透彻理解高斯过程Gaussian Process (GP)
透彻理解高斯过程Gaussian Process (GP)
一、整体说说
为了理解高斯过程,我们就首先需要了解如下预备知识,即:高斯分布(函数)、随机过程、以及贝叶斯概率等。明白了这些预备知识之后才能顺利进入高斯过程,了解高斯过程本质及其高斯过程描述方法。人们又将高斯过程与贝叶斯概率有机结合在一起,构造了强大的数学方法(或称模型),为人类提供解决日常生活和工作的问题。特别是在人工智能领域更是意义非凡。为什么呢?
- 高斯过程模型属于无参数模型,相对解决的问题复杂度及与其它算法比较减少了算法计算量。
- 高斯模型可以解决高维空间(实际上是无限维)的数学问题,可以面对负杂的数学问题。
- 结合贝叶斯概率算法,可以实现通过先验概率,推导未知后验输入变量的后验概率。由果推因的概率。
- 高斯过程观测变量空间是连续域,时间或空间。
- 高斯过程观测变量空间是实数域的时候,我们就可以进行回归而实现预测。
- 高斯过程观测变量空间是整数域的时候(观测点是离散的),我们就可以进行分类。结合贝叶斯算法甚至可以实现单类分类学习(训练),面对小样本就可以实现半监督学习而后完成分类。面对异常检测领域很有用,降低打标签成本(小样本且单类即可训练模型)。
所以说,我们快点进入高斯过程-贝叶斯概率算法模型吧,功能非凡。
接下来慢慢展开学习之旅吧。
二、高斯分布(高斯函数)
https://blog.csdn.net/jorg_zhao/article/details/52687448
https://blog.csdn.net/zyttae/article/details/41086773
(一)一维高斯函数
一维高斯函数定义 一 维 高 斯 函 数 定 义
若随机变量 X X 服从一个位置参数为 μ μ 、尺度参数为 σ σ 的概率分布(正态分布),记为:X∼N(μ,σ2). X ∼ N ( μ , σ 2 ) .则其概率密度函数为f(x)=1σ2π−−√e−(x−μ)22σ2 f ( x ) = 1 σ 2 π e − ( x − μ ) 2 2 σ 2正态分布的数学期望值(或期望值) μ μ 等于位置参数,决定了分布曲线的位置;其方差 σ2 σ 2 的开平方或标准差 σ σ 等于尺度参数,决定了分布曲线的幅度。正态分布的概率密度函数曲线呈钟形,因此人们又经常称之为钟形曲线 “bellcurve” “ b e l l c u r v e ” 。
我们通常所说的标准正态分布是位置参数 μ=0 μ = 0 ,尺度参数 σ=1 σ = 1 的正态分布(见下图中红色曲线)。

对于任意的实数 a,b,c a , b , c ,
a=1σ2π√是曲线尖峰的高度,b=μ是尖峰中心的坐标,c=σ称为标准方差,表征的是bell钟状的宽度。钟形曲线下的总面积和永远为1 a = 1 σ 2 π 是 曲 线 尖 峰 的 高 度 , b = μ 是 尖 峰 中 心 的 坐 标 , c = σ 称 为 标 准 方 差 , 表 征 的 是 b e l l 钟 状 的 宽 度 。 钟 形 曲 线 下 的 总 面 积 和 永 远 为 1 。
