neuraltalk2 在 WSL完全下入坑指南(超详细小白指导)
前言
之前尝试模仿neuraltalk2做图像识别,在此之前先试了试用别人已经训练好的模型体验图像识别。因为对Linux系统一知半解(现在想来,一知半解果然比完全不懂要糟糕),所以尝试在win10下用WSL(Windows Subsystem for Linux)即微软官方推出的win下Ubuntu(Linux系统的一个变种)子系统来安装运行。结果中途大坑小坑不断,循环找错误的过程被我玩成了递归······分析消耗时间,发现消耗时间最多的地方在一些很简单、基础的方面(比如文件夹少了一个字母,文件路径不对,不会删除文件、进入目录等等)。因此这里最中肯的建议是有一定的Linux基础在来安装这个模型。
WARNING
特别提醒:截止至2020/1/4,WSL不能联系GPU!!就算电脑有也不能!只能联系CPU!换句话说,想用GPU加深学习速度不能用WSL,可以尝试双系统或者虚拟机,不要尝试WSL子系统!(真·只能运行别人模型·体验一把·系统)官网通知:WSL
准备工作
首先要安装WSL,可以参照这篇博客:csdn博客
我本人则是使用的另外一篇:百度经验
两篇可以对照着看,安装完成后,恭喜你获得了一个纯净版Ubuntu。
注意:教程里有让改成中文版系统的,我的建议是不要改,因为出问题英文报错比中文更容易上网搜索找到解决方法
neuraltalk2模型安装使用
官方源代码+安装使用教程地址:https://github.com/karpathy/neuraltalk2
注意:该教程基于正常的Ubuntu(也就是电脑主系统就是它),应用到WSL需要安装一些默认库。同时该教程默认使用GPU加速,因此有些地方应该跳过
中文版教程:csdn博客
正式安装&踩坑脱坑步骤:
先输入指令:sudo -i,输入密码,进入root权限。在未特意提及的情况下,以下所有的步骤都在root权限下完成。root权限成功进入显示如下:
![]()
由于我们的系统版本是纯净的不能再纯净的WSL版,因此随时可能遇到在真正系统中默认安装一些库、环境、软件等等在WSL中没有的情况,其中大多数都有如下提示:

只要按照提示(apt install hello)安装即可。
值得一提的是,在Linux中,一切正常即无事发生,只有在出现问题才会给提示。作为Linux的一种,Ubuntu也是这样。
1.安装torch7
代码如下:
$ curl -s https://raw.githubusercontent.com/torch/ezinstall/master/install-deps | bash
$ git clone https://github.com/torch/distro.git ~/torch --recursive
$ cd ~/torch;
$ ./install.sh # and enter "yes" at the end to modify your bashrc
$ source ~/.bashrc
运行第一个指令的时候,可能会比较慢,且一定要在最后有以下的一句话作为结尾提示:
torch dependencies have already installed.
才代表真正的完成这些库的安装,否则就要重新安装。
在运行到第二个指令(git clone···)的时候,你会发现下载速度异乎寻常的慢,平均每秒只有几十k(当然,如果你人在国外或者有办法不限速连接GitHub,当我没说),这里提及几个可以加速下载的办法:
1.修改GitHub的host文件,具体自行百度或google
2.利用码云、coding等等国内的git仓库,以码云未例,首先注册账号,在新建仓库:
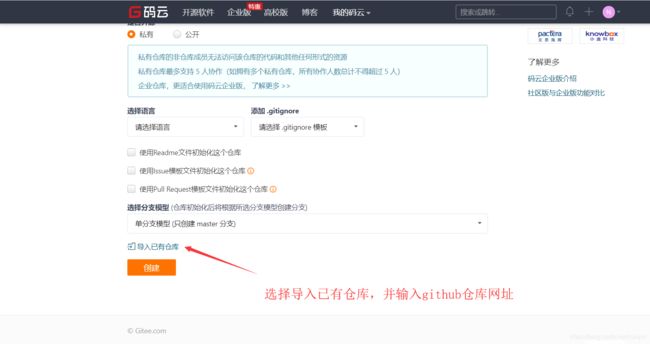
一般在一分钟内就能成功创建和git一模一样的仓库,在git clone 时只要吧git clone后面的网站改为新建的码云仓库的网址,就能快速git clone。
不过,在你尝试后,你会发现,这些办法统统没有用!下载torch仓库还是那么慢!(还有可能是因为我是校园网的缘故)原因其实很简单,torch的git仓库大量连接到其他git仓库:

