非负矩阵分解NMF
http://blog.csdn.net/pipisorry/article/details/52098864
非负矩阵分解(NMF,Non-negative matrix factorization)
NMF的发展及原理
著名的科学杂志《Nature》于1999年刊登了两位科学家D.D.Lee和H.S.Seung对数学中非负矩阵研究的突出成果。该文提出了一种新的矩阵分解思想——非负矩阵分解(Non-negative Matrix Factorization,NMF)算法,即NMF是在矩阵中所有元素均为非负数约束条件之下的矩阵分解方法。该论文的发表迅速引起了各个领域中的科学研究人员的重视:一方面,科学研究中的很多大规模数据的分析方法需要通过矩阵形式进行有效处理,而NMF思想则为人类处理大规模数据提供了一种新的途径;另一方面,NMF分解算法相较于传统的一些算法而言,具有实现上的简便性、分解形式和分解结果上的可解释性,以及占用存储空间少等诸多优点。为高效处理这些通过矩阵存放的数据,一个关键的必要步骤便是对矩阵进行分解操作。通过矩阵分解,一方面将描述问题的矩阵的维数进行削减,另一方面也可以对大量的数据进行压缩和概括。
利用矩阵分解来解决实际问题的分析方法很多,如PCA(主成分分析)、ICA(独立成分分析)、SVD(奇异值分解)、VQ(矢量量化)等。在所有这些方法中,原始的大矩阵V被近似分解为低秩的V=WH形式。这些方法的共同特点是,因子W和H中的元素可为正或负,即使输入的初始矩阵元素是全正的,传统的秩削减算法也不能保证原始数据的非负性。在数学上,从计算的观点看,分解结果中存在负值是正确的,但负值元素在实际问题中往往是没有意义的。例如图像数据中不可能有负值的像素点;在文档统计中,负值也是无法解释的。
NMF的基本思想
NMF的基本思想可以简单描述为:对于任意给定的一个非负矩阵A,NMF算法能够寻找到一个非负矩阵U和一个非负矩阵V,使得满足 ,从而将一个非负的矩阵分解为左右两个非负矩阵的乘积。
NMF问题描述
传统的NMF问题可以描述如下
给定矩阵![]() ,寻找非负矩阵
,寻找非负矩阵![]() 和非负矩阵
和非负矩阵![]() ,使得
,使得![]() 。
。

分解前后可理解为:原始矩阵![]() 的列向量是对左矩阵
的列向量是对左矩阵![]() 中所有列向量的加权和,而权重系数就是右矩阵对应列向量的元素,故称
中所有列向量的加权和,而权重系数就是右矩阵对应列向量的元素,故称![]() 为基矩阵,
为基矩阵,![]() 为系数矩阵。一般情况下
为系数矩阵。一般情况下![]() 的选择要比
的选择要比![]() 小,即满足
小,即满足![]() ,这时用系数矩阵代替原始矩阵,就可以实现对原始矩阵进行降维,得到数据特征的降维矩阵,从而减少存储空间,减少计算机资源。
,这时用系数矩阵代替原始矩阵,就可以实现对原始矩阵进行降维,得到数据特征的降维矩阵,从而减少存储空间,减少计算机资源。
由于分解前后的矩阵中仅包含非负的元素,因此,原矩阵A中的一列向量可以解释为对左矩阵U中所有列向量(称为基向量)的加权和,而权重系数为右矩阵V中对应列向量中的元素。这种基于基向量组合的表示形式具有很直观的语义解释,它反映了人类思维中“局部构成整体”的概念。研究指出,非负矩阵分解是个NP问题,可以划为优化问题用迭代方法交替求解U和V。NMF算法提供了基于简单迭代的求解U,V的方法,求解方法具有收敛速度快、左右非负矩阵存储空间小的特点,它能将高维的数据矩阵降维处理,适合处理大规模数据。利用NMF进行文本、图像大规模数据的分析方法,较传统的处理算法速度更快、更便捷。
由于NMF不允许基图像或中间的权重矩阵中出现负值,因此只有相加组合得到的正确基图像才允许,最后通过处理后的重构图像效果是比较满意的(对矩阵非负的限制使得这种分解能够达到用部分表达整体的效果,简单地说就是,整体由部分的叠加而没有了正负抵消 )。[Learning the parts of objects by non-negative matrix factorization]
非负矩阵分解NMF的一个示例解释
在VQ分解中,每一列的 被约束为一个一元矢量。其中只有一个元素为1,其他元素为0。若的第一列中,第r1个元素为1,那么
被约束为一个一元矢量。其中只有一个元素为1,其他元素为0。若的第一列中,第r1个元素为1,那么 中第一列的脸,就完全由基图像中的第r1列数据表示。此时得到的基图像称为原型基图像,这些原型图像表示一张原型脸。
