计算机网络自顶向下方法 习题参考答案 第三章
复习题
R1.
a.
称这个简单的运输层协议为 STP。
在发送端,STP 接收应用程序要发送的数据(不超过 1196 字节)、目的地址、端口号;然后 STP 添加 4 字节头部信息,即端口号;将这 1200 字节的报文段连同目的地址交付给网络层;
在接收端,STP 提取端口和数据,将数据发送给端口所标志的程序。
b.
在头部信息中增加 4 字节的源端口号,将数据减少为 1192 字节。
c.
不。
R2.
略
R3.
y、x
R4.
一些应用程序不想使用 TCP,因为其拥塞控制会降低发送速率。而且应用本身并不需要可靠的数据传输。
R5.
因为今天大多数的防火墙会拦截 UDP
R6.
在应用层添加差错检测,需要程序开发人员在程序中添加一些检测代码
R7.
题目正确的翻译应该是:这两个报文段都将被定向到主机C上的同一个套接字吗?还不如直接 google 翻译呢。那么现在题目要求清楚了,两个报文段都将被定向到主机C上的同一个套接字。根据源 IP 区分不同主机。
R8.
通过不同的欢迎套接字。它们的目的端口都是 80。
R9.
判断究竟是新的分组还是重传
R10.
处理丢包事件,如果丢包可以重传
R11.
RTT 固定的好处就是发送方可以准确判断 ACK 是否丢失,不过它仍需要一个时间固定的定时器。
R12.
a.
接收方丢弃全部分组,之后发送方重传五个分组。
b.
GBN 使用累积确认,因此没有触发重传
c.
只能发送五个,因为窗口大小就是 5
R13.
a.
只重发第一个分组即可
b.
超时重发第一个分组
c.
只能发送五个,因为窗口大小就是 5
R14.
a. 错
b. 错
c. 对
d. 错
e. 对
f. 错
g. 错
R15.
a. 110 - 90 = 20byte
b. 90
R16.
依然是三个,第一个 seq=43 ack=80,第二个 seq=80 ack=44,第三个 seq=44 ack=81
R17.
R/2
R18.
错,设为 cwnd 的一半
R19.
略
习题
P1.
假定 A 向 S 的源端口号为 x, B 向 S 的源端口号为 y
a.
A 向 S 的源端口号为 x, 目的端口号为 23
b.
B 向 S 的源端口号为 y, 目的端口号为 23
c.
S 向 A 的源端口号为 23, 目的端口号为 x
d.
S 向 B 的源端口号为 23, 目的端口号为 y
e.
x y 可能相同
f.
不可能
P2.
从 B 到 C:
左边的连接:源端口号 80,源 IP 为 B 的 IP;目的端口 26145,目的 IP 为 C 的 IP;
右边的连接:源端口号 80,源 IP 为 B 的 IP;目的端口 7532,目的 IP 为 C 的 IP;
从 B 到 A:
源端口号 80,源 IP 为 B 的 IP;目的端口 26145,目的 IP 为 C 的 IP;
P3.
注意应在溢出时向最低位进位:
01010011
+ 01100110
————————————
10111001
+ 01110100
————————————
(1) 00101101
+ 1
————————————
00101110
其反码为 11010001
使用反码有以下好处:
- 不依赖系统是大端还是小端
- 计算检验和比较简单快速
接收方检验差错的方法是将三个字节与检验和相加,如果任何一个位为 0,说明出错
1比特的差错肯定会导致结果不同
2比特的差错可能会检测不出,比如题中第一、二字节变为 01010010,01100111,即最后一个比特反转
P4.
a. 00111110
b. 01000000
c. a 中的第一、二字节变为 01011101、01100100
P5.
不能确保,如同上两题讨论的那样
P6.
如果 rdt2.1 发送方正处于“等待来自上层的调用0”,接收方处于“等待来自下层的0”,发送方发送序号为 0 的分组,而接收方正确接收并向发送方发送 ACK;此时发送方处于“等待 ACK 或 NAK 0”,接收方处于“等待下层的 1”,如果此 ACK 损坏,发送方重发序号0的分组,而接收方会发送 NAK,这将导致一个死循环;
其实此接收方并没有标注初始状态,如果发送方初始状态为“等待来自上层的 0”,接收方初始为“等待下层的 1”,也会导致上述死锁。
P7.
ACK 分组没有序号是因为接收方、发送方都不需要该序号。
P8.