所以这里最直接简单的办法就是等,亲测大概晚上开始下,早上起来就下好了,简直和秒下一样。
下完后,输入th,会出现以下界面:
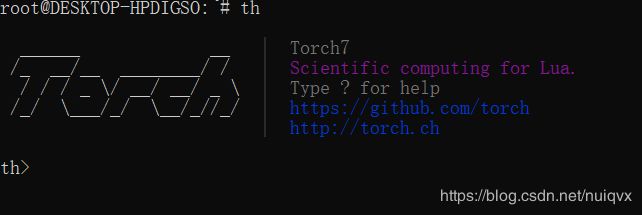
该界面成功出现代表torch7安装成功,按Ctrl/Command + Z可以退出
2.安装Lua的一些相关安装包:
官方代码如下
$ luarocks install nn
$ luarocks install nngraph
$ luarocks install image
这里需要安装luarocks,因为这个模型的代码是lua和python混合写的。因此要安装luarocks(lua模块安装部署系统),因为直接安装lua是繁琐且不易的。
在安装完luarocks后,才能使用上述指令
3.安装cjson:
下载网址:https://www.kyne.com.au/~mark/software/lua-cjson.php
下载lua-cjson-2.1.0.zip (95kB)的包,下载完后,解压文件夹放在:
C:\Users\用户名\AppData\Local\Packages\CanonicalGroupLimited.UbuntuonWindows_79rhkp1fndgsc\LocalState\rootfs\root
里,该路径所指文件夹是Ubuntu的root权限下根目录,之后执行指令:
cd lua-cjson-2.1.0
luarocks make
4.安装loadcaffe:
由于WSL无法连接到GPU的缘故,因此在安装完cjson后就可以直接跳转到官网For training的步骤,安装代码如下:
sudo apt-get install libprotobuf-dev protobuf-compiler
luarocks install loadcaff
5.安装h5py和torch-hdf5:
先安装h5py(HDF5 for Python),之后才能安装torch-hdf5
- 安装h5py
官网安装指南:http://docs.h5py.org/en/latest/index.html
我本人安装的是hdf5+python-dev+libhdf5-dev三个库。
安装hdf5:
注意:在我尝试的过程中,自动安装hdf5到最后尝试许多奇怪的bug,一切原因都是因为版本不对!自动安装指令(如luarocks install hdf5)安装的hdf5版本是2.1以上的,可要求版本最好改成1.8.20
hdf5官网:HDF5
1.8.20下载网址:hdf51.8.20
下载 hdf5-1.8.20.zip的包,解压后文件夹放在root根目录下(根目录在哪上文有提及),之后执行指令
cd hdf5-1.8.20
$sudo ./configure
$sudo make
$sudo make check
$sudo make install
$sudo make check-instal
即可
- 安装torch-hdf5
官方教程:https://github.com/deepmind/torch-hdf5/blob/master/doc/usage.md
快速安装指南:
sudo apt-get install libhdf5-serial-dev hdf5-tools
git clone https://github.com/deepmind/torch-hdf5
cd torch-hdf5
luarocks make hdf5-0-0.rockspec LIBHDF5_LIBDIR="/usr/lib/x86_64-linux-gnu/"
6.模型下载和使用:
首先我们要克隆neuraltalk2:
git alone https://github.com/karpathy/neuraltalk2
完成后,在根目录下会出现neuraltalk2的文件夹
由于WSL只能使用CPU,因此我们只能使用CPU版本的模型:CPU版本
下载下来后解压文件到root/neuraltalk2/(这一步需注意!)内
在root根目录新建一个文件夹来存放要识别的图像,比如image,此时root根目录应该包含以下文件:

之后就可以正式启动模型了!!输入指令:
cd neuraltalk2
th eval.lua -model model_id1-501-1448236541.t7_cpu.t7 -image_folder /root/images/ -gpuid -
我这里只选择了十张图像,可它依旧很慢(没办法,毕竟WSL只能靠CPU)所以说,WSL其实适合在win系统下轻松体验Linux系统的操作方式,而不是用来做什么计算模型(比如图像识别)
按照之前的步骤一步一步的来且一切正常,会看到类似如下的场景:
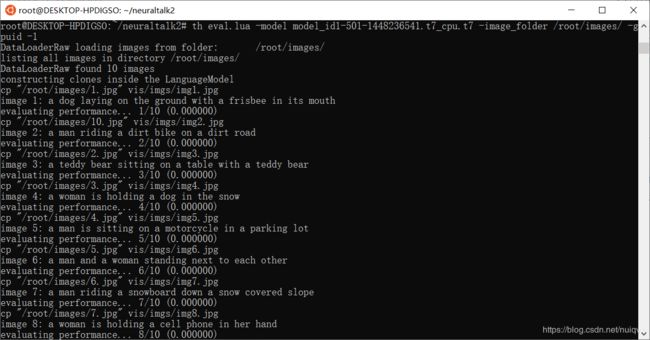
可以看到,图像字幕已经生成了,更直观的表现方式:
全部识别完成后,输入代码:
cd vis
python -m SimpleHTTPServe
成功结果:

如果失败,可能是因为python版本的问题(检查python版本方法:输入cd,在输入python,前几段就有版本信息),上述指令只适用于python2,python3则要改指令为:python -m http.server
第一次会出现防火墙警告,点击允许通过即可,之后在浏览器地址栏里输入:
localhost:8000
即可直观看到结果,如下图所示:
预测准确率还可以,至此,成功运行模型。
总结
运行这个模型花了我三天时间,正如我最开始所说,对Linux系统的一知半解带来了很大的障碍。这种一知半解让我抱着“只要是Linux系统就可以运行neuraltalk2吧”,以至于我一开始就把目标放在GPU加速上······事实上,最优雅的解决方案就是使用双系统或者虚拟机。然而,就经验来看,WSL下运行模型和双系统运行模型别无区别,这也是这篇博客的价值体现。