- 为什么用概率密度函数表示高斯正态分布的函数:这种方法能够表示随机变量每个取值有多大的可能性。其它方法我们这里不在描述了,如:累积分布函数,cumulant、特征函数、动差生成函数以及cumulant-生成函数。
- 正态分布中一些值得注意的现象(量):
- 密度函数关于平均值 μ μ 对称。
- 平均值与它的众数(statistical mode)以及中位数(median)同一数值。
- 函数曲线下68.268949%的面积在平均数左右的一个标准差范围内。
- 95.449974%的面积在平均数左右两个标准差2 \sigma的范围内。
- 99.730020%的面积在平均数左右三个标准差3 \sigma的范围内。
- 99.993666%的面积在平均数左右四个标准差4 \sigma的范围内。
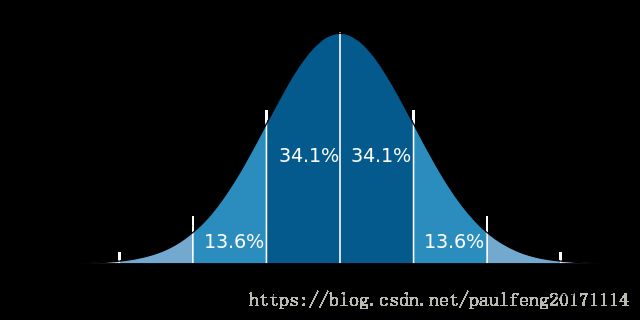
- 其中:
- μ=1m∑mi=1x(i)σ2=1m∑mi=1(x(i)−μ)2) μ = 1 m ∑ i = 1 m x ( i ) σ 2 = 1 m ∑ i = 1 m ( x ( i ) − μ ) 2 )
-
在机器学习中,用于故障检测时,训练数据集
X X 是已知,而且不需要有标签,可以作为非监督学习训练。
高斯分布样例如下图(引自吴恩达课件):
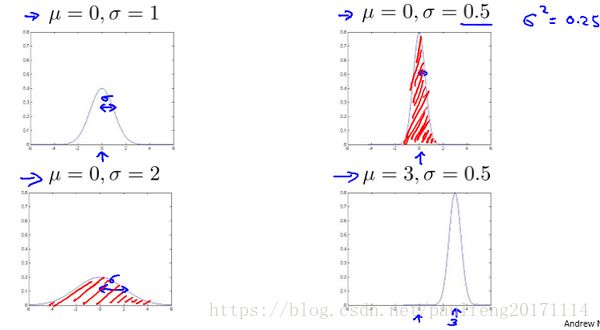
注:机器学习中对于方差我们通常只除以 m m 而非统计学中的 m−1 m − 1 (因为均值进去一个点)。这里顺便提一下,在实际使用中,到底是选择使用 1m 1 m 还是 1m−1 1 m − 1 其实区别很小,只要你有一个还算大的训练集,在机器学习领域大部分人更习惯使用这个版本的公式。这两个版本的公式在理论特性和数学特性上稍有不同,但是在实际使用中,他们的区别甚小,几乎可以忽略不计。
在异常检测中,利用如下策略判断异常
正态分布的一些性质:
- 如果 X∼N(μ,σ2) X ∼ N ( μ , σ 2 ) ,且 a a 与 b b 是实数,那么 aX+b∼N(aμ+b,(aσ)2) a X + b ∼ N ( a μ + b , ( a σ ) 2 ) (参见期望值和方差).
- 如果 X∼N(μX,σ2X) X ∼ N ( μ X , σ X 2 ) 与 Y∼N(μY,σ2Y) Y ∼ N ( μ Y , σ Y 2 ) 是统计独立的常态随机变量,那么:
它们的和也满足正态分布 U=X+Y∼N(μX+μY,σ2X+σ2Y) U = X + Y ∼ N ( μ X + μ Y , σ X 2 + σ Y 2 ) (proof).
它们的差也满足正态分布 V=X−Y∼N(μX−μY,σ2X+σ2Y). V = X − Y ∼ N ( μ X − μ Y , σ X 2 + σ Y 2 ) .