可以直接使用 rdt2.2 中的接收方
P9.

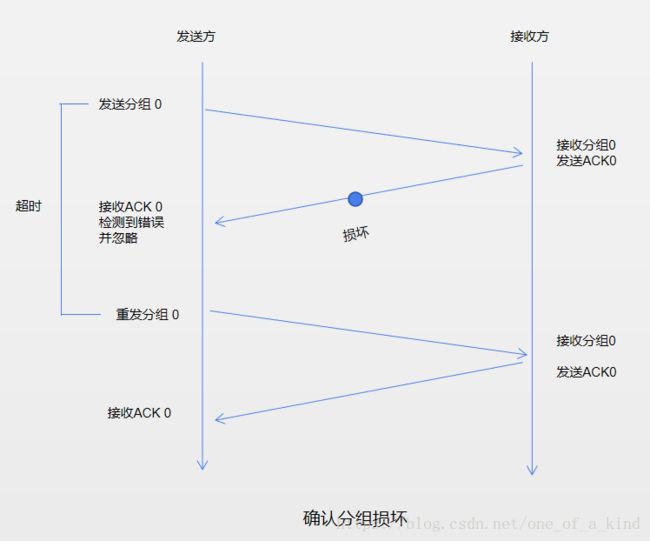
P10.
类似于 rdt3.0 的发送方,在 rdt2.1 的发送方上加上 start_timer 以及 timeout 事件即可。timer 的时间要大于最大往返时延。
P11.
如果从“等待来自下层的1”中删除,不会影响正常工作,因为 sndpkt 已经被生成了。
但是如果从“等待来自下层的0”中删除,而且接收方刚刚启动(处于初始状态),sndpkt 是一个错误的值(很可能是一个随机值),那么发送方会认为 ACK 损坏并重发分组,接收方会继续发送错误值,浙江导致一个死锁。
P12.
仅有一个比特差错时,协议正常工作,只不过可能比 rdt3.0 发送方反应更快。
而当定时器时间过短时,每一个超时重发的分组都将会导致正在发送的包重发,这样从第一个包累积到第n个包,分组发送的次数将趋于无穷。
P13.
像图片展示的那样,两个 M0 将无法区分

P14.
分组 x 丢失只能被接收方检测到,且只有 x-1,x+1 都被接收后。如果发送方在发送 x 之后隔较长时间才发送 x+1,那么这段时间 x 将一直不会被重发。
而当数据量较大且很少丢包时,用 NAK 协议发送的数据包的数量明显比 ACK 协议少
P15.
中文版翻译较差,错误极多,无力吐槽。。。这里按英文版的 98% 来做:
U = (nL/R) / (RTT + L/R) > 98%
解出 n > 2450.98
因此 n 至少是 2451
P16.
肯定能增加利用率,接收到 ACK0 或 ACK1 之后发送方认为分组已经成功到达,即使事实不是如此。
可能导致许多问题,例如差错出现并不会重发、造成无谓的重发等。
P17.
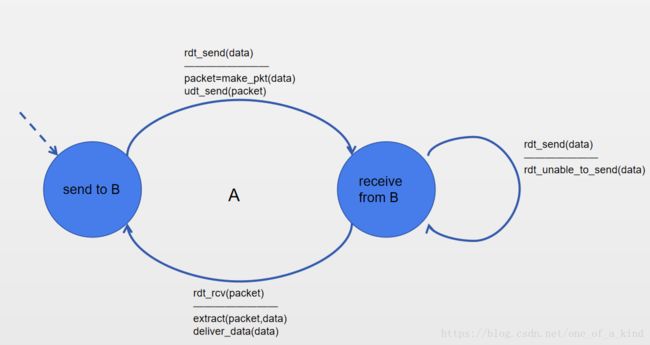
B与A类似,只不过初始状态从 receive from A 开始
P18.
略
P19.
略
P20.
略
P21.
略
P22.
a.
考虑两种极端情况:
- 发送方发送 k-4,k-3,k-2,k-1,接收方都完整得接收并发送 ACK,但 ACK 全都未传到发送方,接收方的期待序号为 k,而发送方窗口序号为 [k-4, k-1]
- 如果 ACK 全都传回,则发送方更新 base,其序号为 [k, k+3]
因此序号可能是 [k-4, k+3]
b.
如果接收方期待 k,则它一定将比 k-1 小的 ACK 发送出去了,如果要使发送方发送 k-1,那么它至少已经接收到了 k-5 的 ACK。
因此正在传播回发送方的 ACK 序号可能是 [k-4, k-1]
P23.
