【矩阵分解】优化方法-交替最小二乘ALS(Alternating Least Squares)
需要清楚,这里的ALS是求解的方法,类似SGD,前面的SVD、Funk-SVD等方法,是构造了不同的损失函数。那么损失函数怎么求解得到参数解?ALS可以达到这一目的。
主要思想
在实际应用中,交替最小二乘更常用一些,这也是社交巨头 Facebook 在他们的推荐系统中选择的主要矩阵分解方法。
交替最小二乘的核心是 “交替”,接下来看看 ALS 是如何 “交替”。
矩阵分解的最终任务是找到两个矩阵 P 和 Q,让它们相乘后约等于原矩阵 R:
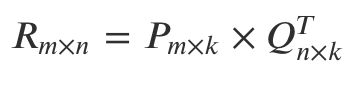
难就难在,P 和 Q 两个都是未知的,如果知道其中一个的话,就可以按照线性代数标准解法求得,比如如果知道了 Q,那么 P 就可以这样算:
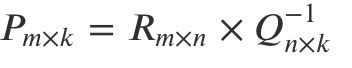
也就是 R 矩阵乘以 Q 矩阵的逆矩阵就得到了结果。
反之知道了 P 再求 Q 也一样。交替最小二乘通过迭代的方式解决了这个鸡生蛋蛋生鸡的难题4:
- 初始化随机矩阵 Q 里面的元素值;
- 把 Q 矩阵当做已知的,直接用线性代数的方法求得矩阵 P;
- 得到了矩阵 P 后,把 P 当做已知的,故技重施,回去求解矩阵 Q;
- 上面两个过程交替进行,一直到误差可以接受为止。
这便是机器学习的一大优势,先给一个假的结果,让整个模型运转起来,然后不断迭代最终得到想要的结果。
另外,WRMF 这种带权重的 ALS 优化算法叫做加权交替最小二乘:Weighted-ALS。还有 Spark 平台中集成了 ALS 算法,可以快速实现矩阵分解的优化。
代码
2.sparkML中ALS代码地址,实现的是这篇论文Collaborative Filtering for Implicit Feedback Datasets中的MF。
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.recommendation.ALS
case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long)
def parseRating(str: String): Rating = {
val fields = str.split("::")
assert(fields.size == 4)
Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)
} // 将数据的类型转换为要求的数据类型
val ratings = spark.read.textFile("data/mllib/als/sample_movielens_ratings.txt")
.map(parseRating)
.toDF() //加载数据,保存为dataframe格式,并且userid和itemid是int类型,rating是float类型,如果不是这个类型会报错。
val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2)) //将样本拆分为训练0.8,测试0.2
// Build the recommendation model using ALS on the training data
val als = new ALS() //定义一个ALS类
.setMaxIter(5) //迭代次数,用于最小二乘交替迭代的次数
.setRegParam(0.01) //惩罚系数
.setUserCol("userId") //userid
.setItemCol("movieId") //itemid
.setRatingCol("rating") //rating矩阵,这里跟你输入的字段名字要保持一致。很明显这里是显示评分得到的矩阵形式
val model = als.fit(training) //拟合模型
// Evaluate the model by computing the RMSE on the test data
// Note we set cold start strategy to 'drop' to ensure we don't get NaN evaluation metrics
model.setColdStartStrategy("drop")
val predictions = model.transform(test)
val evaluator = new RegressionEvaluator()
.setMetricName("rmse")
.setLabelCol("rating")
.setPredictionCol("prediction")
val rmse = evaluator.evaluate(predictions)
//如果你是隐式评分矩阵,那么需要设置如下参数
val als = new ALS()
.setMaxIter(5)
.setRegParam(0.01)
.setImplicitPrefs(true)//此处表明rating矩阵是隐式评分
.setUserCol("userId")
.setItemCol("movieId")
.setRatingCol("rating")
实践小技巧:
1.调参,推荐使用网格搜索进行调参。
包括三步:
println("end als and begin paramGrid ----------")
val paramGrid = new ParamGridBuilder()
.addGrid(als.maxIter,Array(50,100,150))
.addGrid(als.rank,Array(32,64,128,256))
.build()
val evaluator = new RegressionEvaluator()
.setMetricName("rmse")
.setLabelCol("rating")
.setPredictionCol("prediction")
println("end evaluator and begin TV ")
val trainValidationSplit = new TrainValidationSplit()
.setEstimator(als)
.setEvaluator(evaluator)
.setTrainRatio(0.8)
.setEstimatorParamMaps(paramGrid)
.setSeed(567812)
println("begin tv model__________")
val tvModel: TrainValidationSplitModel = trainValidationSplit.fit(training)
第一步:确定paramGrid。这里加入对迭代次数和分裂维度进行网格搜索。其实就是贪婪搜索,遍历每一种可能。
第二步:确定评估方法evaluator。这里用rmse进行评估。
第三步:TV方法进行训练。
第四步:可能需要模型之间的转换。
2. ALS中还有一个加速分解的参数:
.setNumBlocks(200)
这个参数官网文档说这个参数可以设置为-1,加速分解,但是我将其设置为-1的时候,出bug,说是该参数设置无效。因此只能尽量的将这些参数设置的大一些,加速矩阵分解。我采用了rating矩阵中有5亿数据进行分解,分200块,速度确实提高了不少,具体没有衡量。
ALS算法参数解释:
常被应用于推荐系统。这些技术旨在补充用户-商品关联矩阵中所缺失的部分。MLlib当前支持基于模型的协同过滤,其中用户和商品通过一小组隐语义因子进行表达,并且这些因子也用于预测缺失的元素。为此,我们实现了ALS来学习这些隐性语义因子。在 MLlib 中的实现有如下的参数:
numBlocks 是用于并行化计算的分块个数 (设置为-1为自动配置)。
rank 是模型中隐语义因子的个数。就是平时的特征向量的长度。
maxIter:iterations 是迭代的次数。
lambda 是ALS的正则化参数。
implicitPrefs 决定了是用显性反馈ALS的版本还是用适用隐性反馈数据集的版本,如果是隐性反馈则需要将其参数设置为true。
alpha 是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准。
itemCol:deal的字段名字,需要跟表中的字段名字是一样的。
nonnegative:是否使用非负约束,默认不使用 false。
predictionCol:预测列的名字
ratingCol:评论字段的列名字,要跟表中的数据字段一致。
userCol:用户字段的名字,同样要保持一致。
参考:
1.https://blog.csdn.net/pearl8899/article/details/80336938