深入理解Redis的主从复制
前言
主从复制,主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主。这样从节点就可以起到两个作用,第一就是当作主节点的数据备份,当主节点出现故障的时候从节点可以当作备用机器,并且保证数据没有丢失。第二就是从节点可以分担主节点大部分“读”这个操作的流量。
一、Redis如何建立主从复制关系
在Redis中我们的实例可以划分为主节点与从节点,也就是说对于一个Redis实例要么是主节点(master),要么是从节点(slave),只有这两种情况,并且数据的复制是单向的,只能由主节点到从节点。
查看实例是否主从复制状态信息命令为 : info replication
127.0.0.1:55975> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
从上面的信息可以看出这个默认配置的Redis实例是一个主节点,并且没有从节点。
这时如果另外一个端口号为6379的redis实例想要与这台端口为55975的redis建立主从复制关系有几种方式:
- 直接在Redis的配置文件中将slaveof {masterHost} {masterPort} 打开,masterHost 与masterPort为对应主节点的ip与端口
- 直接使用Redis命令 slaveof {masterHost} {masterPort}
# Master-Slave replication. Use slaveof to make a Redis instance a copy of
# another Redis server. A few things to understand ASAP about Redis replication.
#
# 1) Redis replication is asynchronous, but you can configure a master to
# stop accepting writes if it appears to be not connected with at least
# a given number of slaves.
# 2) Redis slaves are able to perform a partial resynchronization with the
# master if the replication link is lost for a relatively small amount of
# time. You may want to configure the replication backlog size (see the next
# sections of this file) with a sensible value depending on your needs.
# 3) Replication is automatic and does not need user intervention. After a
# network partition slaves automatically try to reconnect to masters
# and resynchronize with them.
#
slaveof 127.0.0.1 6397
127.0.0.1:55975> slaveof 127.0.0.1 6397
OK
127.0.0.1:55975> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_repl_offset:143
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0这时这个运行在55975端口的Redis实例就为从节点了,并且可以看到由参数master_host与master_port知道它的主节点是谁。
建立了主从复制关系之后,我们在主Redis实例上操作的数据就会同步复制到从节点上来,如下图。
127.0.0.1:6379> dbsize
(integer) 0127.0.0.1:55975> dbsize
(integer) 0127.0.0.1:6379> set hello lee
OK127.0.0.1:55975> dbsize
(integer) 1
127.0.0.1:55975> keys *
1) "hello"
127.0.0.1:55975> get hello
"lee"slaveof命令的用法还可以用来断开主从复制
- slaveof no one : 当使用了这个命令,这时从节点就与主节点之间断开复制了,并且从节点也晋升为主节点了
- slave of {newMasterHost} {newMasterPort} : 这个命令可以用来切换主节点,断开旧主节点复制关系,建立新主节点复制复制关系。
127.0.0.1:55975> slaveof no one
OK
127.0.0.1:55975> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:5835
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0主从复制注意事项
- 从安全性考虑安全性考虑一般主节点都会设置密码,也就是在配置文件中将requirepass打开,那么从节点也必须在配置文件中将masterauth配置打开并且赋上正确的密码,否则复制不成功
# Require clients to issue AUTH before processing any other
# commands. This might be useful in environments in which you do not trust
# others with access to the host running redis-server.
#
# This should stay commented out for backward compatibility and because most
# people do not need auth (e.g. they run their own servers).
#
# Warning: since Redis is pretty fast an outside user can try up to
# 150k passwords per second against a good box. This means that you should
# use a very strong password otherwise it will be very easy to break.
#
requirepass 123456 # If the master is password protected (using the "requirepass" configuration
# directive below) it is possible to tell the slave to authenticate before
# starting the replication synchronization process, otherwise the master will
# refuse the slave request.
#
masterauth 123456- 不要修改从节点的slave-read-only属性为 no ,因为这样就可能导致主从节点数据不一致的情况。
#
# Since Redis 2.6 by default slaves are read-only.
#
# Note: read only slaves are not designed to be exposed to untrusted clients
# on the internet. It's just a protection layer against misuse of the instance.
# Still a read only slave exports by default all the administrative commands
# such as CONFIG, DEBUG, and so forth. To a limited extent you can improve
# security of read only slaves using 'rename-command' to shadow all the
# administrative / dangerous commands.
slave-read-only yesRedis主从复制原理
当我们配置了slaveof {masterHost} {masterPort} 或输入了 slaveof {masterHost} {masterPort} 命令时,Redsi将会执行以下建立复制的流程:
- 保存主节点信息(如主机节点的 IP 以及 端口号)
- 与主节点建立socket连接 (建立成功日志会打印出* Connecting to MASTER 127.0.0.1:6379[32500] * MASTER <-> SLAVE sync started[32500] )表示连接成功
- 向主节点发送ping命令,若没有收到主节点的pong回复或者超时了就会每隔一秒轮询重试,若主节点响应了则日志会打印出(Master replied to PING, replication can continue...)