设序号为 0(第一个 0),1,…,k-1,0(第二个 0)
对于 SR,要使其序号发生混杂,至少是当接收方刚刚包含第二个 0,即接收方窗口为[k-N-1, 0],也就是说 k-N (包括 k-N) 之前的都接收过了。要使序号混杂还有一个条件就是第一个 0 在发送方窗口且恰好其 ACK 丢失,需要重发。0(第一个0)~k-N 为 k-N+1 个值,如果窗口长度不足 k-N+1,则第一个 0 和第二个 0 不会同时包含在发送或接收窗口中。
所以窗口长度 N <= k-N,即 N <= k/2
GBN 类似,N <= k 即可
P24.
a.
可能, ACK 还没来得及返回,发送方超时重发,之后发送方接收到 ACK 并移动窗口,那么它之前重发的分组的 ACK 将落在窗口之外
b.
可能,类似 a
c.
是的
d.
是的
P25.
a.
UDP 直接将用户数据打包进报文并立即传输,而 TCP 会将数据写进缓存并可能分成多个报文
b.
TCP 有流量控制和拥塞控制,而 UDP 没有
P26.
a.
注意到 TCP 是字节流编号的, L 的最大值为 2^32 byte
b.
设 N 为报文数:
N = ⌈ 2 32 536 ⌉ = 8012999 N = \lceil \frac{2^{32}}{536} \rceil = 8012999 N=⌈536232⌉=8012999
总 头 部 长 = N ∗ 66 b y t e = 528857934 b y t e 总头部长 = N * 66 byte = 528857934 byte 总头部长=N∗66byte=528857934byte
总 字 节 数 = 2 32 b y t e + 528857934 b y t e = 4.824 ∗ 1 0 9 b y t e 总字节数 = 2^{32} byte + 528857934 byte = 4.824*10^9byte 总字节数=232byte+528857934byte=4.824∗109byte
t = 总 字 节 数 155 M b p s = 249 s t = \frac{总字节数}{155Mbps} = 249s t=155Mbps总字节数=249s
P27.
a.
序号、源、目的端口号分别为 207、302、80
b.
序号、源、目的端口号分别为 207、80、302
c.
127
d.
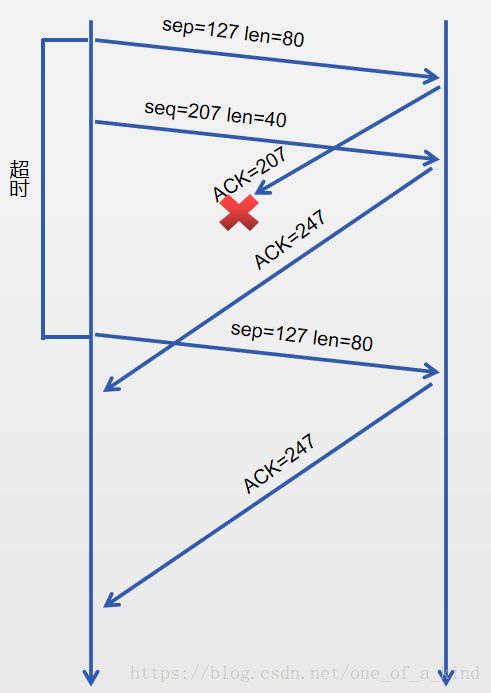
P28.
TCP 让发送方 A 维护一个接收窗口来提供流量控制,主机 B 将实时的 rwnd 值放入发给 A 的报文中,通知 B 的缓存大小。A 确保 LastByteSent - LastByteAcked <= rwnd,当缓存不足时,将暂停向 B 发送数据
P29.
a.
防止有攻击者发动 SYN 洪泛攻击
b.
不能。当服务器使用 SYN cookie 时,它不维护 cookie 或其他信息,因此半开连接不可行。攻击者并不知道某个服务器和某 IP 对应的初始序列号,因为那个秘密数只有服务器知道。
c.
理论上可行
P30.
a.
超时值是固定的,单一得增加有限缓存的长度,会导致未丢失的分组被重传
b.
有助于。
P31.
略,自己慢慢算算吧
P32.
a.
