杨明翰的分布式日志框架ELK入门helloworld
文章目录
- 前言
- 什么是ELK?
- 准备开始
- 日志格式统一
- 使用docker
- 启动ElasticSearch
- 启动LogStash
- 创建LogStash配置文件
- 配置input
- 配置filter
- 配置output
- 启动LogStash容器
- 启动FileBeat
- 创建FileBeat配置文件
- 启动FileBeat容器
- 启动Kibana
- 访问Kibana
- 总结
前言
对于日志的收集、存储、分析、监控、报警是一项非常非常重要的基础工作。
日志可以帮助我们:
- 检查系统是否健康;
- 回溯用户行为,跟踪程序运行轨迹;
- 业务层面的大数据分析,一切用数据说话,反哺给产品经理;
- 帮助分析与调试程序bug;
- 遇到错误时第一时间报警,重大事故前的预警,让运维和开发不再被动;
没有日志的帮助,我们的系统可以说是寸步难行,如同瞎子一般,时不时的崩溃也在情理之中。
当然,日志的内容也是需要拿捏的,多打有意义的日志,少打无意义的日志,
具体情况具体分析,要结合业务场景。
当今哪怕是没有玩上服务化、微服务架构的公司也会部署多个节点做集群来保证系统的高可用,
提升整体吞吐量。
那么在面对这种分布式的应用场景下(你的程序被同时部署在多个节点上),你的日志也是分布式的。
在原始人时代,我们会使用类似于log4j、logback(springboot2.0默认日志框架)等日志框架
来打log,我们的程序通过配置文件往本地磁盘中的某一个目录下输出log,并形成xxx.log文件。
那么痛点来了,如果你的程序部署到了10个节点上,你要去查看这些日志该怎么办?
- 远程进入这10个节点的linux系统,然后用tail命令?
- 如果上游的路由规则是随机飘到任意一个下游节点,你怎么跟?
- 业务量很大,日志嗖一下的刷没了,根本抓不到。
- 业务量很大,日志文件体积特别大,几个G,无论是打开和下载都很慢。
综上所述,在分布式场景下,我们需要一个地方,来集中管理所有节点的日志信息,
这个地方允许我们按不同的维度查询,报警,监控,于是,引出了今天的主题->ELK。
跟我一步一步走,我们来快速落地一个分布式日志集中管理解决方案。
不得不说,ELK里还是有一些小坑的,希望本篇文章可以让新人少走一些弯路。
什么是ELK?
ELK是三个软件是简称,他们分别是:
-
ElasticSearch
简称ES,用来做日志数据的存储,当然也可以存储其他数据,
ES是互联网应用全文检索的大杀器。 -
LogStash
用来做日志的收集、整理、拆分,负责将数据存储到ES中。
由于Logstash本身消耗资源较多,因此官方建议使用Filebeat来进行日志收集。 -
Kibana
用来做图形化页面,将ES中的数据用可视化的方式展现给用户,并支持多种功能,
例如:多维度查询、大盘监控、统计报表等等。 -
FileBeat
轻量级日志文件收集工具,占用资源特别少,收集到的日志数据可以输出到ES或LogStash中。FileBeat只负责文件的收集,它是Beat家族的成员之一,关于Beat家族的其他成员可以查看官网。
当然,日志这块也可以有其他多种玩法,例如我们可以将日志不打到xxx.log文件中,而是直接打到ES或LogStash里,或者中间再加一个mq来做异步,本文的内容是基于xxx.log的玩法。
它们四个好基友的关系是这样的(图片来源自网络):



准备开始
ELK的基础概念介绍完之后,我们要开始动手来做一个能run的demo,先来说一下我们的愿景:
- 程序通过日志框架将日志输出到xxx.log中;
- FileBeat动态收集xxx.log的内容,将数据发送给Logstash;
- LogStash接收到日志数据后,进行过滤、拆分,将整理好的数据发送给ES,有邮件报警机制;
- 待ES接收到数据后,我们通过Kibana来进行查看分析ES中的数据;
日志格式统一
在开始之前,我们需要确保xxx.log以正确的格式来进行输出,以logback为例,我们需要在logback.xml中配置日志格式:
<pattern>%p|%d|%t|%logger|%m%npattern>
这种格式会把日志打出这种效果:
INFO|2019-03-20 22:28:06,913|restartedMain|com.xxx.xxx.XXXApplication|我是一个日志
格式解释如下,我用竖线来分割是为了后面的日志拆分方便:
级别|时间日期|线程名|类名|日志内容
我们假设log文件都会打到这个目录:
/Users/alexyang/logs
该目录下有若干个log文件,log文件的内容类似于这种:
2019-03-21 09:20:01,104|INFO|restartedMain|com.xxx.xxx.XXXApplication|xx1
2019-03-21 09:20:01,104|INFO|restartedMain|com.xxx.xxx.XXXApplication|xx2
2019-03-21 09:20:01,104|ERROR|restartedMain|com.xxx.xxx.XXXApplication|xx3
2019-03-21 09:20:01,104|ERROR|restartedMain|com.xxx.xxx.XXXApplication|xx4
使用docker
本文的demo会全部使用docker,什么?你说你还不知道什么是docker?