- 进行权限的验证(若主节点配置了requirepass属性,则需要进行密码的验证,通过了则继续)
- 同步数据
- 持续复制数据
这里复制又分为全量复制与增量复制
全量复制 :我们redis从节点第一次与主节点建立复制关系时都是全量复制,这也是耗时最长的,因为第一次主节点要将自己全部的数据都发送的从节点,若主节点数据量庞大则每次都会占用很大的网络资源,所以我们应该尽量避免全量复制。
增量复制:若主从复制由于网络等问题导致数据丢失的时候,主节点会补发丢失的数据给从节点,所以资源开销远远小于全量复制,它的原理就是在主从复制的节点中都维护了一个复制偏移量与一个复制积压缓冲区,主节点处理完写入命令后会累加命令字节长度并向复制积压缓冲区写入命令,从节点每秒也会上报自己的复制偏移量给主节点,这样判断主从节点的复制偏移量差值即可判断数据是否一致,若不一致即用可使用缓冲区进行补救。
并且这里Redis对复制偏移量还做了一定的保障措施,每个Redis节点每次启动之后都会分配一个新的40位的16进制的run_id,这样可以用来让从节点根据run_id知道自己复制的是哪个主节点的数据,若run_id改变了就表明是一个新的主节点,于是从节点就会开始全量复制。也就是说run_id保障的是若主节点进行了重启或者替换了RDB\AOF文件,从节点如果还是基于偏移量复制数据就会导致数据不正确。
全量复制的原理流程如下
- 从节点发送psync命令请求同步数据,因为是第一次复制没有保存复制偏移量与run_id,所以发送的是psync?-1
- 主节点看到是psync?-1就知道是全量复制了,则回复给从节点+FULLRESYNC响应给从节点
- 从节点接收主节点的run_id与偏移量
- 主节点进行bgsave,保存最新的RDB到本地磁盘中
- 主节点发送RDB文件给从节点
- 因为从节点接收RDB时,主节点还在响应新的命令,主节点会把这段时间的命令放入客户端的缓冲区,从节点加载完RDB文件之后再把缓冲区的内容发给从节点从而保证了数据的一致性
- 从节点清空旧数据
- 从节点加载主节点的RDB文件
- 从节点加载完RDB文件后,判断从节点开启了AOF持久化没有,如果没有则完成了全量复制,如果有则会bgrewriteaof。
Redis主从复制的集中集群结构
-
一主一从的结构

一般用来主节点挂了,从节点提供故障转移
-
一主多从的结构
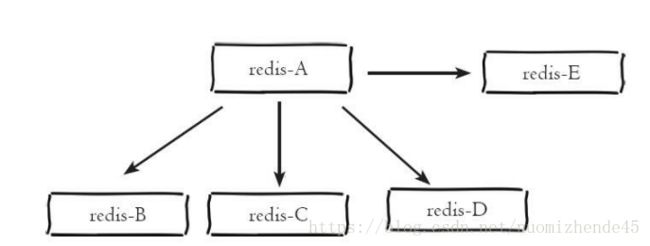
这种用于读的访问量较大的场景,主Redis只用来作写的操作,从Redis用来做读的操作,实现读写分离,让从redis帮主redis分担更多的压力
-
树型结构

若主节点下面有多个从节点,也就是我们一主多从的结构时,当主节点重新启动时,多个从节点都会同时发起请求全量复制,主节点同时给多个从节点发送RDB快照,就可能导致主节点的网络资源严重消耗、延迟变大,这时就可以考虑树状结构加入中间节点来保护主节点。
可能遇到的问题
配置了配置文件中的slaveof {masterIp} {masterPort} 启动redis的时候报错
"Invalid argument during startup: unknown conf file parameter : slaveof"
这里的原因可能是将原来的配置文件的#注释去掉导致slaveof参数前面多了一个空格导致,将空格去掉即可
# Master-Slave replication. Use slaveof to make a Redis instance a copy of
# another Redis server. A few things to understand ASAP about Redis replication.
#
# 1) Redis replication is asynchronous, but you can configure a master to
# stop accepting writes if it appears to be not connected with at least
# a given number of slaves.
# 2) Redis slaves are able to perform a partial resynchronization with the
# master if the replication link is lost for a relatively small amount of
# time. You may want to configure the replication backlog size (see the next
# sections of this file) with a sensible value depending on your needs.
# 3) Replication is automatic and does not need user intervention. After a
# network partition slaves automatically try to reconnect to masters
# and resynchronize with them.
#
slaveof 127.0.0.1 6379 #这一行前面多了一个空格,导致报错