【机器学习】机器学习和深度学习概念入门
机器学习和深度学习概念入门(上)
谭东 来源:

目 录
1 人工智能、机器学习、深度学习三者关系
2 什么是人工智能
3 什么是机器学习
4 机器学习之监督学习
5 机器学习之非监督学习
6 机器学习之半监督学习
7 机器学习之强化学习
8 什么是深度学习
9 总结
阅读时间
10min - 20min
1 人工智能、机器学习、深度学习三者关系对于很多初入学习人工智能的学习者来说,对人工智能、机器学习、深度学习的概念和区别还不是很了解,有可能你每天都能听到这个概念,也经常提这个概念,但是你真的懂它们之间的关系吗?那么接下来就给大家从概念和特点上进行阐述。先看下三者的关系。
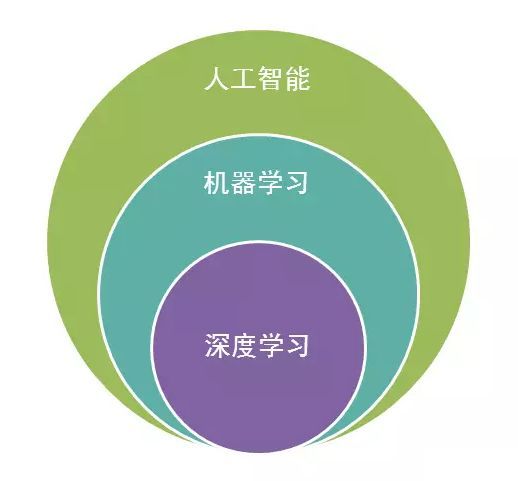
人工智能包括了机器学习,机器学习包括了深度学习,他们是子类和父类的关系。
下面这张图则更加细分。

人工智能(Artificial Intelligence),英文缩写为AI。是计算机科学的一个分支,二十世纪七十年代以来被称为世界三大尖端技术之一(空间技术、能源技术、人工智能)。也被认为是二十一世纪三大尖端技术(基因工程、纳米科学、人工智能)之一。1956年夏季,以麦卡赛、明斯基、罗切斯特和申农等为首的一批有远见卓识的年轻科学家在一起聚会,共同研究和探讨用机器模拟智能的一系列有关问题,并首次提出了“人工智能”这一术语,它标志着“人工智能”这门新兴学科的正式诞生。人工智能是对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、也可能超过人的智能。数学常被认为是多种学科的基础科学,数学也进入语言、思维领域,人工智能学科也必须借用数学工具。
人工智能实际应用:机器视觉,指纹识别,人脸识别,视网膜识别,虹膜识别,掌纹识别,专家系统,自动规划,智能搜索,定理证明,博弈,自动程序设计,智能控制,机器人学,语言和图像理解,遗传编程等。涉及到哲学和认知科学,数学,神经生理学,心理学,计算机科学,信息论,控制论,不定性论等学科。研究范畴包括自然语言处理,知识表现,智能搜索,推理,规划,机器学习,知识获取,组合调度问题,感知问题,模式识别,逻辑程序设计软计算,不精确和不确定的管理,人工生命,神经网络,复杂系统,遗传算法等。人工智能目前也分为:强人工智能(BOTTOM-UP AI)和弱人工智能(TOP-DOWN AI),有兴趣大家可以自行查看下区别。
机器学习(Machine Learning, ML),是人工智能的核心,属于人工智能的一个分支,是一个大的领域,是让计算机拥有像人一样的学习能力,模拟和实现人的学习行为和能力,可以像人一样具有识别和判断的能力,可以看作是仿生学。机器学习的核心就是数据,算法(模型),算力(计算机运算能力)。以前也有人工智能,机器学习。不过最近几年网络发展和大数据的积累,使得人工智能能够在数据和高运算能力下发挥它的作用。机器学习应用领域十分广泛,例如:数据挖掘、数据分类、计算机视觉、自然语言处理(NLP)、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用等。

李飞飞说,机器是又快又准确,但是人类聪明呀!机器学习其实是在总结数据,预测未知。它具有高速的计算能力,我们可以通过不断的学习用它来识别各种植物、动物等,并提高准确率。

机器学习就是设计一个算法模型来处理数据,输出我们想要的结果,我们可以针对算法模型进行不断的调优,形成更准确的数据处理能力。但这种学习不会让机器产生意识。
机器学习的工作方式选择数据:将你的数据分成三组:训练数据、验证数据和测试数据。
模型数据:使用训练数据来构建使用相关特征的模型。
验证模型:使用你的验证数据接入你的模型。
测试模型:使用你的测试数据检查被验证的模型的表现。
使用模型:使用完全训练好的模型在新数据上做预测。
调优模型:使用更多数据、不同的特征或调整过的参数来提升算法的性能表现。
基于学习策略的分类
机械学习 (Rote learning)
示教学习 (Learning from instruction或Learning by being told)
演绎学习 (Learning by deduction)
类比学习 (Learning by analogy)
