tensorflow基于检索的聊天机器人
基于检索的模型 vs. 产生式模型
基于检索的模型(Retrieval-Based Models)有一个预先定义的"回答集(repository)",包含了许多回答(responses),还有一些根据输入的问句和上下文(context),以及用于挑选出合适的回答的启发式规则。这些启发式规则可能是简单的基于规则的表达式匹配,或是相对复杂的机器学习分类器的集成。基于检索的模型不会产生新的文字,它只能从预先定义的"回答集"中挑选出一个较为合适的回答。
产生式模型(Generative Models)不依赖于预先定义的回答集,它会产生一个新的回答。经典的产生式模型是基于机器翻译技术的,只不过不是将一种语言翻译成另一种语言,而是将问句"翻译"成回答(response)
对比起来,产生式模型显得更加智能。但是在处理某些业务时,特别是机器人工作在封闭话题场景下,基于检索的模型的表现效果会比产生式模型更好。
一、数据集准备:
- 准备好一些标准问题与答案对,question-answer。
- 对每一类question做一些类似句子的扩展,譬如标准问题“吃饭了没”的扩展可以是“吃了没”、“吃饭了吗”等等。
二、分词:
这里采用前向最大分词,即从句子的第一个字到最后一个字作为初始输入,算法和伪代码如下:
S0 当前片段为整个字符串
S1 如果当前片段不为空
S1.1如果当前片段出现在词库中。
S1.1.1将当前片段添入分词列表。
S1.1.2下一个字为开始,字符串末尾为结束转S1
S1.2否则片段去掉最后一个字转S1
S2 如果为空
S2.1如果未遍历完整个字符串
S2.1.1抛弃掉当前单字。
S2.1.2下一个字为开始,字符串末尾为结束转S1
i = 0
j = len(sentence)
isaword(i, j)
def isaword(i, j):
if i < j:
if sentence[i:j] in word_library:
word_list.append(sentence[i:j])
isaword(j, len(sentence))
else:
isaword(i,j-1)
else:
if i < len(string):
print(string[i]+’不在词库中’)
isaword(i+1,len(string)
二、词向量(word2vec)
这里就是embedding,利用已经训练好的词向量表,查表完成词与向量的转换。词向量表下载地址:不太记得了,就是一个npy文件,里面的key就是词,value就是词向量。当然,如果条件允许的话,可以训练属于自己的word2vec词向量表。
三、训练集构造
现在假设已经有了如下问题答案对(A-Q)已经问题的扩展:
A1-Q1 A11 A12 A13…
A2-Q2 A21 A22 A23…
A3-Q3 A31 A32 A33…
… …
按照以下方法构造训练集:
同类问题两两之间,构造相似训练集。Label = (1,0)
不同类问题之间,构造不相似训练集。Label = (0,1)
举例:
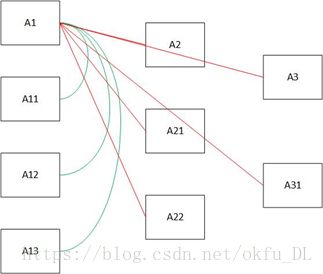
以A1为例上图中,绿线代表与A1相似问题,红线代表与A1不相似问题。
如此构造出的训练集为:

对于数据中每个问题都重复上述步骤。
四、模型结构
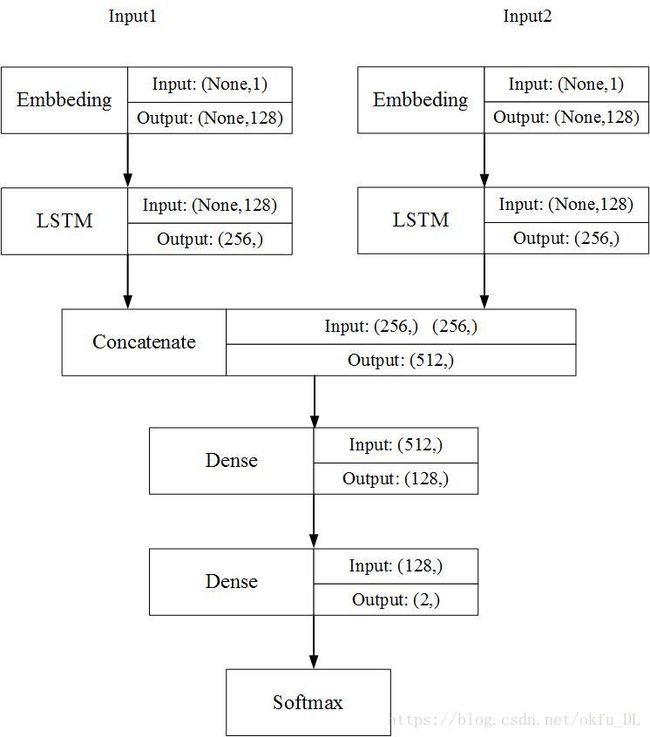
参考一下搭建模型tensorflow的python代码
class SQModel(object):
def __init__(self, is_training, rnn_size, layer_size, grad_clip):
self.input_x1 = tf.placeholder(tf.float32,[None, None, VEC_DIM])
self.input_x2 = tf.placeholder(tf.float32,[None, None, VEC_DIM])
self.targets = tf.placeholder(tf.float32,[None, NUM_LABELS])
self.x1_len = tf.placeholder(tf.int32, [None])
self.x2_len = tf.placeholder(tf.int32, [None])
with tf.variable_scope('input1'):
vec1 = self._get_simple_lstm(rnn_size, layer_size)