EstimatedRTT’
= 0.9 ( 0.9 ( 0.9 ( 0.9 EstimatedRTT + 0.1 SampleRTT1 ) + 0.1 SampleRTT2 ) + 0.1 SampleRTT3 ) + 0.1 SampleRTT4
= 0.9^4 EstimatedRTT + 0.1 SampleRTT4 + 0.9 * 0.1 SampleRTT3 + 0.9^2 * 0.1 SampleRTT2 + 0.9^3 * 0.1 SampleRTT1
b.
推广到 n:
EstimatedRTT’ = 0.9^n EstimatedRTT + 0.9^(n-1) * 0.1 SampleRTT1 + 0.9^(n-2) * 0.1 SampleRTT2 + … + 0.1 SampleRTTn
c.
根据上式:
E s t i m a t e d R T T ′ = 0. 9 n E s t i m a t e d R T T + 1 10 ∑ i = 1 n 0. 9 n − i S a m p l e R T T i EstimatedRTT' = 0.9^n EstimatedRTT + \frac{1}{10}\sum_{i=1}^{n}0.9^{n-i}SampleRTT_i EstimatedRTT′=0.9nEstimatedRTT+101∑i=1n0.9n−iSampleRTTi
可以看出 i 越小, S a m p l e R T T i SampleRTT_i SampleRTTi 对 E s t i m a t e d R T T ′ EstimatedRTT' EstimatedRTT′ 的影响越小,且其权重呈指数形式锐减
P33.
假设传递分组 1 到目的地,超时后源又重发分组 1 的副本分组 2;如果分组 1 的 ACK 返回到源,则源可能将它作为分组 2 的 ACK,从而计算了一个错误的 RTT
P34.
SendBase - 1 <= LastByteRcvd
LastByteRvcd 是刚到达 B 的编号, SendBase - 1 是已经到达 B 的编号
P35.
y 之前的所有字节都被接收,因此 y-1 <= LastByteRcvd
P36.
考虑当分组错序到达会发生什么,分组 1 正确到达,目的地发送 ACK,分组 3 提前于分组 2 到达,发送一个冗余 ACK,这将导致发送方重传分组 2,即使分组 2 并未丢失
P37.
a.
GBN:
A:首先发送分组 12345,后来重发 2345,总共 9 个分组
B:首先发送 ACK 1111,后来发送 2345,总共 5 个 ACK
SR:
A:首先发送分组 12345,后来重发 2,总共 6 个分组
B:首先发送 ACK 1345,后来发送 2,总共 5 个 ACK
TCP:
A:首先发送分组 12345,后来重发 2,总共 6 个分组
B:首先发送 ACK 2222,后来发送 6,总共 5 个 ACK
b.
GBN、SR 需要等待超时,而 TCP 使用快速重传,故 TCP 最快
P38.
是的
P39.
λ’in 超过 R/2,会导致更多的丢包以及重传,λout 可能会下降
P40.
a. [1, 6] 和 [23, 26]
b. [6, 16] 和 [17, 22]
c. 三个冗余 ACK
d. 超时
e. 32
f. 42/2 = 21
g. 29/2 = 14
h. 分组 1 (p1) 在传输轮回 1 (t1) 中发送,p2~p3 在 t2 中发送,p4~p7 在 t3 中发送,p8~p15 在 t4,p16~p31 在 t5,p32~p63 在 t6,p64~p96 在 t7,
因此分组 70 在第 7 个传输轮回内发送
i. ssthresh = 4,cwnd = ssthresh + 3MSS = 7
j. 在第16个传输轮回时,ssthresh = cwnd/2 = 21,cwnd = 1 并进入慢启动状态,则在第19个传输轮回中,ssthreash = 21,cwnd = 4
k. t17:1个,t18:2个,t19:4个,t20:8个,t21:16个,t22:21个
1 + 2 + 4 + 8 + 16 + 21 = 52 个
P41.
从图中可以看出,这不是一种平等算法

P42.
超时仅能减缓 分组未丢失超时重传 这种情况,不能阻止 TCP 向可能出现拥塞的端到端路径上继续发送更多的新的分组。
P43.
流量控制将无法适用,因为接受缓存足够大。
没有丢包、没有超时,因此拥塞控制也无法适用。
无需适用任何措施,当发送缓存满载时,自动就慢下来了。
P44.
a.
每个 RTT 加 1 个 MSS,因此需要 6 个 RTT
b.
6 + 7 + 8 + 9 + 10 + 11 = 51 MSS
平均吞吐量为 51MSS / 6RTT = 8.5 MSS/RTT
P45.
a.
