Bert核心代码解读
前面已经介绍了如何先测试一个bert任务,对这方面还不了解的可以看一下前面的博客。
BERT 最主要的模型实现部分---BertModel,代码位于
- modeling.py 模块
为了便于理解,下面的代码中的batch_size假设成8,seq_length长度是128,每个词编码后的向量纬度是768。
配置类(BertConfig)
class BertConfig(object):
"""BERT模型的配置类."""
def __init__(self,
vocab_size,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
initializer_range=0.02):
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.initializer_range = initializer_range
@classmethod
def from_dict(cls, json_object):
"""Constructs a `BertConfig` from a Python dictionary of parameters."""
config = BertConfig(vocab_size=None)
for (key, value) in six.iteritems(json_object):
config.__dict__[key] = value
return config
@classmethod
def from_json_file(cls, json_file):
"""Constructs a `BertConfig` from a json file of parameters."""
with tf.gfile.GFile(json_file, "r") as reader:
text = reader.read()
return cls.from_dict(json.loads(text))
def to_dict(self):
"""Serializes this instance to a Python dictionary."""
output = copy.deepcopy(self.__dict__)
return output
def to_json_string(self):
"""Serializes this instance to a JSON string."""
return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"参数的定义:
-
vocab_size:词表大小
-
hidden_size:隐藏层神经元数
-
num_hidden_layers:Transformer encoder 中的隐藏层数
-
*num_attention_heads:*multi-head attention 的 head 数
-
intermediate_size:encoder 的“中间”隐层神经元数(例如 feed-forward layer)
-
hidden_act:隐藏层激活函数
-
hidden_dropout_prob:隐层 dropout 率
-
attention_probs_dropout_prob:注意力部分的 dropout
-
max_position_embeddings:最大位置编码
-
type_vocab_size:token_type_ids 的词典大小
-
initializer_range:truncated_normal_initializer 初始化方法的 stdev
这里要注意一点,可能刚看的时候对type_vocab_size这个参数会有点不理解,其实就是在next sentence prediction任务里的Segment A和 Segment B。在下载的bert_config.json文件里也有说明,默认值应该为 2。
函数入口(init)
上面看完了类的定义后,这个文件的主要代码在BertModel里面,我们来看一下BertModel 类的构造函数。
def __init__(self,
config, # BertConfig对象
is_training,
input_ids, # 【batch_size, seq_length】
input_mask=None, # 【batch_size, seq_length】
token_type_ids=None, # 【batch_size, seq_length】
use_one_hot_embeddings=False, # 是否使用one-hot;否则tf.gather()
scope=None):
config = copy.deepcopy(config)
if not is_training:
config.hidden_dropout_prob = 0.0
config.attention_probs_dropout_prob = 0.0
input_shape = get_shape_list(input_ids, expected_rank=2)
batch_size = input_shape[0]
seq_length = input_shape[1]
# 不做mask,即所有元素为1
if input_mask is None:
input_mask = tf.ones(shape=[batch_size, seq_length], dtype=tf.int32)
if token_type_ids is None:
token_type_ids = tf.zeros(shape=[batch_size, seq_length], dtype=tf.int32)
with tf.variable_scope(scope, default_name="bert"):
with tf.variable_scope("embeddings"): # 构建词嵌入层
# word embedding
(self.embedding_output, self.embedding_table) = embedding_lookup( # 将词转换成向量
input_ids=input_ids, # 8x128
vocab_size=config.vocab_size, # 模型中的词表
embedding_size=config.hidden_size, # 想要把词映射成多少纬度,tf官网给出的纬度是768。
initializer_range=config.initializer_range, #初始化取值范围
word_embedding_name="word_embeddings",
use_one_hot_embeddings=use_one_hot_embeddings)
# 添加position embedding和segment embedding
# layer norm + dropout
self.embedding_output = embedding_postprocessor( # 加入位置编码
input_tensor=self.embedding_output,
use_token_type=True,
token_type_ids=token_type_ids,
token_type_vocab_size=config.type_vocab_size,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=config.initializer_range,
max_position_embeddings=config.max_position_embeddings,
dropout_prob=config.hidden_dropout_prob)
with tf.variable_scope("encoder"):
# input_ids是经过padding的word_ids:[25, 120, 34, 0, 0]
# input_mask是有效词标记:[1, 1, 1, 0, 0]
attention_mask = create_attention_mask_from_input_mask(
input_ids, input_mask)
