海量存储系列之八、九、十
http://rdc.taobao.com/team/jm/archives/1387
首先来回答一个问题:为什么在磁盘中要使用b+树来进行文件存储呢?
原因还是因为树的高度低得缘故,磁盘本身是一个顺序读写快,随机读写慢的系统,那么如果想高效的从磁盘中找到数据,势必需要满足一个最重要的条件:减少寻道次数。
我们以平衡树为例进行对比,就会发现问题所在了:
先上个图

这是个平衡树,可以看到基本上一个元素下只有两个子叶节点
抽象的来看,树想要达成有效查找,势必需要维持如下一种结构:
树的子叶节点中,左子树一定小于等于当前节点,而当前节点的右子树则一定大于当前节点。只有这样,才能够维持全局有序,才能够进行查询。
这也就决定了只有取得某一个子叶节点后,才能够根据这个节点知道他的子树的具体的值情况。这点非常之重要,因为二叉平衡树,只有两个子叶节点,所以如果想找到某个数据,他必须重复更多次“拿到一个节点的两个子节点,判断大小,再从其中一个子节点取出他的两个子节点,判断大小。”这一过程。
这个过程重复的次数,就是树的高度。那么既然每个子树只有两个节点,那么N个数据的树的高度也就很容易可以算出了。
平衡二叉树这种结构的好处是,没有空间浪费,不会存在空余的空间,但坏处是需要取出多个节点,且无法预测下一个节点的位置。这种取出的操作,在内存内进行的时候,速度很快,但如果到磁盘,那么就意味着大量随机寻道。基本磁盘就被查死了。
而b树,因为其构建过程中引入了有序数组,从而有效的降低了树的高度,一次取出一个连续的数组,这个操作在磁盘上比取出与数组相同数量的离散数据,要便宜的多。因此磁盘上基本都是b树结构。
不过,b树结构也不是完美的,与二叉树相比,他会耗费更多的空间。在最恶劣的情况下,要有几乎是元数据两倍的格子才能装得下整个数据集(当树的所有节点都进行了分裂后)。
以上,我们就对二叉树和b树进行了简要的分析,当然里面还有非常多的知识我这里没有提到,我希望我的这个系列能够成为让大家入门的材料,如果感兴趣可以知道从哪里着手即可。如果您通过我的文章发现对这些原来枯燥的数据结构有了兴趣,那么我的目标就达到了: )
在这章中,我们还将对b数的问题进行一下剖析,然后给出几个解决的方向
其实toku DB的网站上有个非常不错的对b树问题的说明,我在这里就再次侵权一下,将他们的图作为说明b树问题的图谱吧,因为真的非常清晰。
http://tokutek.com/downloads/mysqluc-2010-fractal-trees.pdf

B树在插入的时候,如果是最后一个node,那么速度非常快,因为是顺序写。
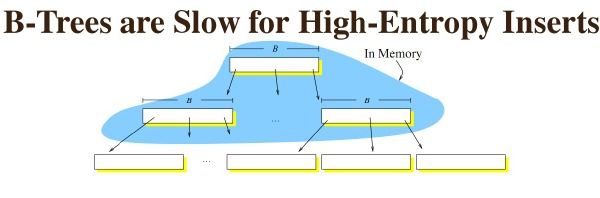
但如果有更新插入删除等综合写入,最后因为需要循环利用磁盘块,所以会出现较多的随机io.大量时间消耗在磁盘寻道时间上。

如果是一个运行时间很长的b树,那么几乎所有的请求,都是随机io。因为磁盘块本身已经不再连续,很难保证可以顺序读取。
以上就是b树在磁盘结构中最大的问题了。
那么如何能够解决这个问题呢?
目前主流的思路有以下几种
1. 放弃部分读性能,使用更加面向顺序写的树的结构来提升写性能。
这个类别里面,从数据结构来说,就我所知并比较流行的是两类,
一类是COLA(Cache-Oblivious Look ahead Array)(代表应用自然是tokuDB)。
一类是LSM tree(Log-structured merge Tree)或SSTABLE
(代表的数据集是cassandra,hbase,bdb java editon,levelDB etc.).