或者只听过是一个挺高大上的东西但从来没有用过?
那我建议从现在开始开始尝试把docker用起来,至少在自己的电脑中用起来,
因为docker是目前互联网项目中非常流行的一个容器化大杀器,玩微服务、弹性收缩的中流砥柱。
所以,docker,你值得拥有。
其实docker并没有你想象中的那么难,
入门阶段你只要理解几个核心概念即可:镜像、容器、宿主机,细节不再展开,可以自行搜索。
我们需要从官网上把docker下载下来,并安装启动,
注意,我们必须要把docker的总内存设置成4G以上,这个很重要,默认是2G内存的话会经常让ES因为内存不足而自动关掉docker容器。
然后我们需要去下载ELK的docker镜像:
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.6.2
docker pull docker.elastic.co/logstash/logstash:6.6.2
docker pull docker.elastic.co/kibana/kibana:6.6.2
docker pull docker.elastic.co/beats/filebeat:6.6.2
网上有人说,在elasticsearch的docker版本文档中,
官方提到了vm.max_map_count的值在生产环境最少要设置成262144。
需要在/etc/sysctl.conf文件中添加:
grep vm.max_map_count /etc/sysctl.conf # 查找当前的值。
vm.max_map_count=262144 # 修改或者新增。
(本文的demo使用mac系统+docker+ELK6.6.2可以跑通)
启动ElasticSearch
ES的启动是最简单的,我们通过docker命令,可以把镜像文件转化成docker容器,
我们开放了9200、9300端口,并做了宿主机到容器之间的端口映射。
docker run -it --name elasticsearch -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:6.6.2
在以后的生产环境中,需要将ES做多节点集群,以保证高可用,本例为单节点。
ES容器启动后,访问localhost:9200会出现类似于下面的内容,则表示启动成功,
可能会存在一些延迟,稍等一下。
{
"name" : "lJMIUaX",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "_GLsTHpqSPyWMmmeth_5LA",
"version" : {
"number" : "6.6.2",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "3bd3e59",
"build_date" : "2019-03-06T15:16:26.864148Z",
"build_snapshot" : false,
"lucene_version" : "7.6.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
启动LogStash
LogStash的启动是这几个组件中最难的一个,
因为我们需要通过LogStash来做日志的解析、过滤、邮件报警、输出等操作。
创建LogStash配置文件
在启动之前,我们需要创建一个LogStash的配置文件。
Logstash的配置文件有三大块:input,filter,output。这三块来和起来可以组成一个管道,
表示【输入】->【过滤】->【输出】。
还记得我们要用LogStash干嘛吗?
从FileBeat输入->过滤、拆分、报警->输出到ES。
我们把配置文件创建到/Users/alexyang/logstash/logstash.conf
这个路径会在启动LogStash容器时当做参数。
下面是配置文件的内容,感觉复杂的话不要慌,下面会有讲解:
input {
beats {
type => "demo_log"
port => "5044"
}
}
filter{
mutate{
split=>["message","|"]
add_field => {
"log_date" => "%{[message][0]}"
}
add_field => {
"log_level" => "%{[message][1]}"
}
add_field => {
"log_thread" => "%{[message][2]}"
}
add_field => {
"log_class" => "%{[message][3]}"
}
add_field => {
"log_content" => "%{[message][4]}"
}
remove_field => ["message"]
}
}
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "%{type}-%{+YYYY.MM.dd}"
}
if [log_level] == "ERROR" and [type] == "demo_log" {