U与V两者是相互独立的。(要求X与Y的方差相等) - 如果 X∼N(0,σ2X) X ∼ N ( 0 , σ X 2 ) 和 Y∼N(0,σ2Y) Y ∼ N ( 0 , σ Y 2 ) 是独立常态随机变量,那么:
它们的积 XY X Y 服从概率密度函数为 p p 的分布
p(z)=1πσXσYK0(|z|σXσY) p ( z ) = 1 π σ X σ Y K 0 ( | z | σ X σ Y ) ,其中 K0 K 0 是修正贝塞尔函数(modified Bessel function)
它们的比符合柯西分布,满足 X/Y∼Cauchy(0,σX/σY). X / Y ∼ C a u c h y ( 0 , σ X / σ Y ) . - 如果 X1,⋯,Xn X 1 , ⋯ , X n 为独立标准常态随机变量,那么 X21+⋯+X2n X 1 2 + ⋯ + X n 2 服从自由度为n的卡方分布。
中心极限定理
正态分布有一个非常重要的性质:在特定条件下,大量统计独立的随机变量的平均值的分布趋于正态分布,这就是中心极限定理。中心极限定理的重要意义在于,根据这一定理的结论,其他概率分布可以用正态分布作为近似。中心极限定理阐明了随着有限方差的随机变量数量增长,它们的和的分布趋向正态分布。- 1、参数为n和p的二项分布,在n相当大而且p接近0.5时近似于正态分布。
(有的参考书建议仅在 np n p 与 n(1−p) n ( 1 − p ) 至少为5时才能使用这一近似)。近似正态分布平均数为 μ=np μ = n p 且方差为 σ2=np(1−p). σ 2 = n p ( 1 − p ) . (见下图)正态分布的概率密度函数,参数为μ = 12,σ = 3,趋近于n = 48、p = 1/4的二项分布的概率质量函数。
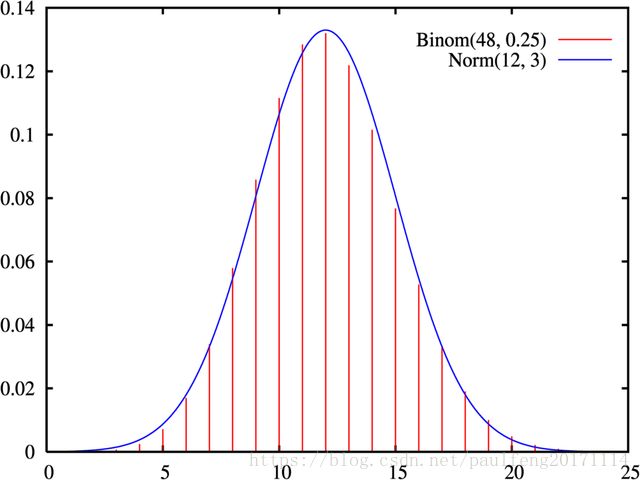
- 2、一泊松分布带有参数 λ λ 当取样样本数很大时将近似正态分布 λ λ .
近似正态分布平均数为 μ=λ μ = λ 且方差为 σ2=λ. σ 2 = λ . ,这些近似值是否完全充分正确取决于使用者的使用需求。
- 1、参数为n和p的二项分布,在n相当大而且p接近0.5时近似于正态分布。
相关的一些分布介绍
- 1、 R∼Rayleigh(σ) R ∼ R a y l e i g h ( σ ) 是瑞利分布,如果 R=X2+Y2−−−−−−−√, R = X 2 + Y 2 , 这里 X∼N(0,σ2) X ∼ N ( 0 , σ 2 ) 和 Y∼N(0,σ2) Y ∼ N ( 0 , σ 2 ) 是两个独立正态分布。
- 2、 Y∼χ2ν Y ∼ χ ν 2 是卡方分布,具有 ν ν 自由度,如果 Y=∑νk=1X2k Y = ∑ k = 1 ν X k 2 这里 Xk∼N(0,1) X k ∼ N ( 0 , 1 ) 其中 k=1,…,ν k = 1 , … , ν 是独立的。
- 3、 Y∼Cauchy(μ=0,θ=1) Y ∼ C a u c h y ( μ = 0 , θ = 1 ) 是柯西分布,如果 Y=X1/X2 Y = X 1 / X 2 ,其中 X1∼N(0,1) X 1 ∼ N ( 0 , 1 ) 并且 X2∼N(0,1) X 2 ∼ N ( 0 , 1 ) 是两个独立的正态分布。
- 3、 Y∼Log-N(μ,σ2) Y ∼ Log-N ( μ , σ 2 ) 是对数正态分布,如果 Y=eX Y = e X 并且 X∼N(μ,σ2). X ∼ N ( μ , σ 2 ) .