2. 使用ssd,让寻道成为往事。
我们在这个系列里,主要还是讲LSM tree吧,因为这个东西几乎要一桶浆糊了。几乎所有的nosql都在使用,然后利用这个宣称自己比mysql的innodb快多少多少倍。。我对此表示比较无语。因为nosql本身似乎应该是以省去解析和事务锁的方式来提升效能。怎么最后却改了底层数据结构,然后宣称这是nosql比mysql快的原因呢?
毕竟Mysql又不是不能挂接LSM tree的引擎。。。
好吧,牢骚我不多说,毕竟还是要感谢nosql运动,让数据库团队都重新审视了一下数据库这个产品的本身。
那么下面,我们就来介绍一下LSM Tree的核心思想吧。
首先来分析一下为什么b+树会慢。
从原理来说,b+树在查询过程中应该是不会慢的,但如果数据插入比较无序的时候,比如先插入5 然后10000然后3然后800 这样跨度很大的数据的时候,就需要先“找到这个数据应该被插入的位置”,然后插入数据。这个查找到位置的过程,如果非常离散,那么就意味着每次查找的时候,他的子叶节点都不在内存中,这时候就必须使用磁盘寻道时间来进行查找了。更新基本与插入是相同的

那么,LSM Tree采取了什么样的方式来优化这个问题呢?
简单来说,就是放弃磁盘读性能来换取写的顺序性。
乍一看,似乎会认为读应该是大部分系统最应该保证的特性,所以用读换写似乎不是个好买卖。但别急,听我分析之。
1. 内存的速度远超磁盘,1000倍以上。而读取的性能提升,主要还是依靠内存命中率而非磁盘读的次数
2. 写入不占用磁盘的io,读取就能获取更长时间的磁盘io使用权,从而也可以提升读取效率。
因此,虽然SSTable降低了了读的性能,但如果数据的读取命中率有保障的前提下,因为读取能够获得更多的磁盘io机会,因此读取性能基本没有降低,甚至还会有提升。
而写入的性能则会获得较大幅度的提升,基本上是5~10倍左右。
下面来看一下细节
其实从本质来说,k-v存储要解决的问题就是这么一个:尽可能快得写入,以及尽可能快的读取。
让我从写入最快的极端开始说起,阐述一下k-v存储的核心之一—树这个组件吧。
我们假设要写入一个1000个节点的key是随机数的数据。
对磁盘来说,最快的写入方式一定是顺序的将每一次写入都直接写入到磁盘中即可。
但这样带来的问题是,我没办法查询,因为每次查询一个值都需要遍历整个数据才能找到,这个读性能就太悲剧了。。
那么如果我想获取磁盘读性能最高,应该怎么做呢?把数据全部排序就行了,b树就是这样的结构。
那么,b树的写太烂了,我需要提升写,可以放弃部分磁盘读性能,怎么办呢?
简单,那就弄很多个小的有序结构,比如每m个数据,在内存里排序一次,下面100个数据,再排序一次……这样依次做下去,我就可以获得N/m个有序的小的有序结构。
在查询的时候,因为不知道这个数据到底是在哪里,所以就从最新的一个小的有序结构里做二分查找,找得到就返回,找不到就继续找下一个小有序结构,一直到找到为止。
很容易可以看出,这样的模式,读取的时间复杂度是(N/m)*log2N 。读取效率是会下降的。
这就是最本来意义上的LSM tree的思路。
那么这样做,性能还是比较慢的,于是需要再做些事情来提升,怎么做才好呢?