email {
port => 25
address => "smtp.xxx.cn"
via => "smtp"
authentication => "login"
use_tls => true
username => "[email protected]"
password => "1qaz!QAZ"
from => "[email protected]"
to => "[email protected],[email protected]"
subject => "mail error warning"
body => "%{log_date}-%{log_content}"
}
}
}
LogStash里的配置文件可以写很多种表达式玩出花来,
细节可以访问这篇文章:
https://windcoder.com/logstash6peizhiyufazhongdetiaojianpanduan
配置input
我们把这个配置文件拆成三份来看,先看第一份input块,这里非常简单,表示输入源是从哪里来,
我们这里是通过FileBeat的5044端口,我设置了一个type变量,在下面可以做判断做使用,
input块、filter块、output块都可以写多个。
配置filter
再来看filter块,我在这里做了一个日志内容的拆分,用竖线做分割,
将分割出来的信息分门别类的放到每个变量中,为了是在Kibana上以不同的维度去操作日志。
当然,在filter块中我们也可以使用ruby和grok正则表达式来实现无限可能,
这里可以加入更多更复杂的过滤逻辑,让你的日志系统更加强大,细节不展开,请自行搜索。
配置output
最后来看output块,我这里往2个地方输出,一个是stdout控制台(为了快速定位问题),
一个是elasticsearch,输出到ES时需要定一个索引index的名字,
在Kibana中创建索引模式时需要使用。
我还加了一个判断,如果搜集到的日志的级别是ERROR,那么就要走邮件报警流程。
关于邮件报警,本例中是使用了LogStash自带的email组件完成,
当然,你可也可以选择其他的玩法,
例如:watcher插件(收费,免费试用30天,可以在Kibana中无脑配置)、sentinl啊等等。
Kibana的email组件配置上是有个坑的,就是对于不同的发件邮箱,配置上是有很大区别的,例如: port,可能是25也可能是别的; authentication,可能是login也可能是plain; use_tls,可能是true也可能是false; 等等。
如果发现邮件发不出来,很有可能是邮箱配置出现了问题,
我的例子是使用了集团内部邮箱往外发邮件,
但如果你是通过QQ、163、gmail之类的邮件服务器,那配置就不一样了。
还有一种可能,就是查看logstash的目录中是否有output-email这个组件,
可以通过./logstash-plugin list命令查看当前插件列表。
报警机制这块可以玩的很灵活,通过更灵活的配置和方案,
来实现发邮件、发短信、发微信、发钉钉等,细节不再展开。
启动LogStash容器
我们开放并映射了5044端口,并将上面的配置文件传给了LogStash容器,以及使用link参数,
会在LogStash容器hosts文件中加入elasticsearch的ip,以便在容器内可以通过域名访问。
docker run --rm -it --name logstash -p 5044:5044 --link elasticsearch -d -v /Users/alexyang/logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf docker.elastic.co/logstash/logstash:6.6.2
启动FileBeat
在启动之前,我们需要创建一个FileBeat的配置文件。
但相对LogStash而言简单许多,不要害怕。
创建FileBeat配置文件
还记得我们要用FileBeat干嘛吗?
从磁盘中收集log输入->输出到LogStash。
我们把配置文件创建到/Users/alexyang/logstash/filebeat.yml
这个路径会在启动FileBeat容器时当做参数。
下面是配置文件的内容,感觉复杂的话不要慌,下面会有讲解:
filebeat.inputs:
- type : log
enabled: true
paths:
- /Users/alexyang/logs/*.log
multiline:
pattern: ^\d{4}
negate: true
match: after
input_type: log
output.logstash:
hosts: ["logstash:5044"]
#output.elasticsearch:
# hosts: ["localhost:9200"]
有一些死的配置就不提了,像paths是用来告诉FileBeat,要收集哪个目录下的log文件,
multiline是多行合并规则,output.logstash是输出到LogStash的地址,