# transformer模块叠加
# `sequence_output` shape = [batch_size, seq_length, hidden_size].
self.all_encoder_layers = transformer_model(
input_tensor=self.embedding_output,
attention_mask=attention_mask,
hidden_size=config.hidden_size,
num_hidden_layers=config.num_hidden_layers,
num_attention_heads=config.num_attention_heads,
intermediate_size=config.intermediate_size,
intermediate_act_fn=get_activation(config.hidden_act),
hidden_dropout_prob=config.hidden_dropout_prob,
attention_probs_dropout_prob=config.attention_probs_dropout_prob,
initializer_range=config.initializer_range,
do_return_all_layers=True)
# `self.sequence_output`是最后一层的输出,shape为【batch_size, seq_length, hidden_size】
self.sequence_output = self.all_encoder_layers[-1]
# ‘pooler’部分将encoder输出【batch_size, seq_length, hidden_size】
# 转成【batch_size, hidden_size】
with tf.variable_scope("pooler"):
# 取最后一层的第一个时刻[CLS]对应的tensor, 对于分类任务很重要
# sequence_output[:, 0:1, :]得到的是[batch_size, 1, hidden_size]
# 我们需要用squeeze把第二维去掉
first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)
# 然后再加一个全连接层,输出仍然是[batch_size, hidden_size]
self.pooled_output = tf.layers.dense(
first_token_tensor,
config.hidden_size,
activation=tf.tanh,
kernel_initializer=create_initializer(config.initializer_range))接下来我们将会按照init代码从上到下解读主要函数的代码。
获取词向量(Embedding_lookup)
def embedding_lookup(input_ids, # word_id:【batch_size, seq_length】
vocab_size,
embedding_size=128,
initializer_range=0.02,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=False):
# 该函数默认输入的形状为【batch_size, seq_length, input_num】 比如8X128
# 如果输入为2D的【batch_size, seq_length】,则扩展到【batch_size, seq_length, 1】
if input_ids.shape.ndims == 2:
input_ids = tf.expand_dims(input_ids, axis=[-1])
embedding_table = tf.get_variable( # 词映射矩阵,30522,768,在词表内进行查找
name=word_embedding_name,
shape=[vocab_size, embedding_size], # 30522,768
initializer=create_initializer(initializer_range))
flat_input_ids = tf.reshape(input_ids, [-1]) #【batch_size*seq_length*input_num】
if use_one_hot_embeddings:
one_hot_input_ids = tf.one_hot(flat_input_ids, depth=vocab_size)
output = tf.matmul(one_hot_input_ids, embedding_table)
else: # 按索引取值
output = tf.gather(embedding_table, flat_input_ids) # 一个batch里所有的映射结果
input_shape = get_shape_list(input_ids)
# output:[batch_size, seq_length, num_inputs]
# 转成:[batch_size, seq_length, num_inputs*embedding_size]
output = tf.reshape(output,
input_shape[0:-1] + [input_shape[-1] * embedding_size])
return (output, embedding_table) # (8,128,768)参数定义:
-
input_ids:word id 【batch_size, seq_length】
-
vocab_size:embedding 词表
-
embedding_size:embedding 维度
-
initializer_range:embedding 初始化范围
-
word_embedding_name:embeddding table 命名
-
use_one_hot_embeddings:是否使用 one-hotembedding
-
Return:【batch_size, seq_length, embedding_size】