中第一列的脸,就完全由基图像中的第r1列数据表示。此时得到的基图像称为原型基图像,这些原型图像表示一张原型脸。
在PCA分解中, 的各列之间相互正交,各行之间相互正交。这个约束比VQ的松弛很多,也就是,中的元素可为正也可为负。中每一张脸的每一个像素点都是中各列对应的像素点的一个加权和。由于权重矩阵中元素符号的任意性,所以基矩阵表示出来并不像VQ中原型脸那样的直观可解释。此时将W的列数据画出来并不一定能直接看到一张“脸”。但是在统计上可以解释为最大方差方向,我们把这些“脸”称为“特征脸”。
的各列之间相互正交,各行之间相互正交。这个约束比VQ的松弛很多,也就是,中的元素可为正也可为负。中每一张脸的每一个像素点都是中各列对应的像素点的一个加权和。由于权重矩阵中元素符号的任意性,所以基矩阵表示出来并不像VQ中原型脸那样的直观可解释。此时将W的列数据画出来并不一定能直接看到一张“脸”。但是在统计上可以解释为最大方差方向,我们把这些“脸”称为“特征脸”。
在NMF中,由于加了非负约束。与VQ的单一元素不为0不同,NMF允许基图像H间的加权结合来表示脸部图像V;与PCA不同,NMF的加权系数H中的元素都为非负的。前两者得到的都是一个完整的脸部特征基图像,而NMF得到的是脸部子特征。通俗点说,VQ是用一张完整的图像直接代表源脸部图像;PCA是将几个完整人脸加减压成一张脸;而NMF是取甲的眼睛,乙的鼻子,丙的嘴巴直接拼成一张脸。这样解释虽然细节上略有不妥,但不失其概念上的意义。
通过图1中的面部特征提取例子可领略NMF处理数据的方式。最左边的大矩阵由一系列的小图组成,这些小图是分析数据库中包含的2429个脸部图像的结果,每幅图像由19×19个像素组成。传统方法中这样的小图是一幅完整的人脸图像,但是在NMF方法中,每个小图是通过一组基图像乘以一个权重矩阵而产生的面部特征图,经过这样处理的每幅小图像恰好表示了诸如“鼻子”、“嘴巴”、“眼睛”等人脸局部概念特征,这便大大压缩了存放的图像数据量。左边的大矩阵由每幅小图像的19列一起组成矩阵的一列,那样它就是19×19=361行,2429列。这个例子中,NMF方法用基图像来代表眼、眉毛、鼻子、嘴、耳朵、胡子等,它们一起组成了数据库中的脸。这样给人最先的直觉就是它很好地压缩了数据。事实上Lee和Seung在他们的论文中更深入地指出,与人类识别事物的过程相似,NMF也是一种优化的机制,近似于我们的脑分析和存储人脸数据的过程。这个例子中,原图像表示这些局部特征的加权组合,这与人类思维中“局部构成整体”的概念是相吻合的。因此,NMF算法似乎体现了一种智能行为。

图1 NMF提取面部特征的实例
上图的第一个方块为矩阵W,组成的图像。其中每一个小格为W的一列的19*19个元素重构而成的19*19的矩阵图像。第二个方块为H矩阵,其中红色表示负数,灰黑表示正数, 颜色程度表示大小。右边的图像只是V矩阵的一列的19*19个元素组成的一张原始脸。
NMF限制V,W,H都是非负的,而VQ限制H必须必须由单位向量(只有一个元素为1,其余为0)组成,PCA限制W的列是规范正交的,H的行是正交的,这导致了有图中三种不同的分解结果。
从结果可以看出:NMF分解结果与我们部分形成整体的直觉是相一致的。NMF学习出一种基于部分的表达。
皮皮blog
非负矩阵分解NMF的应用
事实上,在Lee和Seung发表他们的研究成果之前,针对非负矩阵的研究早在20世纪70年代已经有数学家做了一些相关的工作,但是没有引起过多的关注。20世纪90年代早期,科学家开始将数学上非负矩阵的研究成果用于环境处理和卫星遥控的应用,但是对于非负矩阵的应用意义和价值的理解仍只局限于少数科学家中,人们还没有广泛重视这种方法。直到1999年Lee和Seung的非负矩阵研究成果发表在《Nature》杂志之后,这一切才得以改变。尽管同年有另两位科学家也发表了与Lee和Seung相近的研究结果,但由于论文刊登在并非如《Nature》那样具有极高声誉的学术杂志上,因此其工作并没有得到如Lee和Seung同样的关注,这也从一个侧面折射了高水平学术杂志对研究工作的推动作用。
二、应用领域
NMF是一个很有效的算法,它力图在大规模的矩阵数据中发现具有解释功能的关系,相比当前文献中公布的其他方法来说,使用NMF的算法也是非常精确和快速的。NMF算法思想能为世界上权威的学术刊物所接受并非偶然,因为该理论本身蕴涵了巨大的潜能,这种潜在的力量将通过各种具体的应用来得以体现。