从 W/2RTT 到 W/RTT 期间总共发送的分组数:
W 2 + ( W 2 + 1 ) + ( W 2 + 2 ) + . . . + W = ( W + W 2 ) ( W − W 2 + 1 ) 2 = 3 8 W 2 + 3 4 W \frac{W}{2} + (\frac{W}{2} + 1) + (\frac{W}{2} + 2) + ... + W=\frac{(W+\frac{W}{2})(W-\frac{W}{2}+1)}{2} = \frac{3}{8}W^2+\frac{3}{4}W 2W+(2W+1)+(2W+2)+...+W=2(W+2W)(W−2W+1)=83W2+43W
仅 丢 了 一 个 包 , 因 此 丢 包 率 L = 1 3 8 W 2 + 3 4 W 仅丢了一个包,因此丢包率 L = \frac{1}{\frac{3}{8}W^2+\frac{3}{4}W} 仅丢了一个包,因此丢包率L=83W2+43W1
b.
当 W 足 够 大 , 3 8 W 2 > > 3 4 W , 此 时 L ≈ 1 3 8 W 2 = 8 / 3 W 2 当 W 足够大, \frac{3}{8}W^2 >> \frac{3}{4}W,此时 L ≈ \frac{1}{\frac{3}{8}W^2} = 8/3W^2 当W足够大,83W2>>43W,此时L≈83W21=8/3W2
得 出 W ≈ 8 / 3 L 得出 W ≈ \sqrt{8/3L} 得出W≈8/3L
则 平 均 吞 吐 率 为 = 0.75 W R T T ≈ 1.22 M S S R T T L 则平均吞吐率为 = \frac{0.75W}{RTT} ≈ \frac{1.22MSS}{RTT\sqrt{L}} 则平均吞吐率为=RTT0.75W≈RTTL1.22MSS
P46.
a.
最大窗口长度 W 受限于链路速率:W * MSS / RTT = 10Mbps
得到 W = 125
b.
从 W/2 到 W:
平均窗口长度为 0.75W = 94
平均吞吐量为 94 * 1500 * 8 / 0.15 = 7.52Mbps
c.
W’ = W/2 + 3 = 65
从 W’ 到 W:
(125-65)*150ms = 9s
P47.
不会
P48.
a.
W*MSS/RTT = 10Gbps
W = 125000
b.
7.52Gbps
c.
156.2min
P49.
已知 TCP 平均吞吐量 D = 1.22 M S S R T T L D = \frac{1.22MSS}{RTT\sqrt{L}} D=RTTL1.22MSS
L = ( 1.22 M S S R T T ∗ D ) 2 L=(\frac{1.22MSS}{RTT*D})^{2} L=(RTT∗D1.22MSS)2
1 L 为 丢 包 后 ( 的 那 一 刻 ) T C P 发 送 的 总 分 组 数 ( 因 为 只 丢 了 一 个 包 ) \frac{1}{L}为丢包后(的那一刻) TCP 发送的总分组数(因为只丢了一个包) L1为丢包后(的那一刻)TCP发送的总分组数(因为只丢了一个包)
则 M S S L = T ∗ D , T = D ∗ R T T 2 1.2 2 2 M S S \frac{MSS}{L}=T*D,T=\frac{D*RTT^{2}}{1.22^{2}MSS} LMSS=T∗D,T=1.222MSSD∗RTT2
因此 T 是 D 的函数
P50.
每秒发送最多 30 个报文段,即每 100ms 最多发送 3 个,每 50ms 最多发送 1 个;无论何时发生丢包,假定 C1 每 100ms 调整一次窗口, C2 每 50ms 调整一次。
a.
| t/ms | C1.cwnd/报文段 | C2.cwnd/报文段 |
|---|---|---|
| 0 | 10 | 10 |
| 50 | 5↓ (↓ 的意思是因丢包而减少一半) | 10 |
| 100 | 2↓ | 5↓ |
| 150 | 1↓ | 5 |
| 200 | 1▲ (▲ 的意思是无法继续减少) | 2↓ |
| 250 | 1▲ | 2 |
| 300 | 1▲ | 1↓ |
| 350 | 2↑(↑ 的意思是加性增) | 1 |
| 400 | 1↓ | 1▲ |
| 450 | 2↑ | 1 |
| 500 | 1↓ | 1▲ |
| 550 | 2↑ | 1 |
| 600 | 1↓ | 1▲ |
| 650 | 2↑ | 1 |
| 700 | 1↓ | 1▲ |
| 750 | 2↑ | 1 |
| 800 | 1↓ | 1▲ |
| 850 | 2↑ | 1 |
| 900 | 1↓ | 1▲ |
| 950 | 2↑ | 1 |
| 1000 | 1↓ | 1▲ |
因此它们的拥塞窗口为 1、1
b.
