆两个虚拟机
第四步:修改hostname文件
现在我们得到三个一模一样的虚拟机,我们选取其中一个虚拟机为Master,其余两个虚拟机分别为Slave。修改Master主机的hostname为Master,两个Slave的hostname分别为Slave1和Slave2,hosts文件的路径为
/etc/hostname
第五步:配置静态IP
分别查看三台主机的IP地址,然后修改hosts文件,将三台主机的hostname以及对于的IP添加到hosts文件中,hosts文件路径为,三台主机都要进行同样的操作。
/etc/hosts
在我的系统中,三台主机的IP如图所示
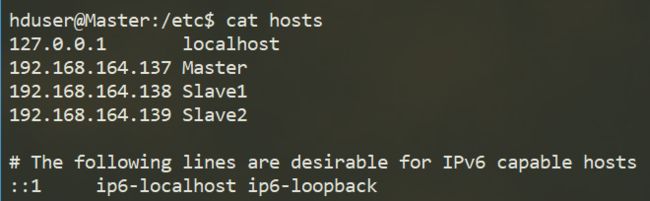
第六步:建立Hadoop运行账号
在三台主机上都要建立一个hadoop用户组,并在用户组中添加名为hduser的用户,具体操作如下。
sudo groupadd hadoop #建立hadoop用户组
sudo useradd -s /bin/bash -d /home/hduser -m hduser -g hadoop #添加hduser,指定用户目录
sudo passwd hduser #修改hduser用户密码
sudo adduser hduser sudo #赋予hduser管理员权限
su hduser #切换到hduser用户
第七步:配置ssh免密登录
ubuntu默认安装了ssh客户端,但没有安装ssh服务器,配置之前先在三台主机中安装ssh-server
sudo apt-get install
接着在Master主机中执行如下命令
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa #生成ssh公钥和私钥
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #添加公钥到已认证的key中
在两台Slave主机中的用户目录下新建.ssh文件夹,然后将Master中的id_rsa.pub文件复制到两台Slave主机的.ssh文件夹下,执行如下命令
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #添加公钥到已认证的key中
最后验证是否可以通过Master免密登录两台Slave主机。
第八步:下载并解压Hadoop
三台主机都要进行该操作,在用户目录下建立名为hadoop2.8.5的目录,将文件解压到该目录下。
第九步:修改配置文件
三台主机都要进行该操作
-
修改hadoop-env.sh文件,添加JAVA_HOME。(~/hadoop/hadoop2.8.5/etc/hadoop/hadoop-env.sh)
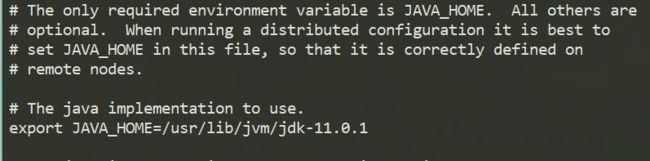 avatar
avatar -
修改core-site.cml文件,添加如下内容。(~/hadoop/hadoop2.8.5/etc/hadoop/core-site.cml)
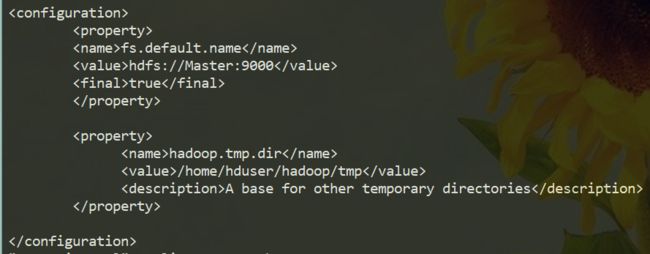 avatar
avatar -
修改hdfs-site.xml文件,添加如下内容。(~/hadoop/hadoop2.8.5/etc/hadoop/hdfs-site.xml)
 avatar
avatar -
修改mapred-site.xml.template文件,添加如下内容。(~/hadoop/hadoop2.8.5/etc/hadoop/mapred-site.xml.template)
 avatar
avatar 修改slaves文件,将两台Slave主机名添加进去即可。(~/hadoop/hadoop2.8.5/etc/hadoop/slaves)
-
修改/etc/profile文件,添加如下内容
export JAVA_HOME=/usr/lib/jvm/jdk-11.0.1 export HADOOP_INSTALL=/home/hduser/hadoop/hadoop-2.8.5 export PATH=$PATH:${HADOOP_INSTALL}/bin:${HADOOP_INSTALL}/sbin:${JAVA_HOME}/bin然后执行
source /etc/profile检查hadoop是否安装成功
 avatar
avatar
第十步:格式化namenode,并启动集群
在Master主机中执行以下命令
hadoop namenode -format #格式化namenode
start-all.ssh #启动集群
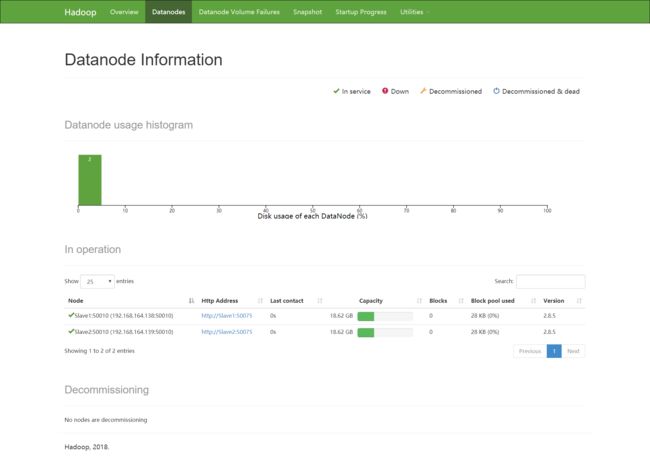
在ubuntu地址栏中输入http:Master:50070,可以看到Slave结点的相关信息