RabbitMq集群之高可用(二)
RabbitMq集群之高可用(二)
前面一文中搭建了集群,还有镜像模式,看似安全了,但是RabbitMq却没有负载均衡,就是说,你在使用客户端连接mq的时候,即使有node1,node2两台mq集群,但是client只会连接到一台,当node1挂了,才会连接到node2中,如果node1没有挂掉,将会一直使用node1,这样一来node2就成了摆设了,或者成了备份机了。集群我们更希望的是高可用,高性能。比如node1,node2分别能处理60万的请求,有集群的情况下按理可以处理120万的请求。client只会连接到一台mq中,它的瓶颈还是60万的数量级,node2在大量请求时并没有派上用场,只有在node1挂掉的时候才有用。所以现在来搭建一个负载均衡,让client连接一个IP,然后由负载均衡器来将请求分别发送到node1,node2中,瓶颈就变成120万了,而不是60万。
HAProxy负载均衡
HAProxy简介
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。根据官方数据,其最高极限支持10G的并发。HAProxy支持从4层至7层的网络交换,即覆盖所有的TCP协议。就是说,Haproxy 甚至还支持 Mysql 的均衡负载。
HAProxy的特点是:
- HAProxy是支持虚拟主机的,,并能支持上万级别的连接;
- 能够补充Nginx的一些缺点比如Session的保持,cookie的引导等工作;
- 支持url检测后端的服务器出问题的检测会有很好的帮助;
- 它跟LVS一样,本身仅仅就只是一款负载均衡软件;单纯从效率上来讲HAProxy更会比Nginx有更出色的负载均衡速度,在并发处理上也是优于Nginx的;
- HAProxy可以对mysql读进行负载均衡,对后端的MySQL节点进行检测和负载均衡,不过在后端的MySQL slaves数量超过10台时性能不如LVS,所以我向大家推荐LVS+Keepalived;
- 能够提供4层,7层代理。HAProxy支持两种主要的代理模式:”tcp”也即4层(大多用于邮件服务器、内部协议通信服务器等),和7层(HTTP)。在4层模式 下,HAProxy仅在客户端和服务器之间转发双向流量,7层模式下,HAProxy会分析协议,并且能通过允许、拒绝、交换、增加、修改或者删除请求 (request)或者回应(response)里指定内容来控制协议,这种操作要基于特定规则;
- HAProxy的算法现在也越来越多了
- roundrobin,表示简单的轮询,这个不多说,这个是负载均衡基本都具备的;
- static-rr,表示根据权重,建议关注;
- leastconn,表示最少连接者先处理,建议关注;
- source,表示根据请求源IP,这个跟Nginx的IP_hash机制类似,我们用其作为解决session问题的一种方法,建议关注;
- ri,表示根据请求的URI;
- rl_param,表示根据请求的URl参数’balance url_param’ requires an URL parameter name;
- hdr(name),表示根据HTTP请求头来锁定每一次HTTP请求;
- rdp-cookie(name),表示根据据cookie(name)来锁定并哈希每一次TCP请求。
HAProxy提供tcp层的负载,nginx提供的是http的负载,然后RabbitMq并没有走http层,所以我们不需要在http层做负载,直接在tcp层做负载就好了,层次越低效率越高。http是在tcp上层的。
安装
mac上面安装:brew install haproxy
Linux上面安装:yum install haproxy
使用命令安装有可能安装了老版本的,如果使用新版本则直接下载源码包安装即可。
Linux源码包安装
//直接上官网下载最新版
#解压
tar -zxvf haproxy-1.8.7.tar.gz
cd haproxy-1.8.7
#安装
make TARGET=linux2628 ARCH=x86_64 PREFIX=/usr/local/haproxy
make install PREFIX=/usr/local/haproxy
#参数说明
TARGET=linux26 #内核版本,使用uname -r查看内核,如:2.6.18-371.el5,此时该参数就为linux26;kernel 大于2.6.28的用:TARGET=linux2628
ARCH=x86_64 #系统位数
PREFIX=/usr/local/haprpxy #/usr/local/haprpxy为haprpxy安装路径
haproxy比较好安装,不需要执行.config…即可安装。
配置
haproxy从1.7之后就没有配置文件了,需要自己手动添加/usr/local/haproxy/haproxy.cfg。
###########全局配置#########
global
log 127.0.0.1 local0 #[日志输出配置,所有日志都记录在本机,通过local0输出]
log 127.0.0.1 local1 notice #定义haproxy 日志级别[error warringinfo debug]
daemon #以后台形式运行harpoxy