在众多应用中,NMF能被用于发现数据库中的图像特征,便于快速自动识别应用;能够发现文档的语义相关度,用于信息自动索引和提取;能够在DNA阵列分析中识别基因等等。NMF能用于发现数据库中图像的特征,便于快速识别应用,比如实现录入恐怖分子的照片,然后在安检口对可疑人员进行盘查。在文档方面,NMF能够发现文档的语义相关度,用于信息的自动索引和提取。在生物学中,在DNA阵列分析中识别基因等。在语音识别系统中NMF也能发挥重要作用。有人已经将NMF应用于盲信号分离BSS领域,取得一定的效果,不过其研究的BSS有非欠定的要求(即源数不大于传感器数),且混合矩阵等都是正的。
(1) 图像分析
NMF最成功的一类应用是在图像的分析和处理领域。图像本身包含大量的数据,计算机一般将图像的信息按照矩阵的形式进行存放,针对图像的识别、分析和处理也是在矩阵的基础上进行的。这些特点使得NMF方法能很好地与图像分析处理相结合。人们已经利用NMF算法,对卫星发回的图像进行处理,以自动辨别太空中的垃圾碎片;使用NMF算法对天文望远镜拍摄到的图像进行分析,有助于天文学家识别星体;美国还尝试在机场安装由NMF算法驱动的识别系统,根据事先输入计算机的恐怖分子的特征图像库来自动识别进出机场的可疑恐怖分子。
(2) 文本聚类/数据挖掘
文本在人类日常接触的信息中占有很大分量,为了更快更精确地从大量的文本数据中取得所需要的信息,针对文本信息处理的研究一直没有停止过。文本数据不光信息量大,而且一般是无结构的。此外,典型的文本数据通常以矩阵的形式被计算机处理,此时的数据矩阵具有高维稀疏的特征,因此,对大规模文本信息进行处理分析的另一个障碍便是如何削减原始数据的维数。NMF算法正是解决这方面难题的一种新手段。NMF在挖掘用户所需数据和进行文本聚类研究中都有着成功的应用例子。由于NMF算法在处理文本数据方面的高效性,著名的商业数据库软件Oracle在其第10版中专门利用NMF算法来进行文本特征的提取和分类。为什么NMF对于文本信息提取得很好呢?原因在于智能文本处理的核心问题是以一种能捕获语义或相关信息的方式来表示文本,但是传统的常用分析方法仅仅是对词进行统计,而不考虑其他的信息。而NMF不同,它往往能达到表示信息的局部之间相关关系的效果,从而获得更好的处理结果。
(3) 语音处理
语音的自动识别一直是计算机科学家努力的方向,也是未来智能应用实现的基础技术。语音同样包含大量的数据信息,识别语音的过程也是对这些信息处理的过程。NMF算法在这方面也为我们提供了一种新方法,在已有的应用中,NMF算法成功实现了有效的语音特征提取,并且由于NMF算法的快速性,对实现机器的实时语音识别有着促进意义。也有使用NMF方法进行音乐分析的应用。复调音乐的识别是个很困难的问题,三菱研究所和MIT(麻省理工学院)的科学家合作,利用NMF从演奏中的复调音乐中识别出各个调子,并将它们分别记录下来。实验结果表明,这种采用NMF算法的方法不光简单,而且无须基于知识库。
(4) 机器人控制
如何快速准确地让机器人识别周围的物体对于机器人研究具有重要的意义,因为这是机器人能迅速作出相应反应和动作的基础。机器人通过传感器获得周围环境的图像信息,这些图像信息也是以矩阵的形式存储的。已经有研究人员采用NMF算法实现了机器人对周围对象的快速识别,根据现有的研究资料显示,识别的准确率达到了80%以上。
(5) 生物医学工程和化学工程
生物医学和化学研究中,也常常需要借助计算机来分析处理试验的数据,往往一些烦杂的数据会耗费研究人员的过多精力。NMF算法也为这些数据的处理提供了一种新的高效快速的途径。科学家将NMF方法用于处理核医学中的电子发射过程的动态连续图像,有效地从这些动态图像中提取所需要的特征。NMF还可以应用到遗传学和药物发现中。因为NMF的分解不出现负值,因此采用NMF分析基因DNA的分子序列可使分析结果更加可靠。同样,用NMF来选择药物成分还可以获得最有效的且负作用最小的新药物。[非负矩阵分解在分析癌症突变异质性中的作用]
此外,NMF算法在环境数据处理、信号分析与复杂对象的识别方面都有着很好的应用。近年来采用NMF思想的应用才刚展开,相信以后会有更多的成功应用。这些成功的应用反过来也将促进NMF的进一步研究。
三、结束语