基于解释的学习 (Explanation-based learning, EBL)
归纳学习 (Learning from induction)
基于所获取知识的表示形式分类
代数表达式参数
决策树
形式文法
产生式规则
形式逻辑表达式
图和网络
框架和模式(schema)
计算机程序和其它的过程编码
神经网络
多种表示形式的组合
综合分类
经验性归纳学习 (empirical inductive learning)
分析学习(analytic learning)
类比学习
遗传算法(genetic algorithm)
联接学习
增强学习(reinforcement learning)
学习形式分类
监督学习(supervised learning)
非监督学习(unsupervised learning)
注:细分的话还有半监督学习和强化学习。当然,后面的深度学习也有监督学习、半监督学习和非监督学习的区分。
4 机器学习之监督学习监督学习(Supervised Learning)是指利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。也就是我们输入的数据是有标签的样本数据(有一个明确的标识或结果、分类)。例如我们输入了 50000 套房子的数据,这些数据都具有房价这个属性标签。
监督学习就是人们常说的分类,通过已有的训练样本(即已知数据以及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优则表示在某个评价准则下是最佳的)。再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的。就像我输入了一个人的信息,他是有性别属性的。我们输入我们的模型后,我们就明确的知道了输出的结果,也可以验证模型的对错。
举个例子,我们从小并不知道什么是手机、电视、鸟、猪,那么这些东西就是输入数据,而家长会根据他的经验指点告诉我们哪些是手机、电视、鸟、猪。这就是通过模型判断分类。当我们掌握了这些数据分类模型,我们就可以对这些数据进行自己的判断和分类了。

在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。
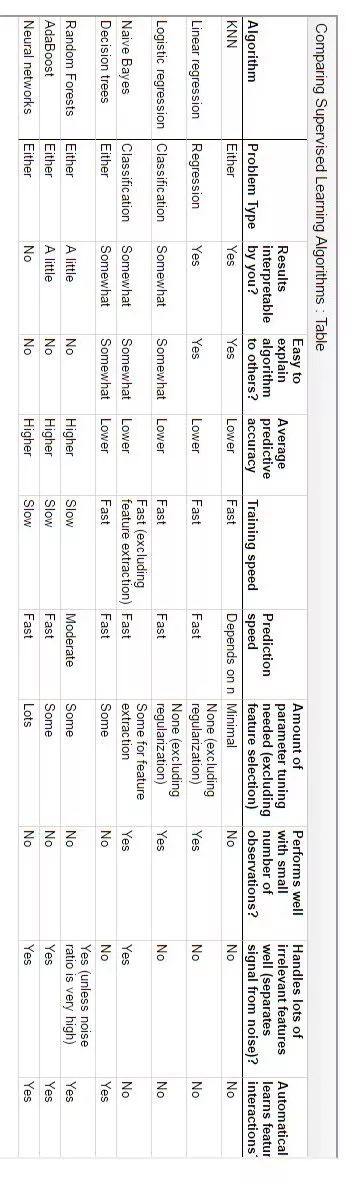
监督式学习的常见应用场景如分类问题和回归问题。常见监督式学习算法有决策树(ID3,C4.5算法等),朴素贝叶斯分类器,最小二乘法,逻辑回归(Logistic Regression),支持向量机(SVM),K最近邻算法(KNN,K-NearestNeighbor),线性回归(LR,Linear Regreesion),人工神经网络(ANN,Artificial Neural Network),集成学习以及反向传递神经网络(Back Propagation Neural Network)等等。
下图是几种监督式学习算法的比较:
(请将手机横着查看)
非监督学习(Unsupervised Learing)是另一种研究的比较多的学习方法,它与监督学习的不同之处,在于我们事先没有任何训练样本,而需要直接对数据进行建模。是否有监督(Supervised),就看输入数据是否有标签(Label)。输入数据有标签(即数据有标识分类),则为有监督学习,没标签则为无监督学习(非监督学习)。在很多实际应用中,并没有大量的标识数据进行使用,并且标识数据需要大量的人工工作量,非常困难。我们就需要非监督学习根据数据的相似度,特征及相关联系进行模糊判断分类。
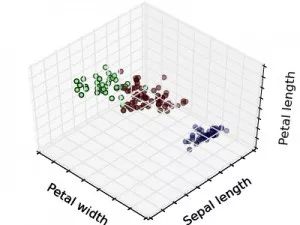
半监督学习(Semi-supervised Learning)是有标签数据的标签不是确定的,类似于:肯定不是某某某,很可能是某某某。是监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。当使用半监督学习时,将会要求尽量少的人员来从事工作,同时,又能够带来比较高的准确性。

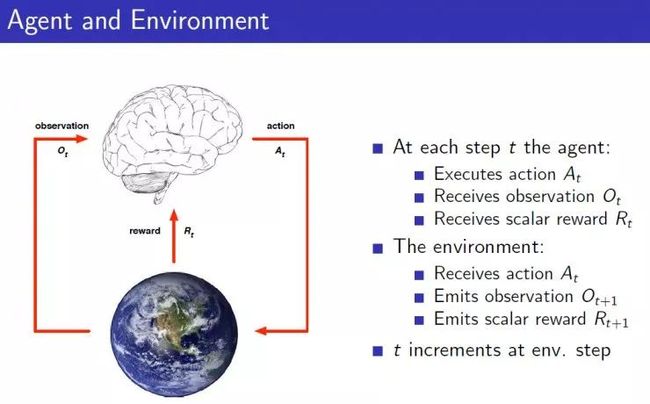