于是引入了以下的几个东西来改进它
1. Bloom filter : 就是个带随即概率的bitmap,可以快速的告诉你,某一个小的有序结构里有没有指定的那个数据的。于是我就可以不用二分查找,而只需简单的计算几次就能知道数据是否在某个小集合里啦。效率得到了提升,但付出的是空间代价。
2. 小树合并为大树: 也就是大家经常看到的compact的过程,因为小树他性能有问题,所以要有个进程不断地将小树合并到大树上,这样大部分的老数据查询也可以直接使用log2N的方式找到,不需要再进行(N/m)*log2n的查询了。
这就是LSMTree的核心思路和优化方式。
不过,LSMTree也有个隐含的条件,就是他实现数据库的insert语义时性能不会很高,原因是,insert的含义是: 事务中,先查找该插入的数据,如果存在,则抛出异常,如果不存在则写入。这个“查找”的过程,会拖慢整个写入。
这样,我们就又介绍了一种k-v写入的模型啦。在下一次,我们将再去看看另外一种使用了类似思路,但方法完全不同的b树优化方式 COLA树系。敬请期待 ~
http://rdc.taobao.com/team/jm/archives/1408 下一篇
http://rdc.taobao.com/team/jm/archives/1390 上一篇
http://www.mysqlperformanceblog.com/2009/04/28/detailed-review-of-tokutek-storage-engine/
这里有一些性能上的指标和分析性文字。确实看起来很心动,不过这东西只适合磁盘结构,到了SSD似乎就挂了。原因不详,因为没有实际的看过他们的代码,所以一切都是推测,如果有问题,请告知我。
先说原理,上ppt http://tokutek.com/presentations/bender-Scalperf-9-09.pdf,简单来说,就是一帮MIT的小子们,分析了一下为什么磁盘写性能这么慢,读的性能也这么慢,然后一拍脑袋,说:“哎呀,我知道了,对于两级的存储(比如磁盘对应内存,或内存对于缓存,有两个属性是会对整个查询和写入造成影响的,一个是容量空间小但速度更快的存储的size,另外一个则是一次传输的block的size.而我们要做的事情,就是尽可能让每次的操作传输尽可能少的数据块。
传输的越少,那么查询的性能就越好。
进而,有人提出了更多种的解决方案。
•B-tree [Bayer, McCreight 72]
• cache-oblivious B-tree [Bender, Demaine, Farach-Colton 00]
• buffer tree [Arge 95]
• buffered-repositorytree[Buchsbaum,Goldwasser,Venkatasubramanian,Westbrook 00]
• Bε
tree[Brodal, Fagerberg 03]
• log-structured merge tree [O'Neil, Cheng, Gawlick, O'Neil 96]
• string B-tree [Ferragina, Grossi 99]
这些结构都是用于解决这样一个问题,在磁盘上能够创建动态的有序查询结构。
在今天,主要想介绍的就是COLA,所谓cache-oblivious 就是说,他不需要知道具体的内存大小和一个块的大小,或者说,无论内存多大,块有多大,都可以使用同一套逻辑进行处理,这无疑是具有优势的,因为内存大小虽然可以知道,但内存是随时可能被临时的占用去做其他事情的,这时候,CO就非常有用了。
其他我就不多说了,看一下细节吧~再说这个我自己都快绕进去了。
众所周知的,磁盘需要的是顺序写入,下一个问题就是,怎么能够保证数据的顺序写。
我们假定有这样一个空的数据集合
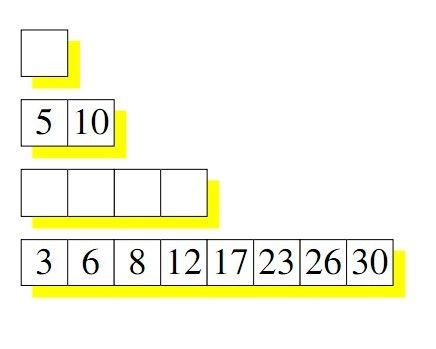
可以认为树的高度是log2N。
每行要么就是空的,要么就是满的,每行数据都是排序后的数据。
如果再写一个值的时候,会写在第一行,比如写了3。
再写一个值11的时候,因为第一行已经写满了,所以将3取出来,和11做排序,尝试写第二行。又因为第二行也满了,所以将第二行的5和10也取出,对3,11,5,10 进行排序。写入第四行

这就是COLA的写入过程。
可以很清楚的看出,COLA的核心其实和LSM类似,每次“将数据从上一层取出,与外部数据进行归并排序后写入新的array”的这个操作,对sas磁盘非常友好。因此,写入性能就会有非常大的提升。