- 4、与Lévy skew alpha-stable分布相关(雷维偏阿尔法-稳定分布):如果 X∼Levy-SαS(2,β,σ/2–√,μ) X ∼ Levy-S α S ( 2 , β , σ / 2 , μ ) 因而 X∼N(μ,σ2). X ∼ N ( μ , σ 2 ) .
(二)二元高斯函数(多元中的特例)
二维高斯函数形如:

下面使用matlab直观的查看高斯函数,在实际编程应用中,高斯函数中的参数有
- ksize 高斯函数的大小
- sigma 高斯函数的方差
- center 高斯函数尖峰中心点坐标
- bias 高斯函数尖峰中心点的偏移量,用于控制截断高斯函数
为了方便直观的观察高斯函数参数改变而结果也不一样,下面的代码实现了参数的自动递增,并且将所有的结果图保存为gif图像,首先贴出完整代码:
[plain] view plain copy
function mainfunc()
% 测试高斯函数,递增的方法实现高斯函数参数的改变对整个高斯函数的影响,
% 并自动保存为gif格式输出。
% created by zhao.buaa 2016.09.28
%% 保存gif动画
item = 10; % 迭代次数
dt = 1; % 步长大小
ksize =20; % 高斯大小
sigma = 2; % 方差大小
% filename = ['ksize-' num2str(ksize) '--' num2str(ksize+dt*item) '-sigma-' num2str(sigma) '.gif']; %必须预先建立gif文件
filename = ['ksize-' num2str(ksize) '-sigma-' num2str(sigma) '--' num2str(sigma+dt*item) '.gif']; %必须预先建立gif文件
% main loop
for i = 1:item
center = round(ksize/2); % 中心点