在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。半监督学习有两个样本集,一个有标记,一个没有标记。分别记作Lable={(xi,yi)},Unlabled={(xi)},并且数量,L< 注: 单独使用有标记样本,我们能够生成有监督分类算法 单独使用无标记样本,我们能够生成无监督聚类算法 两者都使用,我们希望在1中加入无标记样本,增强有监督分类的效果;同样的,我们希望在2中加入有标记样本,增强无监督聚类的效果 一般而言,半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类,也就是在1中加入无标记样本,增强分类效果。 应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如自训练算法(self-training)、多视角算法(Multi-View)、生成模型(Enerative Models)、图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM)等。 谭东 来源: 目 录 1 人工智能、机器学习、深度学习三者关系 2 什么是人工智能 3 什么是机器学习 4 机器学习之监督学习 5 机器学习之非监督学习 6 机器学习之半监督学习 7 机器学习之强化学习 8 什么是深度学习 9 总结 阅读时间 8min - 15min 强化学习(Reinforcement Learning)也叫再励学习、评价学习,在智能控制和机器人领域有许多应用。输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式。在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。常见算法包括 Q-Learning、TD 算法(时间差分学习,Temporal Difference)、SARSA 算法。 在企业数据应用的场景下, 人们最常用的可能就是监督式学习和非监督式学习的模型。 在图像识别等领域,由于存在大量的非标识的数据和少量的可标识数据, 目前半监督式学习是一个很热的话题。 而强化学习更多的应用在机器人控制及其他需要进行系统控制的领域。 强化学习灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。这个方法具有普适性,因此在其他许多领域都有研究,例如博弈论、控制论、运筹学、信息论、模拟优化方法、多主体系统学习、群体智能、统计学以及遗传算法。 它的本质就是解决“决策(decision making)”问题,即学会自动进行决策。它在没有任何label告诉算法应该怎么做的情况下,通过先尝试做出一些行为——然后得到一个结果,通过判断这个结果是对还是错来对之前的行为进行反馈。由这个反馈来调整之前的行为,通过不断的调整算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。
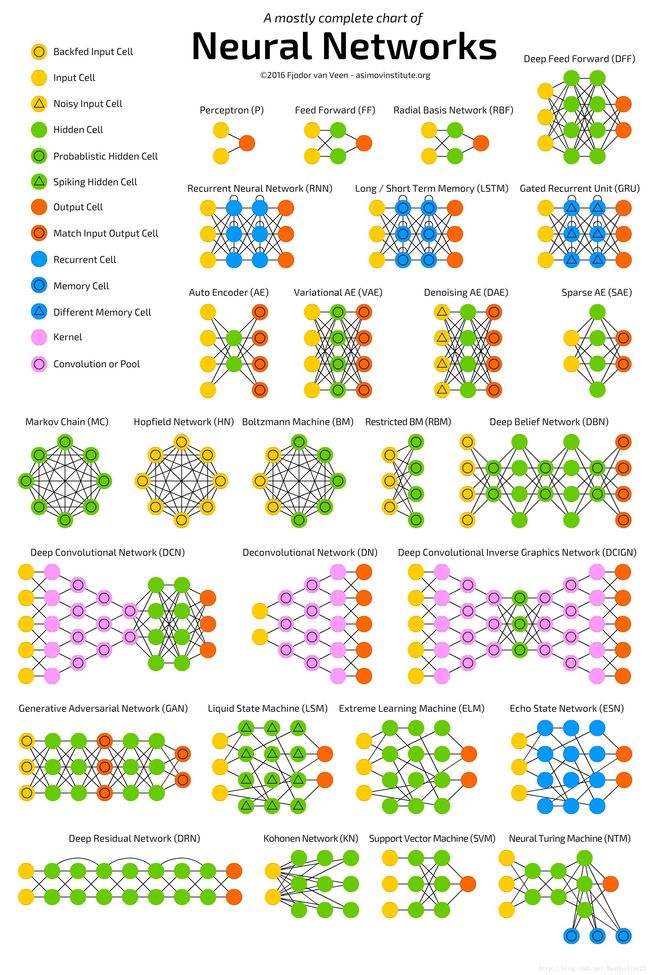
重点:强化学习其实就是自动进行决策,并且可以做连续决策。强化学习有很多应用,比如自动直升机,机器人控制,市场决策,工业控制,无人驾驶,AlphaGo,玩游戏,还在制造业、库存处理、电商、广告、推荐、金融、医疗等与我们生活息息相关的领域也有应用。例如一家日本公司 Fanuc,工厂机器人在拿起一个物体时,会捕捉这个过程的视频,记住它每次操作的行动,操作成功还是失败了,积累经验,下一次可以更快更准地采取行动。 举个例子:以小孩学习走路为例,走路时候小孩需要知道先进行决定先迈那条腿,如果第一步作对了,那么就会得到奖励,错了,那么记录下来,再进行第二次走路时候进行学习更正。又比如在向用户推荐新闻文章的任务中,非监督式会找到用户先前已经阅读过类似的文章并向他们推荐其一,而强化学习将通过向用户先推荐少量的新闻,并不断获得来自用户的反馈,最后构建用户可能会喜欢的文章的“知识图”。 深度学习(Deep Learning)是机器学习的一种,是它的一个大的分支,深度学习的概念由Hinton等人于2006年提出,深度学习的概念源于人工神经网络的研究。 既然叫做学习,那么自然与我们人类的学习过程有相似之处,其实就是仿生学,仿照我们人类大脑的思维方式以及神经网络的接收和反馈方式进行计算机模拟深度学习的。 我们的大脑就是一个深度学习的超级计算机。