C1 明显比 C2 占有的带宽多一些,是 C2 的三倍
P51.
类似上一题
a.
都是2
| t/ms | C1.cwnd/报文段 | C2.cwnd/报文段 |
|---|---|---|
| 0 | 15 | 10 |
| 100 | 7↓ | 5↓ |
| 200 | 3↓ | 2↓ |
| 300 | 1↓ | 1↓ |
| 400 | 2↑ | 2↑ |
| 500 | 1↓ | 1↓ |
| 600 | 2↑ | 2↑ |
| 700 | 1↓ | 1↓ |
| 800 | 2↑ | 2↑ |
| 900 | 1↓ | 1↓ |
| 1000 | 2↑ | 2↑ |
| 1100 | 1↓ | 1↓ |
| 1200 | 2↑ | 2↑ |
| 1300 | 1↓ | 1↓ |
| 1400 | 2↑ | 2↑ |
| 1500 | 1↓ | 1↓ |
| 1600 | 2↑ | 2↑ |
| 1700 | 1↓ | 1↓ |
| 1800 | 2↑ | 2↑ |
| 1900 | 1↓ | 1↓ |
| 2000 | 2↑ | 2↑ |
| 2100 | 1↓ | 1↓ |
| 2200 | 2↑ | 2↑ |
b.
是的
c.
是的,都是2
d.
不利于改善利用率
当 C1 C2 的窗口大小都为 1 时,这条链路无法满载。
可以增设一个缓冲区,在缓冲区溢出之前随机丢弃一些分组。主动队列管理,随机早期检测等都用到了此种方法。
P52.
1.
类似 P45:
S = W 2 + W 2 ( 1 + a ) + W 2 ( 1 + a ) 2 + . . . + W S=\frac{W}{2}+\frac{W}{2}(1+a)+\frac{W}{2}(1+a)^2+...+W S=2W+2W(1+a)+2W(1+a)2+...+W
设 W 2 ( 1 + a ) n = W \frac{W}{2}(1+a)^n=W 2W(1+a)n=W :
得 n = log 1 + a 2 n=\log_{1+a}2 n=log1+a2
从而 S = W ( 2 a + 1 ) 2 a S=\frac{W(2a+1)}{2a} S=2aW(2a+1)
则丢包率 L = 1 S = 2 a W ( 2 a + 1 ) L=\frac{1}{S}=\frac{2a}{W(2a+1)} L=S1=W(2a+1)2a
2.
从 W/2 增加到 W 需要的时间:
n ∗ R T T = l o g 1 + a 2 ∗ R T T n*RTT=log_{1+a}2*RTT n∗RTT=log1+a2∗RTT
跟吞吐量无关
P53.
根据公式:
D = 1.22 M S S R T T L D=\frac{1.22MSS}{RTT\sqrt{L}} D=RTTL1.22MSS
L = ( 1.22 M S S R T T ∗ D ) 2 = ( 1.22 ∗ 1500 b y t e 0.1 s ∗ 10 G b p s ) 2 = ( 14640 1 0 9 ) 2 = 2 ∗ 1 0 − 10 L=(\frac{1.22MSS}{RTT*D})^{2}=(\frac{1.22*1500byte}{0.1s*10Gbps})^{2}=(\frac{14640}{10^9})^{2}=2*10^{-10} L=(RTT∗D1.22MSS)2=(0.1s∗10Gbps1.22∗1500byte)2=(10914640)2=2∗10−10
而当 D’ = 100Gbps 时:
L = ( 14640 1 0 1 0 ) 2 = 2 ∗ 1 0 − 12 L=(\frac{14640}{10^10})^{2}=2*10^{-12} L=(101014640)2=2∗10−12
P54.
优点是无需经历慢启动过程
缺点是 t1 时刻的 cwnd 和 ssthresh 比较陈旧,不能正确反映 t2 时刻的线路拥塞状态
P55.
a.
Y
b.
可以确认,SYNACK 将发到 Y,攻击者无法得知初始的序号,也就无法发回正确的 ACK
P56.
略