CS224n 深度自然语言处理(四) Note - Backpropagation and computation graphs
本文为笔者学习CS224N所做笔记,所包含内容不限于课程课件和讲义,还包括笔者对机器学习、神经网络的一些理解。所写内容难免有难以理解的地方,甚至可能有错误。如您在阅读中有疑惑或者建议,还望留言指正。笔者不胜感激!
在本章中,将着重讨论以下内容:
- 如何更新神经网络参数?
- 以何种形式保存更新结构?
- 搭建和训练神经网络的技巧.
梯度和导数
上一章提到,应该最小化损失函数。损失函数的参数是神经网络参数,由于梯度的方向是函数上升最快的方向,故若想最小化损失函数,应该按负梯度方向更新参数,即梯度下降。而为了求解损失函数对参数的梯度,就涉及到了微分的问题。
梯度计算
对于上一章提出的简单的神经网络分类器,有如下的形式:
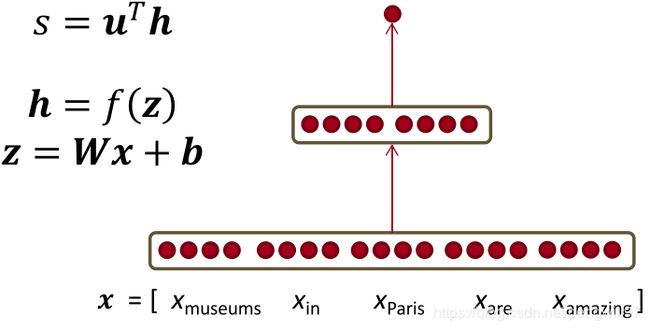
现在计算 ∂ s ∂ W \frac{\partial s}{\partial W} ∂W∂s,根据链式法则,有
∂ s ∂ W = ∂ s ∂ h ⋅ ∂ h ∂ z ⋅ ∂ z ∂ W \frac{\partial s}{\partial W}=\frac{\partial s}{\partial h}·\frac{\partial h}{\partial z}·\frac{\partial z}{\partial W} ∂W∂s=∂h∂s⋅∂z∂h⋅∂W∂z
此处 s , W , h , z s,W,h,z s,W,h,z均为矩阵或者向量的形式,涉及到矩阵求导,较为繁琐。为了简单清楚的阐述其原理,我们求对于 W W W中某个特定元素的求导规则,即计算 ∂ s ∂ W i j \frac{\partial s}{\partial W_{ij}} ∂Wij∂s。同时,我们神经网络用图的方式更加详细的表示出来。

再做一个简化,令 ∂ s ∂ W \frac{\partial s}{\partial W} ∂W∂s链式法则展开的前两项为 δ \delta δ,关注 ∂ z ∂ W \frac{\partial z}{\partial W} ∂W∂z,即
∂ s ∂ W = δ ∂ z ∂ W = δ ∂ ∂ W W x + b \frac{\partial s}{\partial W}=\delta\frac{\partial z}{\partial W}=\delta \frac{\partial}{\partial W}Wx+b ∂W∂s=δ∂W∂z=δ∂W∂Wx+b
我们考虑 z i z_i zi对于一个矩阵权重 W i j W_{ij} Wij的微分,
KaTeX parse error: No such environment: align* at position 8: \begin{̲a̲l̲i̲g̲n̲*̲}̲ \frac{z_i}{\pa…
故对于一个权重值 W i j W_{ij} Wij, ∂ s ∂ W i j = δ i x j \frac{\partial s}{\partial W_{ij}}=\delta_{i}x_j ∂Wij∂s=δixj,其中 x j x_j xj与输入有关,叫做局部梯度信号,而 δ i \delta_i δi和误差有关,叫做误差信号。
对于 ∂ s ∂ W = δ T x T \frac{\partial s}{\partial W}=\delta^T x^T ∂W∂s=δTxT,最终的维度为 n × m n\times m n×m,其中 n n n为隐层神经元数量,上图中为2, m m m为输入层神经元数量,上图为 3 3 3(也可以直接根据矩阵求导求得)。
滑动窗口输入的梯度计算
上一小节图片中的模型考虑到的是输入为一个词向量的情况,而对于滑动窗口模型而言,输入为多个词向量。可以将每个词的词向量分开考虑,这样做的原因是考虑到可以对已经训练好的词向量做fine-tune(微调),则有
δ w i n d o w = [ ∇ x m u s e u m s ∇ x i n ∇ x P a r i s ∇ x a r e ∇ x a m a z i n g ] \delta_{window}= \begin{aligned} \left[ \begin{matrix} \nabla x_{museums} \\ \nabla x_{in} \\ \nabla x_{Paris} \\ \nabla x_{are} \\ \nabla x_{amazing} \end{matrix} \right] \end{aligned} δwindow=⎣⎢⎢⎢⎢⎡∇xmuseums∇xin∇xParis∇xare∇xamazing⎦⎥⎥⎥⎥⎤
且 ∇ x J = W T δ = δ ⋅ x w i n d o w \nabla_{x}J =W^T\delta = \delta·x_{window} ∇xJ=WTδ=δ⋅xwindow.在fine tune过程中,对神经网络参数训练的同时,也会调整词向量。
在对词向量做fine-tune之前也要考虑一些问题,例如我们要使用单个词汇训练电影评论情感分类模型,在训练集中出现了"TV"和"telly",但是没有出现"television",在测试集中只出现了"television",却没有出现"TV"和"telly";换言之,训练集和测试集的样本分布不均衡。如果在这种情况下依旧对词向量进行fine tune,会导致词的分类错误。如下面两幅图所示。