当然我们也可以选择跳过LogStash(如果没有日志拆分过滤的需求),直接输出到ES中,
我们可以使用output.elasticsearch来搞定(当前被我注释掉了)。
启动FileBeat容器
我们将上面的配置文件和log目录传给了FileBeat容器,以及使用link参数,
会在FileBeat容器hosts文件中加入LogStash的ip,以便在容器内可以通过域名访问。
docker run --name filebeat -d --link logstash -v /Users/alexyang/logs/:/Users/alexyang/logs/ -v /Users/alexyang/logstash/filebeat.yml:/usr/share/filebeat/filebeat.yml docker.elastic.co/beats/filebeat:6.6.2
启动Kibana
与ES的启动类似,也比较简单,我们开放与映射了5601端口,并指定了ES的访问地址,
使用link参数,会在kibana容器hosts文件中加入elasticsearch的ip,以便在容器内可以通过域名访问。
docker run -d --name kibana -p 5601:5601 --link elasticsearch -e ELASTICSEARCH_URL=http://elasticsearch:9200 docker.elastic.co/kibana/kibana:6.6.2
Kibana容器启动后,访问localhost:5601会出现kibana的页面,可能会存在一些延迟,稍等一下。
这里有个小坑,访问时可能会出现类似于“kibana还没准备好”的一串英文,如果遇到了就再耐心等一下,然后访问即可,我当时以为是什么地方配置错了,各种搜解决方案,各种改配置,结果发现什么都不用改,kibana自己就会好,只是需要时间来启动和初始化一些信息而已。
到目前为止,四个容器全部启动完毕,我们可以通过docker命令来查看四个容器的启动状态:
docker ps
如果是出现类似下面的情况则代表4个容器全部启动成功:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6cdc0b088481 docker.elastic.co/beats/filebeat:6.6.2 "/usr/local/bin/dock…" 3 hours ago Up 3 hours filebeat
b97103ed65e9 docker.elastic.co/logstash/logstash:6.6.2 "/usr/local/bin/dock…" 3 hours ago Up 3 hours 0.0.0.0:5044->5044/tcp, 9600/tcp logstash
f5ee9ab37f63 docker.elastic.co/kibana/kibana:6.6.2 "/usr/local/bin/kiba…" 3 hours ago Up 3 hours 0.0.0.0:5601->5601/tcp kibana
899b536c6329 docker.elastic.co/elasticsearch/elasticsearch:6.6.2 "/usr/local/bin/dock…" 3 hours ago Up 3 hours 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch
访问Kibana
待4个容器全部配置成功并启动之后,我们通过localhost:5601来访问Kibana的首页。
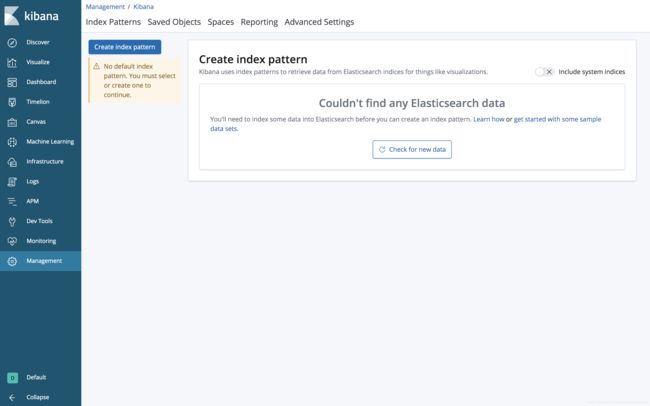
如果出现"Couldn’t find any Elasticsearch data"
这串英文,很遗憾,这表示ES上没有数据,大概率是LogStash或FileBeat的配置写错了,细节可以在评论区留言讨论。
正常的场景应该是这样:
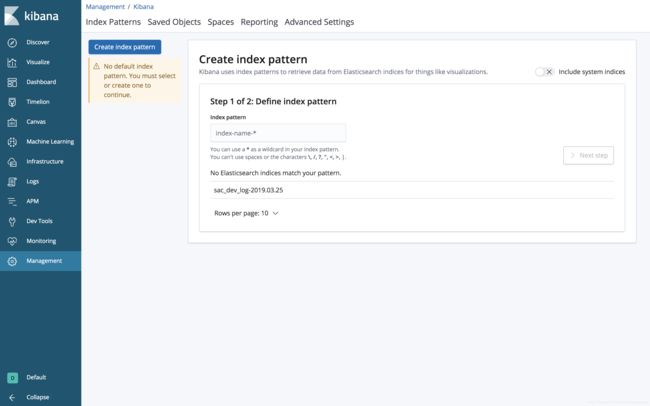
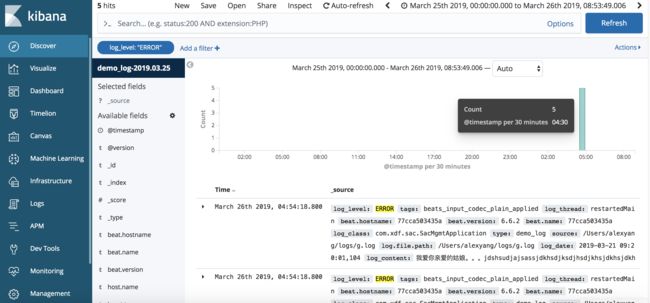
之后,我们需要创建索引模式,然后就可以开始使用Kibana强大的功能以及各种插件了,
关于Kibana的功能实在是太多,细节不再展开。
总结
ELK是目前比较流行的一种集中式分布式日志解决方案,
本例只是一个最简单的能RUN的demo,ELK还可以结合mq、redis来进行进一步的优化,
以及还能收集mysql、mq、syslog、nginx、reids等各个组件的log或其他数据,
让原来杂乱无章的让人头疼的分布式日志,变得井井有条起来。
如果不想自建ELK环境,也可以通过买云服务商的分布式日志服务来做类似的管理。
ElasticSearch+LogStash+Kibana+FileBeat快速落地分布式日志集中管理解决方案,
实现分布式日志的集中收集、过滤、存储、多维度查询、分析、统计报表、监控、报警,
也为后面的大数据分析用户行为打下了良好的基础,docker+ELK采坑实践。ELK,你值得拥有。