bias = ksize*10/10; % 偏移中心点量
ksigma = ksigma(ksize, sigma, center, bias); % 构建核函数
tname = ['ksize-' num2str(ksize) '-sigma-' num2str(sigma) '-center-' num2str(center)];
figure(i), mesh(ksigma), title(tname);
%设置固定的x-y-z坐标范围,便于观察,axis([xmin xmax ymin ymax zmin zmax])
axis([0 ksize 0 ksize 0 0.008]); view([0, 90]);% 改变可视角度
% ksize 递增
% ksize = ksize + 10;
% sigma 递增
sigma = sigma + dt;
% 自动保存为gif图像
frame = getframe(i);
im = frame2im(frame);
[I,map] = rgb2ind(im,256);
if i==1
imwrite(I,map,filename,'gif','Loopcount',inf, 'DelayTime',0.4);
else
imwrite(I,map,filename,'gif','WriteMode','append','DelayTime',0.4);
end
end;
close all;
%% 截断高斯核函数,截断的程度取决于参数bias
function ksigma = ksigma(ksize, sigma, center,bias)
%ksize = 80; sigma = 15;
ksigma=fspecial('gaussian',ksize, sigma); % 构建高斯函数
[m, n] =size(ksigma);
for i = 1:m
for j = 1:n