nbproc 1 #设置进程数量
maxconn 4096 #默认最大连接数,需考虑ulimit-n限制
#user haproxy #运行haproxy的用户
#group haproxy #运行haproxy的用户所在的组
#pidfile /var/run/haproxy.pid #haproxy 进程PID文件
#ulimit-n 819200 #ulimit 的数量限制
#chroot /usr/share/haproxy #chroot运行路径
#debug #haproxy 调试级别,建议只在开启单进程的时候调试
#quiet
########默认配置############
defaults
log global
mode http #默认的模式mode { tcp|http|health },tcp是4层,http是7层,health只会返回OK
option httplog #日志类别,采用httplog
option dontlognull #不记录健康检查日志信息
retries 2 #两次连接失败就认为是服务器不可用,也可以通过后面设置
#option forwardfor #如果后端服务器需要获得客户端真实ip需要配置的参数,可以从Http Header中获得客户端ip
option httpclose #每次请求完毕后主动关闭http通道,haproxy不支持keep-alive,只能模拟这种模式的实现
#option redispatch #当serverId对应的服务器挂掉后,强制定向到其他健康的服务器,以后将不支持
option abortonclose #当服务器负载很高的时候,自动结束掉当前队列处理比较久的链接
maxconn 4096 #默认的最大连接数
timeout connect 5000ms #连接超时
timeout client 30000ms #客户端超时
timeout server 30000ms #服务器超时
#timeout check 2000 #心跳检测超时
#timeout http-keep-alive10s #默认持久连接超时时间
#timeout http-request 10s #默认http请求超时时间
#timeout queue 1m #默认队列超时时间
balance roundrobin #设置默认负载均衡方式,轮询方式
#balance source #设置默认负载均衡方式,类似于nginx的ip_hash
#balnace leastconn #设置默认负载均衡方式,最小连接数
########统计页面配置########
listen stats
bind 0.0.0.0:1080 #设置Frontend和Backend的组合体,监控组的名称,按需要自定义名称
mode http #http的7层模式
option httplog #采用http日志格式
#log 127.0.0.1 local0 err #错误日志记录
maxconn 10 #默认的最大连接数
stats refresh 30s #统计页面自动刷新时间
stats uri /stats #统计页面url
stats realm XingCloud\ Haproxy #统计页面密码框上提示文本
stats auth admin:admin #设置监控页面的用户和密码:admin,可以设置多个用户名
stats auth Frank:Frank #设置监控页面的用户和密码:Frank
stats hide-version #隐藏统计页面上HAProxy的版本信息
stats admin if TRUE #设置手工启动/禁用,后端服务器(haproxy-1.4.9以后版本)
########设置haproxy 错误页面#####
#errorfile 403 /home/haproxy/haproxy/errorfiles/403.http
#errorfile 500 /home/haproxy/haproxy/errorfiles/500.http
#errorfile 502 /home/haproxy/haproxy/errorfiles/502.http
#errorfile 503 /home/haproxy/haproxy/errorfiles/503.http
#errorfile 504 /home/haproxy/haproxy/errorfiles/504.http
########frontend前端配置##############
frontend main
bind *:80 #这里建议使用bind *:80的方式,要不然做集群高可用的时候有问题,vip切换到其他机器就不能访问了。
acl web hdr(host) -i www.abc.com #acl后面是规则名称,-i为忽略大小写,后面跟的是要访问的域名,如果访问www.abc.com这个域名,就触发web规则,。
acl img hdr(host) -i img.abc.com #如果访问img.abc.com这个域名,就触发img规则。
use_backend webserver if web #如果上面定义的web规则被触发,即访问www.abc.com,就将请求分发到webserver这个作用域。