该模块是将一个词转换成向量的模块,它的输入是batch_size*seq_length,输出是batch_size, seq_length, embedding_size。这个embedding_size是每个词所映射成向量后的纬度。在编码向量的时候此处就是在bert预训练好的模型中查找词的向量。bert_model.ckpt.data-00000-of-00001里面存放的是训练好的词向量,vocab.txt里面存放的是词表。具体存放如下所示:

位置编码(embedding_postprocessor)
我们知道 BERT 模型的输入有三部分:token embedding ,segment embedding以及position embedding。在 Transformer 论文中的position embedding是由 sin/cos 函数生成的固定的值,而在这里代码实现中是跟普通 word embedding 一样随机生成的,可以训练的。
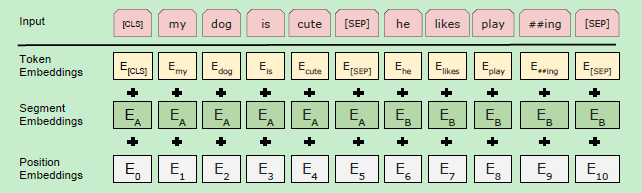
def embedding_postprocessor(input_tensor, # [batch_size, seq_length, embedding_size]
use_token_type=False,
token_type_ids=None,
token_type_vocab_size=16, # 一般是2
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=0.02,
max_position_embeddings=512, #最大位置编码,必须大于等于max_seq_len
dropout_prob=0.1):
input_shape = get_shape_list(input_tensor, expected_rank=3) #【batch_size,seq_length,embedding_size】
batch_size = input_shape[0]
seq_length = input_shape[1]
width = input_shape[2]
output = input_tensor
# Segment position信息
if use_token_type:
if token_type_ids is None:
raise ValueError("`token_type_ids` must be specified if"
"`use_token_type` is True.")
token_type_table = tf.get_variable( # (2,768),2的意思是只有两种结果,第一句和第二句,第一句用0表示,第二句用1表示
name=token_type_embedding_name,
shape=[token_type_vocab_size, width],
initializer=create_initializer(initializer_range))
# This vocab will be small so we always do one-hot here, since it is always
# faster for a small vocabulary.
# 由于token-type-table比较小,所以这里采用one-hot的embedding方式加速
flat_token_type_ids = tf.reshape(token_type_ids, [-1]) # 对8x128=1024个词都要找到segment position信息,每个词有两种可能性
one_hot_ids = tf.one_hot(flat_token_type_ids, depth=token_type_vocab_size)# 1024,2和2,768做乘法
token_type_embeddings = tf.matmul(one_hot_ids, token_type_table)
token_type_embeddings = tf.reshape(token_type_embeddings,
[batch_size, seq_length, width]) # 8,128,768
output += token_type_embeddings
# Position embedding信息
if use_position_embeddings:
# 确保seq_length小于等于max_position_embeddings
assert_op = tf.assert_less_equal(seq_length, max_position_embeddings)
with tf.control_dependencies([assert_op]):
full_position_embeddings = tf.get_variable(
name=position_embedding_name,
shape=[max_position_embeddings, width],
initializer=create_initializer(initializer_range))
# 这里position embedding是可学习的参数,[max_position_embeddings, width]
# 但是通常实际输入序列没有达到max_position_embeddings
# 所以为了提高训练速度,使用tf.slice取出句子长度的embedding
position_embeddings = tf.slice(full_position_embeddings, [0, 0],
[seq_length, -1]) # 位置编码纬度过大,此处为了加速只取出有用的部分,128,768
num_dims = len(output.shape.as_list())
# word embedding之后的tensor是[batch_size, seq_length, width]
# 因为位置编码是与输入内容无关,它的shape总是[seq_length, width]
# 我们无法把位置Embedding加到word embedding上
# 因此我们需要扩展位置编码为[1, seq_length, width]
# 然后就能通过broadcasting加上去了。
position_broadcast_shape = []