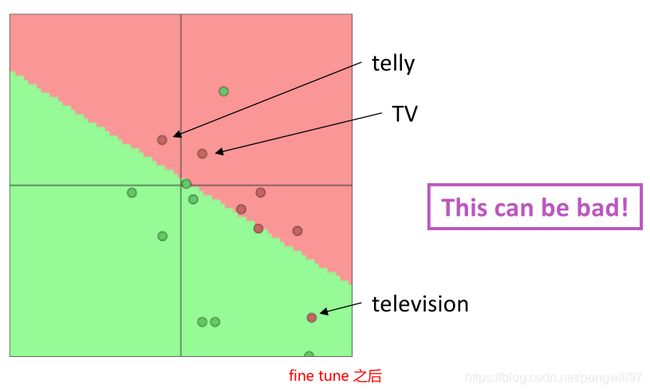
如果使用已经训练好的词向量,需要判断下游任务数据情况,来决定是否fine tune。若数据量很大,可以试着采用fine tune,如果数据集很小,则不要使用fine tune,否则容易出现上图的情况。
计算图和反向传播
在我们使用深度学习框架搭建神经网络的时候,深度学习框架在检查模型无误后(指类型匹配,维度匹配等),帮我们建立计算图,以便更新神经网络参数。每当一个batch的数据送入神经网络(一个batch的数据往往是多个矩阵或者多个张量),会先沿着计算图前向传播,目的是求出最终的结果,即模型输出。之后,再计算梯度,沿着计算图反向传播,更新参数。不同的batch按照此操作,反复执行,使得神经网络的参数能够更好的拟合数据。
下面就介绍一下,计算图是如何结合上一节提到的梯度,来更新神经网络的参数的。
计算图
我们将刚才的神经网络以计算图的形式绘制出来
s = u T h h = f ( z ) z = W x + b x ( i n p u t ) s=u^Th \\ h=f(z) \\ z=Wx+b \\ x(input) s=uThh=f(z)z=Wx+bx(input)

图中的结点表示操作,而边表示运算结果和运算结果的传递方向。从输入 x x x到最终结果 s s s的传递过程称为前向传播。在前向传播之后,我们可以得到最后的运算结果 s s s。在这之后,我们需要根据最后的前一节提到的梯度,更新神经网络中的各个参数值。
反向传播
前向传播之后,沿着计算图中边的反方向,逐次计算梯度,并传播,同时更新参数。
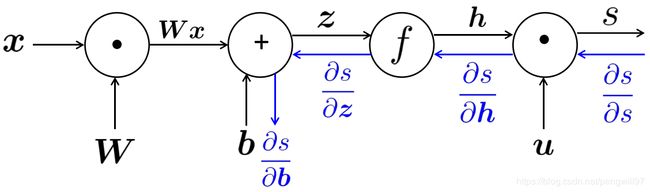
首先会先计算 ∂ s ∂ u \frac{\partial s}{\partial u} ∂u∂s,之后依次计算 ∂ s ∂ h \frac{\partial s}{\partial h} ∂h∂s, ∂ s ∂ z , ∂ s ∂ b \frac{\partial s}{\partial z}, \frac{\partial s}{\partial b} ∂z∂s,∂b∂s。值得一提的是,各个函数的偏微分已经在建立计算图的时候,由深度学习框架的自动微分机计算好了,在我们向模型feed数据之后,就可以快速得到偏微分的数值。
传播方向总是从上游(靠近预测结果)向下游(靠近输入)传递。如下图所示,表示了一个节点 f f f的计算图。
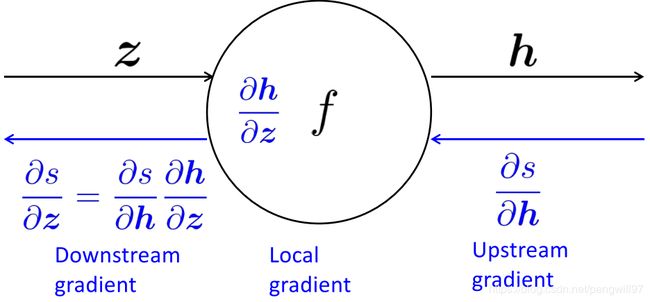
可以看到,下游偏微分 ∂ s ∂ z = ∂ s ∂ h ⋅ ∂ s ∂ z \frac{\partial s}{\partial z}=\frac{\partial s}{\partial h} · \frac{\partial s}{\partial z} ∂z∂s=∂h∂s⋅∂z∂s,这里使用了到了链式法则,其中 ∂ s ∂ h \frac{\partial s}{ \partial h} ∂h∂s是来自上游计算的梯度,而 ∂ h ∂ z \frac{\partial h}{\partial z} ∂z∂h是来自本地(本节点)的梯度。不难得出,下游梯度=上游梯度×本地梯度。这也可以说明,反向传播应该从模型输出结果一端计算到模型输入一端。(此处的上游和下游与NLP预训练任务的上游和下游不同)
如果一个计算图中的节点的输入有多个,只需要对不同的输入分别计算,与单个并无差异(如下图),