深度学习实际上指的的深度神经网络学习,普通神经网络由于训练代价较高,一般只有3-4层,而深度神经网络由于采用了特殊的训练方法加上一些技术算法,可以达到8-10层。深度神经网络能够捕捉到数据中的深层联系,从而能够得到更精准的模型,而这些联系不容易被普通的机器学习方法所发觉。 用官方的含义就是:含多隐层的多层感知器就是一种深度学习结构。 深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。 同机器学习方法一样,深度机器学习方法也有监督学习与无监督学习之分。不同的学习框架下建立的学习模型很是不同。 例如,卷积神经网络(Convolutional neural networks,简称CNNs)就是一种深度的监督学习下的机器学习模型,而深度置信网(Deep Belief Nets,简称DBNs)就是一种无监督学习下的机器学习模型。 深度学习整个过程就是数据收集、数据清洗处理、传入数据进行训练模型和学习优化、经过不断优化调节后形成高准确率的识别分类模型,供相应的领域进行传入相关数据进行应用分类。 举个例子,我们人类在刚出生时看到一个手机,那么他是不知道这个是什么的,并且有各种各样形状和样式的手机,此时我们的深度学习系统初始状态就是这样的。但是经过父母和周围的分类和指导,我们渐渐的知道了这种样子和形状、功能的物体是手机,那么我们通过大量的数据就具有了学习和分辨手机的能力模型,那么这就是我们的深度学习系统在经过数据和算法训练后所具备的功能和学习能力。 就是这么简单,可以说就是仿生学。 2017年CCF青年精英大会,香港中文大学教授汤晓鸥指出,深度学习的三大核心要素,就是算法设计、高性能的计算能力、大数据。我觉得应该按照这个顺序排序:大数据、算法设计、高性能的计算能力。 例如深度学习在语音识别和自然语言领域,微软研究人员通过与hinton合作,首先将RBM和DBN引入到语音识别声学模型训练中,并且在大词汇量语音识别系统中获得巨大成功,使得语音识别的错误率相对减低30%。 但是,DNN还没有有效的并行快速算法,很多研究机构都是在利用大规模数据语料通过GPU平台提高DNN声学模型的训练效率。在国际上,IBM、google等公司都快速进行了DNN语音识别的研究,并且速度飞快。国内方面,阿里巴巴,科大讯飞、百度、中科院自动化所等公司或研究单位,也在进行深度学习在语音识别上的研究。 最后,给大家附带一个深度学习部分常用的神经网络算法的图形展示。 机器学习和深度学习的核心就是数据、算法(模型函数)、算力(计算机运算能力)。 我们研究的核心就是算法,也就是针对某一应用需求场景,选择各种合适的函数公式进行构建和叠加形成一个处理数据的模型(也就是常说的训练数据模型)。 这个模型的作用是什么?就是能够将我们的普通数据输入进去,经过这个模型处理后,输出数据或者一个结果,这个输出的就是供我们参考或者使用的。 那我们怎么评判这个模型的好坏?例如每年 ImageNet 都会进行比赛,那么评判的结果就是你这个模型算法进行数据分析和处理的准确度。例如人脸识别,有的算法识别率 80%,有的达到 98%。那么这个高识别率的模型算法就要好一些。我们需要改进的也就是这个模型算法(也就是调优),其中就会涉及到权重(Weight)和损失函数(Loss)。当然损失函数越低说明我们的算法处理数据越接近最佳结果。 整个流程就是: Step1 选择训练数据(用于训练模型) Step2 模型设计和调优(通过训练数据进行反复调优) Step3 形成比较准确的模型 Step4 输入真实数据(用于模型进行数据处理) Step5 模型处理数据 Step6 输出处理结果 举个例子:我们进行预测某天天气的状况,这是一个需求。 某天天气的状况,会受到很多因素的影响,例如季节、地理位置、时间、人为因素等等,这些因素可能会有几十个。在深度学习模型里,这些影响结果的因素我们称之为特征。我们可以通过一些有标签的天气数据去输入到我们的模型里,不断的给各个特征设置权重、损失函数,不断的进行调优。最后形成能够很好的准确预测天气的一个模型。