for _ in range(num_dims - 2):
position_broadcast_shape.append(1)
position_broadcast_shape.extend([seq_length, width])
position_embeddings = tf.reshape(position_embeddings, # [1,128,768]表示位置编码跟输入数据无关
position_broadcast_shape)
output += position_embeddings
output = layer_norm_and_dropout(output, dropout_prob)
return output先加上了一个segment position的信息,然后才加Position embedding的信息。先初始化一个(2,768)的矩阵,2的意思是只有两种结果,第一句和第二句,第一句用0表示,第二句用1表示。然后在做segment的时候对8x128=1024个词都要找到segment position信息,每个词有两种可能性。找的方法是用矩阵的乘法。(1024,2)和(2,768)大小的矩阵做乘法。
在加上位置编码的时候先初始化一个位置矩阵,刚开始初始化矩阵的纬度可能比较大,假设是512,也就是说有512个位置。矩阵的大小是512*768,目的在于和词向量长度一样。然后取和seq_length大小一样的部分,此处seq_length的大小是128。得到的位置编码矩阵大小是128x768,768是保证和词向量的纬度相同,后面将位置编码进行扩展并且和词向量进行相加。返回的output是整个embedding的结果。
构造 attention_mask
该模块大概理解作用即可,此处不再对代码进行过多的解读。它的输入是一个二维的向量,输出是一个3D的矩阵。新增的纬度作用在于让一句话中的每一个词编码的向量能够看到自己可以进行计算的向量。下面我用一个图来解释,假设下图中的向量是8个句子做完embedding后的向量,后面的0代表句子的长度已结束。此时第一个句子的第一个编码在后面做self-Attention所需要和该句子中的其他向量计算,那么该和哪些向量计算呐?此处就是用新增加的纬度来表示需要计算的词向量,图中下部分是转换成3D后新增加的一个向量来表示和哪些词进行计算,1代表能计算,0代表不进行计算。该部分的核心代码在create_attention_mask_from_input_mask模块。
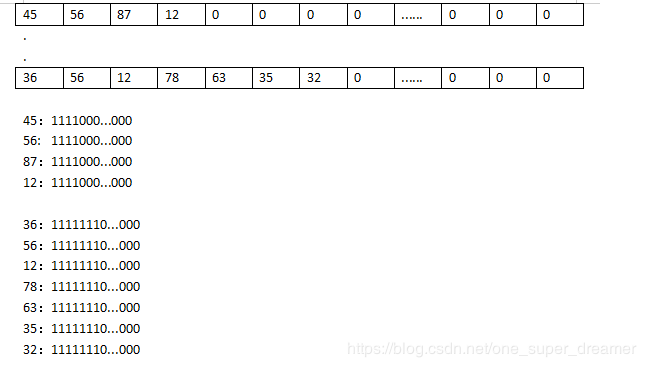
注意力层(attention layer)
这部分代码是「multi-head attention」的实现,主要来自《Attention is all you need》这篇论文。考虑key-query-value形式的 attention,输入的from_tensor当做是 query, to_tensor当做是 key 和 value,当两者相同的时候即为 self-attention。
def attention_layer(from_tensor, # 【batch_size, from_seq_length, from_width】
to_tensor, #【batch_size, to_seq_length, to_width】
attention_mask=None, #【batch_size,from_seq_length, to_seq_length】
num_attention_heads=1, # attention head numbers
size_per_head=512, # 每个head的大小
query_act=None, # query变换的激活函数
key_act=None, # key变换的激活函数
value_act=None, # value变换的激活函数
attention_probs_dropout_prob=0.0, # attention层的dropout
initializer_range=0.02, # 初始化取值范围
do_return_2d_tensor=False, # 是否返回2d张量。
#如果True,输出形状【batch_size*from_seq_length,num_attention_heads*size_per_head】
#如果False,输出形状【batch_size, from_seq_length, num_attention_heads*size_per_head】
batch_size=None, #如果输入是3D的,
#那么batch就是第一维,但是可能3D的压缩成了2D的,所以需要告诉函数batch_size
from_seq_length=None, # 同上
to_seq_length=None): # 同上
def transpose_for_scores(input_tensor, batch_size, num_attention_heads,
seq_length, width):
output_tensor = tf.reshape(
input_tensor, [batch_size, seq_length, num_attention_heads, width])
output_tensor = tf.transpose(output_tensor, [0, 2, 1, 3]) #[batch_size, num_attention_heads, seq_length, width]
return output_tensor
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
to_shape = get_shape_list(to_tensor, expected_rank=[2, 3])
if len(from_shape) != len(to_shape):
raise ValueError(
"The rank of `from_tensor` must match the rank of `to_tensor`.")