并且因为数据结构简单,没有维持太多额外的指针,所以相对的比较节省空间。
但这样查询会需要针对每个array都进行一次二分查找。
性能似乎还不是很高,所以,他们想到了下面这种方式,把它的命名为fractal tree,分形树。
用更简单的方法来说的话呢,就是在merge的时候,上层持有下层数据的一个额外的指针。
来协助进行二分查找。

这样,利用空间换时间,他的查询速度就又回到了log2N这个级别了。
到此,又一个有序结构被我囫囵吞枣了。
嘿嘿
在下一篇,我们将进入大家期待的分布式k-V场景,也就是noSQL的范畴了,让我们拨开nosql的神秘面纱,看看这东西到底意味着什么。
http://rdc.taobao.com/team/jm/archives/1411 下一篇
http://rdc.taobao.com/team/jm/archives/1408 上一篇
但有两个额外的因素需要考虑
网络延迟
TCP/IP –公用网络,ip跳转慢,tcp包头大
可能出现不可达问题
这其实是状态机同步中最难的一个问题,也就是,A给B消息,B可能给A的反馈可能是:1. 成功 2. 失败 3. 无响应。最难处理的是这个无响应的问题。以前的文章中我们讨论过这个问题,以后还会碰到。这里暂且hold住。
先上图一张,在未来的几周内,我们都会依托这张图来解释分布式K-V系统

可以看到,在客户机到服务器端,有这么几个东西
一,规则引擎
二,数据节点间的同步
抽象的来看,分布式K-V系统和传统的单机k-v系统的差别,也就只在于上面的两个地方的选择。
今天先来谈规则引擎
抽象的来看,规则引擎面向的场景应该被这样的描述:对于有状态的数据,需要一套机制以保证其针对同一个数据的多次请求,应该物理上被发送到同一个逻辑区块内的同一个数据上。
举例子来说,一个人进行了三笔交易,每笔交易都是这个人给其他人100元。那么,这三比交易的更新(update set money = money – 100 where userid = ?) 必须被发到同一台机器上执行,才能拿到正确的结果。【不考虑读性能的gossip模型除外】
这种根据一个userid 找到其对应的机器的过程,就是规则引擎所要处理的事情。
我们对于规则引擎的需求,一般来说也就是要查的快,第二个是要能尽可能的将数据平均的分配到所有的节点中去。第三个,如果新的节点加入进去,希望能够只移动那些需要移动的数据,不需要移动的数据则不要去移动他。
那么一想到“根据xxx找到xxx”相信大家第一个想到的一定又是以前说过的K-V了。所以我们就再复习一遍: )
Hash
O(1)效率
不支持范围查询(时间这样的查询条件不要考虑了)
不需要频繁调整数据分布
顺序
主要是B-Tree
O(logN)效率
支持范围查询
需要频繁调整节点指针以适应数据分布
这也就是我们最常用的两种分布式k-value所使用的数据结构了
首先来看HASH的方法。Hash其实很容易理解,但我跟不少人交流,发现大家可能对一致性hash的理解有一定的误解。下面请允许我给大家做个简单的介绍。
简单取模:
最简单的HASH 就是取mod,user_id % 3 。这样,会将数据平均的分配到0,1,2 这三台机器中。
这也是我们目前最常用的,最好用的方案。但这套方案也会有一个问题,就是如果id % 3 -> id % 4 总共会有75%的数据需要变动hash桶,想一想,只增加了一台机器,但75%的数据需要从一个机器移动到另外一个机器,这无疑是不够经济的,也是对迁移不友好的方案。
不过,虽然增加一台机器,会发生无谓的数据移动,但取模的方案在一些特殊的场景下,也能很好的满足实际的需要,如id % 3 -> id % 6,这种情况下,只需要有50%的数据移动到新的机器上就可以了。这也就是正常的hash取模最合适的扩容方式—–> 倍分扩容。我们一般把这种扩容的方式叫做”N到2N”的扩容方案。
取模Hash还有个无法解决的问题,就是无法处理热点的问题,假设有一个卖家有N个商品。如果按照卖家ID进行切分,那么就有可能会造成数据不均匀的问题。有些卖家可能有10000000个商品,而有些卖家只会有10个。这种情况下如果有大量商品的卖家针对他的商品做了某种操作,那这样无疑会产生数据热点。如何解决这类问题,也是分布式场景中面临的一个重要的问题。
既然简单取模有这么多的问题,那有没有办法解决这些问题呢?