use_backend imgserver if img #如果上面定义的img规则被触发,即访问img.abc.com,就将请求分发到imgserver这个作用域。
default_backend dynamic #不满足则响应backend的默认页面
########backend后端配置##############
backend webserver #webserver作用域
mode http
balance roundrobin #balance roundrobin 负载轮询,balance source 保存session值,支持static-rr,leastconn,first,uri等参数
option httpchk /index.html HTTP/1.0 #健康检查, 检测文件,如果分发到后台index.html访问不到就不再分发给它
server web1 10.16.0.9:8085 cookie 1 weight 5 check inter 2000 rise 2 fall 3
server web2 10.16.0.10:8085 cookie 2 weight 3 check inter 2000 rise 2 fall 3
#cookie 1表示serverid为1,check inter 1500 是检测心跳频率
#rise 2是2次正确认为服务器可用,fall 3是3次失败认为服务器不可用,weight代表权重
backend imgserver
mode http
option httpchk /index.php
balance roundrobin
server img01 192.168.137.101:80 check inter 2000 fall 3
server img02 192.168.137.102:80 check inter 2000 fall 3
backend dynamic
balance roundrobin
server test1 192.168.1.23:80 check maxconn 2000
server test2 192.168.1.24:80 check maxconn 2000
listen tcptest
bind 0.0.0.0:5222
mode tcp
option tcplog #采用tcp日志格式
balance source
#log 127.0.0.1 local0 debug
server s1 192.168.100.204:7222 weight 1
server s2 192.168.100.208:7222 weight 1原文地址https://www.cnblogs.com/MacoLee/p/5853413.html
下面是我自己配置的
###########全局配置#########
global
log 127.0.0.1 local0
log 127.0.0.1 local1 notice
maxconn 1000 # 最大连接数,默认1000
#user haproxy # 默认用户
#group haproxy # 默认用户组
daemon # 创建1个进程进入deamon模式运行。此参数要求将运行模式设置为"daemon
nbproc 1 # 设置进程数量
###########默认配置#########
defaults
log global
mode http # 默认的模式mode { tcp|http|health },tcp是4层,http是7层,health只会返回OK
option dontlognull # 启用该项,日志中将不会记录空连接。所谓空连接就是在上游的负载均衡器
# 或者监控系统为了探测该 服务是否存活可用时,需要定期的连接或者获取某
# 一固定的组件或页面,或者探测扫描端口是否在监听或开放等动作被称为空连接;
# 官方文档中标注,如果该服务上游没有其他的负载均衡器的话,建议不要使用
# 该参数,因为互联网上的恶意扫描或其他动作就不会被记录下来
timeout connect 5000 # 连接超时时间
timeout client 50000 # 客户端连接超时时间
timeout server 50000 # 服务器端连接超时时间
option httpclose # 每次请求完毕后主动关闭http通道
option httplog # 日志类别http日志格式
#option forwardfor # 如果后端服务器需要获得客户端真实ip需要配置的参数,可以从Http Header中获得客户端ip
option redispatch # serverId对应的服务器挂掉后,强制定向到其他健康的服务器
timeout connect 10000 # default 10 second timeout if a backend is not found
maxconn 60000 # 最大连接数
retries 3 # 3次连接失败就认为服务不可用,也可以通过后面设置
####################################################################
listen http_front
bind 0.0.0.0:1080 #监听端口
stats refresh 30s #统计页面自动刷新时间