这里有一个具体的例子。
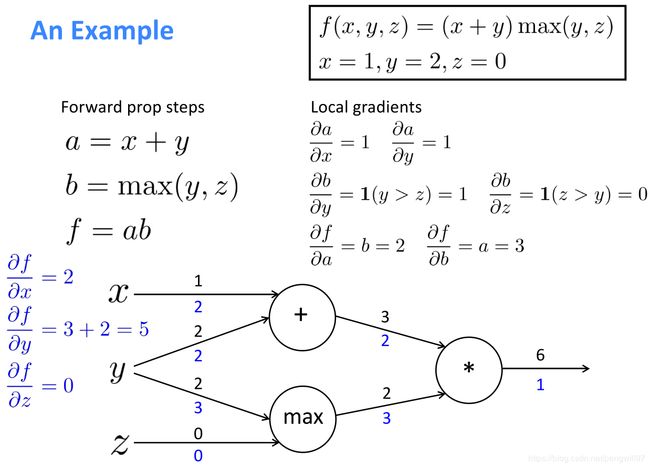
需要注意的是,要对max函数进行分类讨论,来确定其偏导数。而输入节点y有两条边,反向传播需要求和。
通常来说,一个计算图是一个有向无环图,在前向传播时按照拓扑序处理每个节点(拓扑序可以参见算法拓扑排序),而在反向传播时按照逆拓扑序处理节点。其时间复杂度是相同的。现在有了深度学习框架的加持,不需要手动计算偏微分,不需要手动求导,而在神经网络的早期,还需要使用 f ′ ( x ) = f ( x + h ) − f ( x − h ) 2 h f'(x)=\frac{f(x+h)-f(x-h)}{2h} f′(x)=2hf(x+h)−f(x−h)这样的方法来计算导数( x = 1 e − 4 x=1e-4 x=1e−4)。由于需要对每个参数使用式子计算,故计算时间很长,速度很慢。现在多为向量化和矩阵化的参数计算,可以大大提高运行效率和计算速度。
技巧
正则化
由于深度神经网络很强大,会导致模型对于训练集拟合的太好,对于新样本的泛化能力下降,出现过拟合的情况。此时,可以选择在损失函数后加上正则化项,来避免这种情况。

(紫色框中为正则化项)
问题来了,为什么正则化可以减轻过拟合呢?我分享两种浅显的理解方式,也欢迎各位分享自己见解(知乎问答:机器学习中使用正则化来防止过拟合是什么原理?)。
- 以曲线拟合任务为例,过拟合可以看作是模型学习出的曲线太好了,尽管经过了每一个点,但是不平滑,很扭曲。神经网络的强大之处在于其的参数空间很大,在损失函数中加入正则项,限制了其参数空间,学得的曲线不能像原来那样“随意伸展”,降低了过拟合的风险。
- 还以曲线拟合为例,过拟合曲线在样本点的导数都很大(因为很扭曲),有时导数大的原因是系数很大,添加正则化项之后,限制了系数,曲线也不能像原来那样扭曲了,降低过拟合的风险。
向量化和矩阵化
在实现神经网络的时,尽量使用向量和矩阵运算,避免使用循环。一是因为深度学习框架对向量和矩阵运算有优化,二是因为在训练时使用的硬件(GPU和TPU)从结构上可以快速处理矩阵运算。
参数初始化
一般可以选择随机初始化为小数,正态分布初始化或者Xavier初始化。
优化器
可以选择SGD(随机梯度下降),现在可以一般都采用Adam优化器,经常广泛用于各个模型优化(Adam优化器介绍)。
学习速率
如果使用的是SGD(随机梯度下降),一般需要逐渐降低学习速率,使模型较好的收敛,如 l r = l r 0 e − k t lr=lr_0e^{-kt} lr=lr0e−kt,其中 r 0 r_0 r0为初始的学习速率,, k k k为一个设定的常数, t t t为epoch(epoch指的是训练数据训练多少遍,如50个epoch就表示将训练集反复送如模型50遍,这样的做的目的是确保模型拟合数据并且收敛)。
如果使用的是Adam等高级优化器,则不需要手动调整,只需要设定一个初始学习速率,优化器会根据计算的二阶矩自动调整学习速率。
对于学习速率初值的选择,没有固定答案,需要根据模型和经验选择。当初始学习速率过大的时候,会出现梯度爆炸现象(即训练过程中提示有值变为NaN或者Inf)。当初始学习速率过小,会导致学习速度缓慢,模型效果提升缓慢等结果。可以先尝试一个值,再根据结果做调整。