首先,我们来介绍第一种解决这个问题的尝试。
一致性Hash.
先来个图,这套图估计几乎所有对Nosql稍有了解的人都应该看过,在这里我会用另外的方式让大家更容易理解

上面这个图,用代码来表示,可以认为是这样一套伪码
Def idmod = id % 1000 ;
If(id >= 0 and id < 250)
returndb1;
Else if (id >= 250 and id < 500)
returndb2;
Else if (id >= 500 and id < 750)
returndb3;
Else
returndb4;
这个return db1 db2 db3 db4 就对应上面图中的四个浅蓝色的点儿。
而如果要加一个node5 ,那么伪码会转变为
Def idmod = id % 1000 ;
If(id >= 0 and id < 250)
returndb1;
Else if (id >= 250 and id < 500)
returndb2;
Else if (id >= 500 and id < 625)
returndb5;
else if(id >= 625 and id <750)
returndb3
Else
returndb4;
从这种结构的变化中,其实就可以解决我们在普通hash时候的面临的两个问题了。
1. 可以解决热点问题,只需要对热点的数据,单独的给他更多的计算和存储资源,就能部分的解决问题(但不是全部,因为迁移数据不是无成本的,相反,成本往往比较高昂)
2. 部分的能够解决扩容的问题,如果某个点需要加机器,他只会影响一个节点内的数据,只需要将那个节点的数据移动到新节点就可以了。
但一致性hash也会带来问题,如果数据原本分布就非常均匀,那么加一台机器,只能解决临近的一个节点上的热点问题,不会影响其他节点,这样,热点扩容在数据分布均匀的情况下基本等于n->2n方案。因为要在每个环上都加一台机器,才能保证所有节点的数据的一部分迁移到新加入的机器上。
这无疑对也会浪费机器。
于是,我们又引入了第三套机制:
虚拟节点hash
Def hashid = Id % 65536
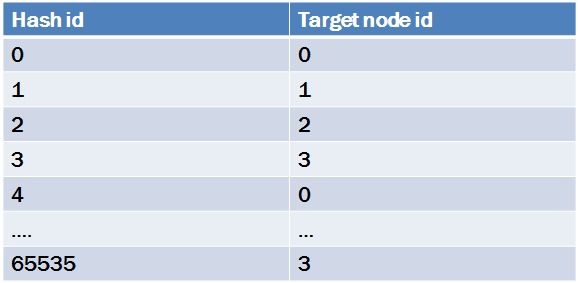
可以很容易的看出,上面这套虚拟节点的方案,其实与id % 4的结果等价。
可以认为一致性hash和普通节点hash,都是虚拟节点hash的特例而已。
使用虚拟节点hash,我们就可以很容易的解决几乎所有在扩容上的问题了。
碰到热点?只需要调整虚拟节点map中的映射关系就行了
碰到扩容?只需要移动一部分节点的映射关系,让其进入新的机器即可
可以说是一套非常灵活的方案,但带来的问题是方案有点复杂了。
所以,我们一般在使用的方式是,首先使用简单的取模方案,如id % 4。在扩容的时候也是用N->2N的方案进行扩容。但如果碰到需求复杂的场景,我们会“无缝”的将业务方原来的简单取模方案,直接变为使用虚拟节点hash的方案,这样就可以支持更复杂的扩容和切分规则,又不会对业务造成任何影响了。
好,到这,我基本上就给大家介绍了如何使用Hash来完成分布式k-value系统的规则引擎构建了。
下一期我们来看一下使用树的方案,当然,主要也就是hbase这个东西了,可能会再介绍一下mongodb的自动扩容方案。