stats uri /haproxy?stats #统计页面url
stats realm Haproxy Manager #统计页面密码框上提示文本
stats auth admin:admin #统计页面用户名和密码设置
#stats hide-version #隐藏统计页面上HAProxy的版本信息
stats admin if TRUE #启用admin
##监控地址为http://ip:1080/haproxy?stats 30s自动刷新页面
####################################################################
listen rabbitmq_cluster
bind 0.0.0.0:5671
option tcplog
mode tcp
timeout client 3h
timeout server 3h
option clitcpka
balance roundrobin #负载均衡算法(#banlance roundrobin 轮询)
#balance url_param userid
#balance url_param session_id check_post 64
#balance hdr(User-Agent)
#balance hdr(host)
#balance hdr(Host) use_domain_only
#balance rdp-cookie
#balance leastconn
#balance source //ip
server node1 127.0.0.1:5672 check inter 5s rise 2 fall 3
server node2 127.0.0.1:5673 check inter 5s rise 2 fall 3 启动
启动:/usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/haproxy.cfg
启动后,可以访问监控页面,http://ip:1080/haproxy?stats,端口和后面的/haproxy?stats是在配置文件里面配置的。
在Java代码中,添加mq的地址就变成了ip 5671一个地址了,而不用填写2个地址哦。
不完美的负载
有了负载,有了集群,难道就完美了吗?好像又掉入单机的坑里面了,因为负载是单台服务器,如果当前HAProxy服务器挂了,那不是整个mr都用不了了吗?又掉入了单机的陷阱里面去了。难道要搭建两台负载均衡服务器?还好有keepalived,下面来看看keepalived怎么操作的。
Keepalived虚拟ip(转载)
Keepalived是一个基于VRRP协议来实现的服务高可用方案,可以利用其来避免IP单点故障,类似的工具还有heartbeat、corosync、pacemaker。
但是它一般不会单独出现,而是与其它负载均衡技术(如lvs、haproxy、nginx)一起工作来达到集群的高可用。
Keepalived的作用是检测服务器的状态,如果有一台web服务器死机,或工作出现故障,Keepalived将检测到,并将有故障的服务器从系统中剔除,同时使用其他服务器代替该服务器的工作;当服务器工作正常后Keepalived自动将服务器加入到服务器群中,这些工作全部自动完成,不需要人工干涉,需要人工做的只是修复故障的服务器。
http://www.cnblogs.com/MacoLee/p/5853356.html
https://blog.csdn.net/u013256816/article/details/77171017
keepalived可以理解
由于本地是mac,没有安装成功,所以就没写笔记了。
keepalived是通过虚拟IP来实现的。前面haproxy在一台服务器上面ip地址为192.168.10.10,在搭建一台haproxy服务器192.168.10.11.
现在就有2台负载均衡,2台mq服务器了,但怎么才能融合到一个IP上面而不造成单机故障呢?
很简单虚拟一个IP出来(需要在同段IP的子网里面)kp虚拟出一个IP:192.168.10.100,注意这个是一个虚拟ip,没有实际对应的物理机或虚拟机哦。
要知道,虚拟IP可以对应多个物理机,192.168.10.100可以同时对应192.168.10.10,11这两台服务器哦。他们之间有一主一从的说法。
现在把10作为主,client连接的是虚拟IP地址,192.168.10.100,请求过来的时候虚拟IP只绑定在10上面,接收请求的是10,然后有10服务器做负载分发到mq的node1,或node2上面。假如现在10服务器挂了,虚拟Ip地址192.168.10.100就开始漂移,漂移到了11服务器上面。对于client端来说连接的还是192.168.10.100,因为是虚拟ip,不存在绑定在固定物理机上面,所以虚拟ip可以动态的漂移到任意一台物理机上面。现在漂移到了11服务器,11服务器接受到了请求,然后有11负载均衡到node1或node2节点上面。
完美。
LVS+Keepalived
http://www.cnblogs.com/MacoLee/p/5856858.html
盗张图用用
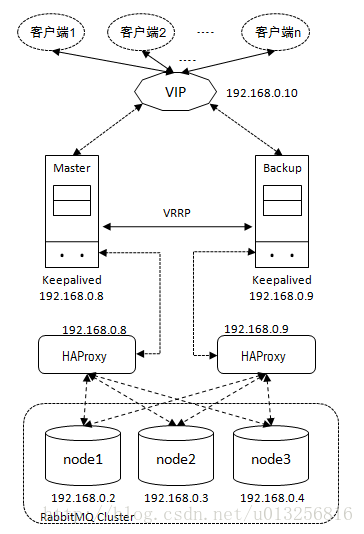
图片原文