if( (ii>center+bias)||(jj>center+bias) )
ksigma(i,j) = 0;
end;
end;
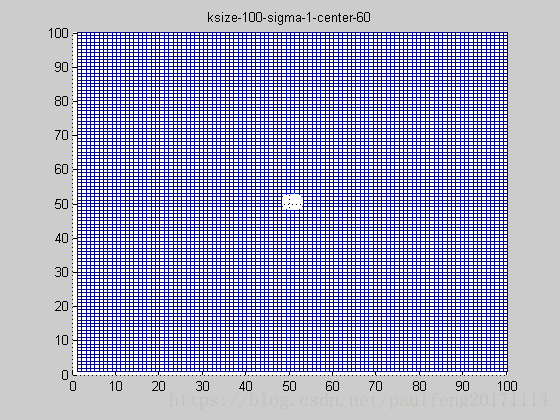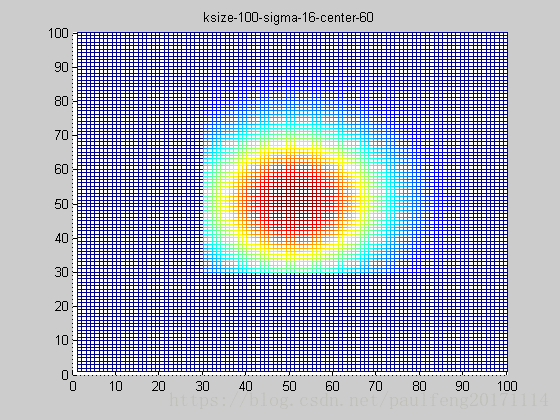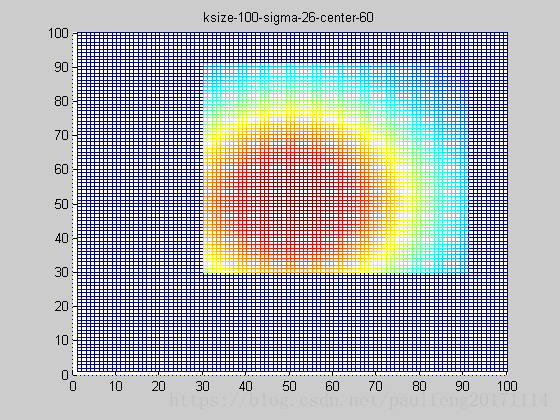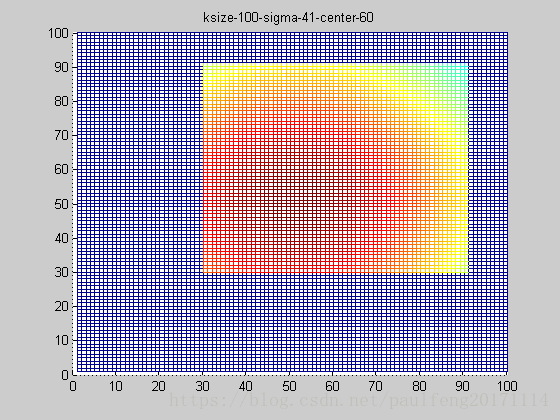
end; 固定ksize为20,sigma从1-9,固定center在高斯中间,并且bias偏移量为整个半径,即原始高斯函数。
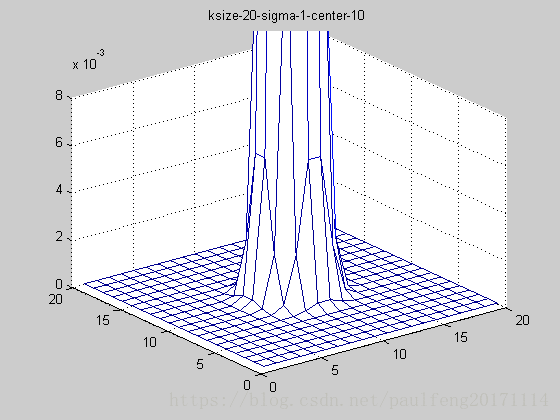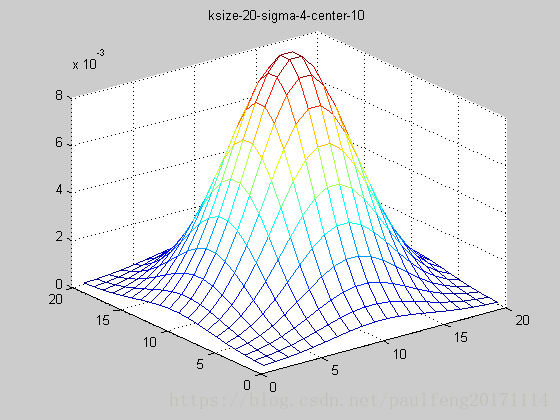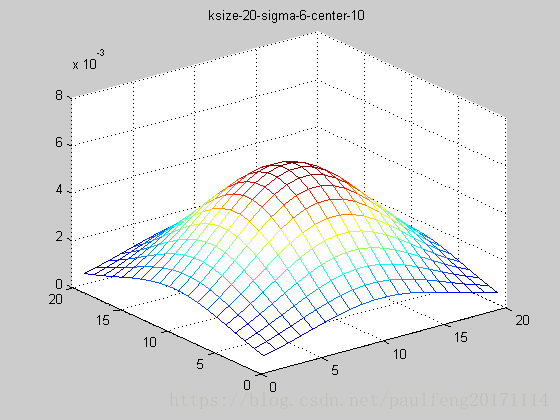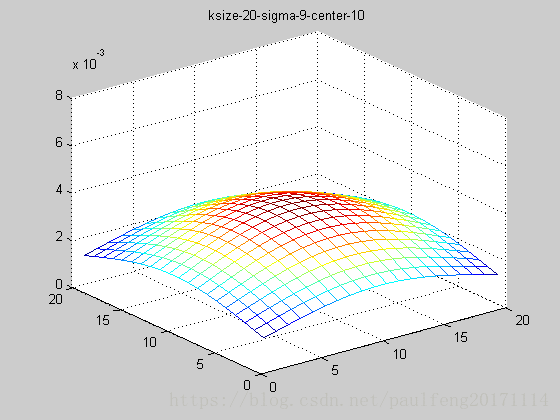
随着sigma的增大,整个高斯函数的尖峰逐渐减小,整体也变的更加平缓,则对图像的平滑效果越来越明显。
保持参数不变,对上述高斯函数进行截断,即truncated gaussian function,bias的大小为ksize*3/10,则结果如下图:
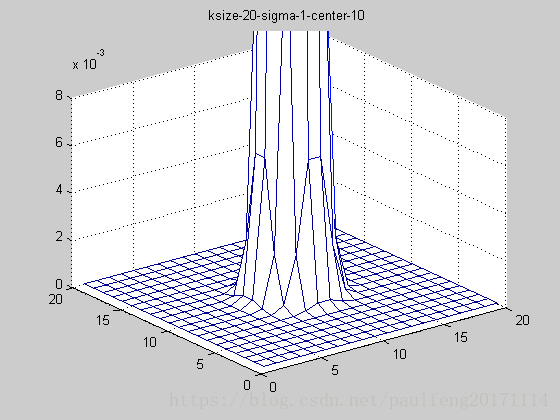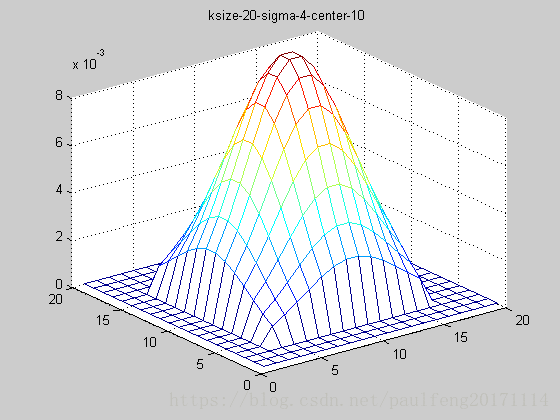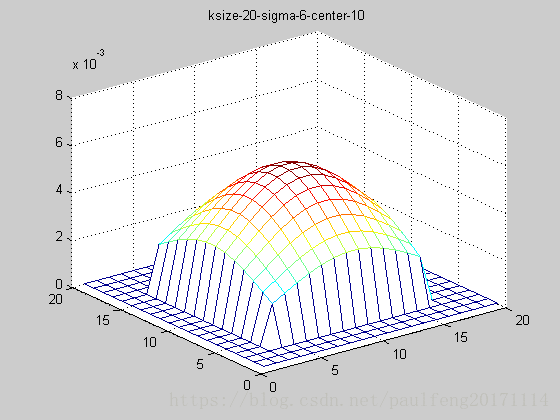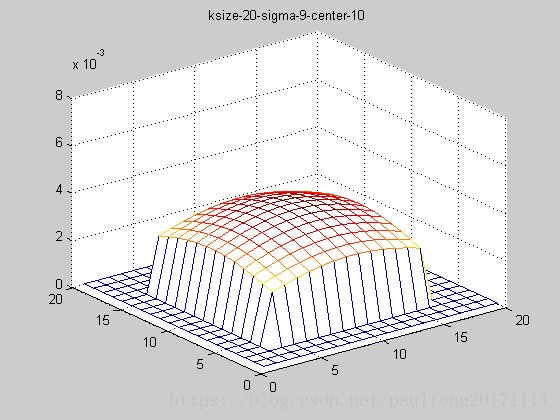
truncated gaussian function的作用主要是对超过一定区域的原始图像信息不再考虑,这就保证在更加合理的利用靠近高斯函数中心点的周围像素,同时还可以改变高斯函数的中心坐标,如下图(俯视图):
(三)多元高斯函数