我们在进行机器学习和深度学习的核心,就是在算法这块,也就是设计处理问题(数据)的模型。模型需要针对不同的问题和需求进行合理的选择或者搭配。会涉及到很多数学公式和函数。其实这些数学函数在一些框架里已经囊括了,如tensorflow,python 的 numpy 库。我们需要的就是通过训练数据进行模型测试训练,调优,再应用。 先有需求和目的:这个模型是干嘛的,处理什么问题的。输入的数据什么样的,想要有什么输出结果才是最好的,能够达到我们想要的目的的。是数据和需求驱动我们选择什么样的模型和函数算法。确定了大概的方案模型和算法函数,我们就要给模型不断的喂数据进行调整优化,使他能够输出更加准确的数据处理结果,也就是常说的训练模型。当模型通过数据训练好了后,我们就可以进行应用了,喂给它真实的数据进行处理。
人工智能赛博物理操作系统 AI-CPS OS “人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。 AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。 领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位: 重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思? 重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司? 重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置: 精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。 智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。 高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。 不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。 边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。 AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长: 创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案; 对现有劳动力和实物资产进行有利的补充和提升,提高资本效率; 人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。 给决策制定者和商业领袖的建议: 超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机; 迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新 评估未来的知识和技能类型; 制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开 发过程中确定更加明晰的标准和最佳实践; 重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临 较高失业风险的人群; 开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。 如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆! 新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS 用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
长按上方二维码关注微信公众号: AI-CPS,更多信息回复: 新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能农业”、“智能金融”、“智能零售”、“智能城市”、“智能驾驶”;新模式:“财富空间”、“数据科学家”、“赛博物理”、“供应链金融”。 官方网站:AI-CPS.NET 本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:[email protected]
机器学习和深度学习概念入门(下)