if len(from_shape) == 3:
batch_size = from_shape[0]
from_seq_length = from_shape[1]
to_seq_length = to_shape[1]
elif len(from_shape) == 2:
if (batch_size is None or from_seq_length is None or to_seq_length is None):
raise ValueError(
"When passing in rank 2 tensors to attention_layer, the values "
"for `batch_size`, `from_seq_length`, and `to_seq_length` "
"must all be specified.")
# 为了方便备注shape,采用以下简写:
# B = batch size (number of sequences) 8
# F = `from_tensor` sequence length 128
# T = `to_tensor` sequence length 128
# N = `num_attention_heads` 12
# H = `size_per_head` 每个头有64个特征
# 把from_tensor和to_tensor压缩成2D张量
# 把from_tensor和to_tensor压缩成2D张量
from_tensor_2d = reshape_to_matrix(from_tensor) # 【B*F, hidden_size】
to_tensor_2d = reshape_to_matrix(to_tensor) # 【B*T, hidden_size】
# 将from_tensor输入全连接层得到query_layer
# `query_layer` = [B*F, N*H]
query_layer = tf.layers.dense(
from_tensor_2d,
num_attention_heads * size_per_head,
activation=query_act,
name="query",
kernel_initializer=create_initializer(initializer_range))
# 将from_tensor输入全连接层得到query_layer
# `key_layer` = [B*T, N*H]
key_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=key_act,
name="key",
kernel_initializer=create_initializer(initializer_range))
# 同上
# `value_layer` = [B*T, N*H]
value_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=value_act,
name="value",
kernel_initializer=create_initializer(initializer_range))
# query_layer转成多头:[B*F, N*H]==>[B, F, N, H]==>[B, N, F, H]
query_layer = transpose_for_scores(query_layer, batch_size,
num_attention_heads, from_seq_length,
size_per_head)
# key_layer转成多头:[B*T, N*H] ==> [B, T, N, H] ==> [B, N, T, H]
key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads,
to_seq_length, size_per_head)
# 将query与key做点积,然后做一个scale,公式可以参见原始论文
# `attention_scores` = [B, N, F, T]
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
attention_scores = tf.multiply(attention_scores,
1.0 / math.sqrt(float(size_per_head)))
if attention_mask is not None:
# `attention_mask` = [B, 1, F, T]
attention_mask = tf.expand_dims(attention_mask, axis=[1])
# 如果attention_mask里的元素为1,则通过下面运算有(1-1)*-10000,adder就是0
# 如果attention_mask里的元素为0,则通过下面运算有(1-0)*-10000,adder就是-10000
adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0
# 我们最终得到的attention_score一般不会很大,
#所以上述操作对mask为0的地方得到的score可以认为是负无穷
attention_scores += adder
# 负无穷经过softmax之后为0,就相当于mask为0的位置不计算attention_score
# `attention_probs` = [B, N, F, T]
attention_probs = tf.nn.softmax(attention_scores)
# 对attention_probs进行dropout,这虽然有点奇怪,但是Transforme原始论文就是这么做的
attention_probs = dropout(attention_probs, attention_probs_dropout_prob)
# `value_layer` = [B, T, N, H]
value_layer = tf.reshape(
value_layer,
[batch_size, to_seq_length, num_attention_heads, size_per_head])
# `value_layer` = [B, N, T, H]
value_layer = tf.transpose(value_layer, [0, 2, 1, 3])
# `context_layer` = [B, N, F, H]
context_layer = tf.matmul(attention_probs, value_layer)
# `context_layer` = [B, F, N, H]
context_layer = tf.transpose(context_layer, [0, 2, 1, 3])
if do_return_2d_tensor:
# `context_layer` = [B*F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size * from_seq_length, num_attention_heads * size_per_head])
else:
# `context_layer` = [B, F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size, from_seq_length, num_attention_heads * size_per_head])
return context_layerattention layer 的主要流程:
-
对输入的 tensor 进行形状校验,提取