多元正态分布定义
多变量正态分布亦称为多变量高斯分布。它是单维正态分布向多维的推广。它同矩阵正态分布有紧密的联系。
一般形式:
N维随机向量 X=[X1,…,XN]T X = [ X 1 , … , X N ] T 如果服从多变量正态分布,必须满足下面的三个等价条件:
1、任何线性组合 Y=a1X1+⋯+aNXN Y = a 1 X 1 + ⋯ + a N X N 服从正态分布。
2、存在随机向量 Z=[Z1,…,ZM]T Z = [ Z 1 , … , Z M ] T ( 它的每个元素服从独立标准正态分布),向量 μ=[μ1,…,μN]T μ = [ μ 1 , … , μ N ] T 及 N×M N × M 矩阵 A A 满足 X=AZ+μ. X = A Z + μ .
3、存在 μ μ 和一个对称正定阵 Σ Σ ,满足 X X 的特征函数 ϕX(u;μ,Σ)=exp(iμTu−12uTΣu) ϕ X ( u ; μ , Σ ) = exp ( i μ T u − 1 2 u T Σ u ) ,如果 Σ Σ 是非奇异的,那么该分布可以由以下的PDF来描述: fx(x1,…,xk)=1(2π)k|Σ|−−−−−−−√exp(−12(x−μ)TΣ−1(x−μ)), f x ( x 1 , … , x k ) = 1 ( 2 π ) k | Σ | exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) , ,注意这里的 |Σ| | Σ | 表示协方差矩阵的行列式。
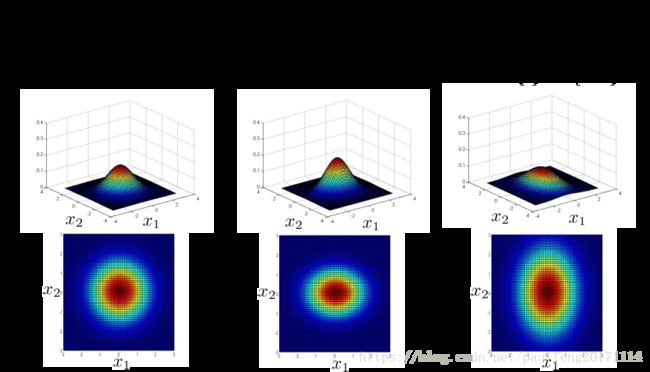
多元高斯分布参数相关性分析 (xi;μi;σi) ( x i ; μ i ; σ i )
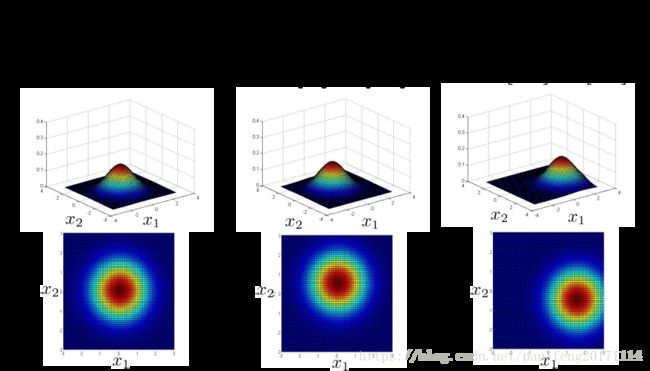
标准方差对角线 x1,x2 x 1 , x 2 同时缩小(高度增大,幅度 x1,x2 x 1 , x 2 同时缩小)或增大(高度缩小,幅度 x1,x2 x 1 , x 2 同时增大),如下图