_, state1 = tf.nn.dynamic_rnn(vec1, self.input_x1, sequence_length=self.x1_len, dtype=tf.float32)
with tf.variable_scope('input2'):
vec2 = self._get_simple_lstm(rnn_size, layer_size)
_, state2 = tf.nn.dynamic_rnn(vec2, self.input_x2, sequence_length=self.x2_len, dtype=tf.float32)
with tf.variable_scope('concation', reuse=tf.AUTO_REUSE):
concation = tf.concat( [state1[1][1],state2[1][1]], axis=1)
with tf.variable_scope('dense'):
weights = tf.get_variable("weights", [512, 2], initializer= tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases",[2],initializer=tf.constant_initializer(0.1))
logits = tf.nn.softmax(tf.matmul(concation, weights)+biases)
# logits = tf.layers.dense(concation, 2, activation=tf.nn.softmax)
if is_training:
self.cost = -tf.reduce_mean(tf.reduce_sum(self.targets*tf.log(logits)))
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, tvars), grad_clip)
optimizer = tf.train.AdamOptimizer(1e-3)
self.train_op = optimizer.apply_gradients(zip(grads, tvars))
else:
logits_norm = tf.sqrt(tf.reduce_sum(tf.square(logits), axis=1))
targets_norm = tf.sqrt(tf.reduce_sum(tf.square(self.targets), axis=1))
logits_targets = tf.reduce_sum(tf.multiply(logits, self.targets), axis=1)
loss = tf.divide(logits_targets, tf.multiply(logits_norm, targets_norm))
self.cost = tf.reduce_mean(loss)
return
def _get_simple_lstm(self, rnn_size, layer_size):
lstm_layers = [tf.contrib.rnn.LSTMCell(rnn_size) for _ in range(layer_size)]
return tf.contrib.rnn.MultiRNNCell(lstm_layers)
上面的代码中有x1_len、x2_len代表两个输入句子的有效长度(词个数),因为输入的每个句子不是固定长度,二神经网络的输入必须是相同维度的向量,后续还要padding补齐。dynamic_rnn可以动态的解析句子向量的有效部分,给定句子的长度参数就可以了。
五、对话检索答案
经过几百轮的迭代后,模型收敛的差不多了。现在,来了一个新的问题,我们将其作为input1,然后依次从问题库中取一个问题作为input2,直到已有问题遍历完。得到一个二维数组logits = [[a,b],[c,d],…]。对得到的分类结果与相似向量[1,0]计算余弦距离。

得到一维数组 cos_value = [cos 1,cos 2,…]选出其中最大的cos值,然后找到其对应的input2的句子所属类别,最后返回该类问题的答案即可,这个新的问题可以作为该类问题的相似问题扩展,放入问题库。
六、后续
可以为机器人程序设计一个聊天页面,像淘宝客服的对话一样。还可以将程序植入有语音功能的机器人硬件里,完成用户机器人对话。
github源码地址
https://github.com/okfu-DL/similar_questions.git