batch_size、from_seq_length 、to_seq_length; -
输入如果是 3d 张量则转化成 2d 矩阵;
-
from_tensor 作为 query, to_tensor 作为 key 和 value,经过一层全连接层后得到 query_layer、key_layer 、value_layer;
-
将上述张量通过
transpose_for_scores转化成 multi-head; -
根据论文公式计算 attention_score 以及 attention_probs(注意 attention_mask 的 trick):

-
将得到的 attention_probs 与 value 相乘,返回 2D 或 3D 张量

Transformer
def transformer_model(input_tensor, # 【batch_size, seq_length, hidden_size】
attention_mask=None, # 【batch_size, seq_length, seq_length】
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
intermediate_act_fn=gelu, # feed-forward层的激活函数
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
initializer_range=0.02,
do_return_all_layers=False):
# 这里注意,因为最终要输出hidden_size, 我们有num_attention_head个区域,
# 每个head区域有size_per_head多的隐层
# 所以有 hidden_size = num_attention_head * size_per_head
if hidden_size % num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
attention_head_size = int(hidden_size / num_attention_heads)
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
input_width = input_shape[2]
# 因为encoder中有残差操作,所以需要shape相同
if input_width != hidden_size:
raise ValueError("The width of the input tensor (%d) != hidden size (%d)" %
(input_width, hidden_size))
# reshape操作在CPU/GPU上很快,但是在TPU上很不友好
# 所以为了避免2D和3D之间的频繁reshape,我们把所有的3D张量用2D矩阵表示
prev_output = reshape_to_matrix(input_tensor)
all_layer_outputs = []
for layer_idx in range(num_hidden_layers):
with tf.variable_scope("layer_%d" % layer_idx):
layer_input = prev_output
with tf.variable_scope("attention"):
# multi-head attention
attention_heads = []
with tf.variable_scope("self"):
# self-attention
attention_head = attention_layer(
from_tensor=layer_input,
to_tensor=layer_input,
attention_mask=attention_mask,
num_attention_heads=num_attention_heads,
size_per_head=attention_head_size,
attention_probs_dropout_prob=attention_probs_dropout_prob,
initializer_range=initializer_range,
do_return_2d_tensor=True,
batch_size=batch_size,
from_seq_length=seq_length,
to_seq_length=seq_length)
attention_heads.append(attention_head)
attention_output = None
if len(attention_heads) == 1:
attention_output = attention_heads[0]
else:
# 如果有多个head,将他们拼接起来
attention_output = tf.concat(attention_heads, axis=-1)
# 对attention的输出进行线性映射, 目的是将shape变成与input一致
# 然后dropout+residual+norm
with tf.variable_scope("output"):
attention_output = tf.layers.dense(
attention_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
attention_output = dropout(attention_output, hidden_dropout_prob)
attention_output = layer_norm(attention_output + layer_input)
# feed-forward
with tf.variable_scope("intermediate"):
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range))
# 对feed-forward层的输出使用线性变换变回‘hidden_size’
# 然后dropout + residual + norm
with tf.variable_scope("output"):
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
layer_output = dropout(layer_output, hidden_dropout_prob)
layer_output = layer_norm(layer_output + attention_output)
prev_output = layer_output
all_layer_outputs.append(layer_output)
if do_return_all_layers:
final_outputs = []
for layer_output in all_layer_outputs:
final_output = reshape_from_matrix(layer_output, input_shape)
final_outputs.append(final_output)
return final_outputs
else:
final_output = reshape_from_matrix(prev_output, input_shape)
return final_output
如果对transformer理论还不是很理解的可以转到https://blog.csdn.net/one_super_dreamer/article/details/105181690