标准方差对角线单元素 x1 x 1 缩小(高度单比例增大,幅度单方向 x1 x 1 缩小)或增大(高度单比例缩小,幅度单方向 x1 x 1 增大),如下图

标准方差对角线单元素 x2 x 2 缩小(高度单比例增大,幅度单方向 x2 x 2 缩小)或增大(高度单比例缩小,幅度单方向 x2 x 2 增大),如下图
协方差非对角线同时由0增加,见下图
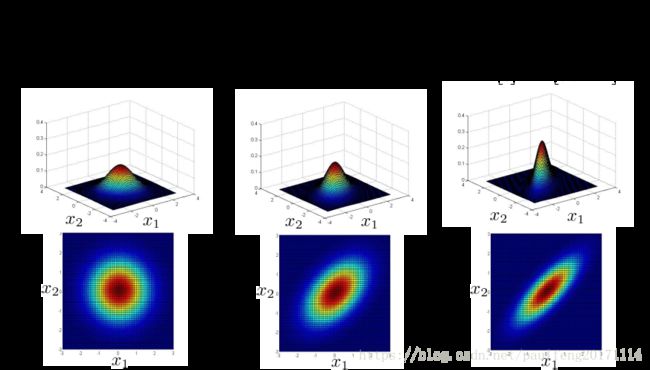
协方差非对角线同时由0负增加,见下图

均值调整,高斯分布图中心点变化,如下图
多元高斯概率模型
在一般的高斯分布模型中,我们计算 p(x) p ( x ) 的方法是: 通过分别计算每个特征对应的几率然后将其累乘起来,在多元高斯分布模型中,我们将构建特征的协方差矩阵,用所有的特征一起来计算 p(x) p ( x ) 。
我们首先计算所有特征的平均值,
∑−1 ∑ − 1 是逆矩阵。
多元高斯分布模型与原高斯分布模型的关系:
可以证明的是,原本的高斯分布模型是多元高斯分布模型的一个子集,如果协方差矩阵只在对角线的单位上有非零的值时,即为原本的高斯分布模型了。
原高斯分布模型和多元高斯分布模型的比较:
| 原高斯分布模型 | 多元高斯分布模型 |
|---|---|
| 不能捕捉特征之间的相关性 但可以通过将特征进行组合的方法来解决 | 自动捕捉特征之间的相关性 |
| 计算代价低,能适应大规模的特征 | 计算代价较高 训练集较小时也同样适用 |
| 必须要有 m>n m > n ,不然的话协方差矩阵 不可逆的,通常需要 m>10n m > 10 n 另外特征冗余也会导致协方差矩阵不可逆 |
使用多元高斯分布函数进行异常检测
: 多元高斯分布函数:
多元高斯分布函数有两个参数, μ μ 和 ∑ ∑ 。其中 μ μ 是一个n维向量。 ∑ ∑ 是 n×n n × n 的协方差矩阵。