数学如同计算机的灵魂,NMF通过计算机与各个领域结合后的应用取得了令人叹服的成效。NMF的故事还在继续,NMF的应用领域还有待进一步的发掘,针对NMF的进一步研究也没有停止过,其中诸如分解的存在性、惟一性和收敛性以及收敛的速度等问题的深入探讨必将使该思想能更好地服务于人类。
[非负矩阵分解:数学的奇妙力量]
NMF的应用实例
示例1
无论是在需要将新闻分门别类的应用中还是在信息检索中判断两个网页文本内容的相似度(从而判断是否同类)的应用中,我们都需要从文档中学习到一些主要的特征词以代表这篇文档并据此聚类。
有许多应用都需要将模式(文档,图像,声音)进行压缩或者概括,或者说,我们需要从这些模式中提取出少量的重要的特征,原来的模式可以用这些特征进行还原而不出现大的误差。将矩阵分解为两个低秩矩阵相乘提供一种解决此问题的思路,两个矩阵相乘的结果是原矩阵低维的近似。
在图像领域,需要将图像压缩表达为一些特征的组合。

实战中可能多次实验结果不同,需要强调这是局部最优,结果受初始值选取的影响。
示例2
请设计合适的主成分分析模型, 并提供相应算法, 使得当输⼊为下图左⼿边信息时, 可以返回右⼿边的主成分元素。

左图是通过右图8个部分通过一定的随机稀疏组合而成的8×8=64幅飞机图,我们要做的就是给你左图,求出右图的成分。
这时使用NMF就可以轻松求解:(求解出的components向量可能是归一化的,而原图是01组成的,我们可以通过阈值来将浮点数变成01)
estimators = decomposition.NMF(n_components=n_components, init='nndsvd', )
estimator.fit(data)
components_ = estimator.components_[:n_components] # numpy.ndarray
plot_gallery(components_)
components_ = components_[sort_index]
plot_gallery('criterias', criterias, image_shape=image_shape)
components_[components_ > 0.1] = 1
components_[components_ <= 0.1] = 0
plot_gallery('%s - Train time %.1fs' % (name, train_time), components_, image_shape=image_shape)
error = spatial.distance.euclidean(criterias.reshape(-1), components_.reshape(-1))
不过如果使用下面高级主题中提到的Structured PCA,可能效果更好。
[LiuXin: 大数据优化算法]
皮皮blog
非负矩阵分解的算法和实现
NMF实现原理:NMF若干更新法则
NMF求解问题实际上是一个最优化问题,利用乘性迭代的方法求解![]() 和
和![]() ,非负矩阵分解是一个NP问题。NMF问题的目标函数有很多种,应用最广泛的就是欧几里得距离和KL散度。
,非负矩阵分解是一个NP问题。NMF问题的目标函数有很多种,应用最广泛的就是欧几里得距离和KL散度。
关于更新法则,Daniel D. Lee和H. Sebastian Seung的文章《Algorithms for Non-negative Matrix Factorization》有详细的公式推导证明。由于W与H的乘积是对V的近似估计,所以评价分解好坏的标准便是两者之间的差异。文中在不同的代价函数下提出了不同的更新法则,包括乘性更新法则与加性更新法则。文中还通过构造辅助函数对迭代算法的收敛性进行了证明。
写法1
在NMF的分解问题中,假设噪声矩阵为![]() ,那么有
,那么有
![]()
现在要找出合适的![]() 和
和![]() 使得
使得![]() 最小。
最小。
假设噪声服从不同的概率分布,通过最大似然函数会得到不同类型的目标函数。接下来会分别以噪声服从高斯分布和泊松分布来说明。
(1)噪声服从高斯分布
假设噪声服从高斯分布,那么得到最大似然函数为

取对数后,得到对数似然函数为

假设各数据点噪声的方差一样,那么接下来要使得对数似然函数取值最大,只需要下面目标函数值最小。
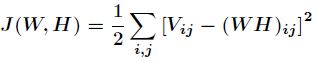
该损失函数为2范数损失函数,它是基于欧几里得距离的度量。又因为
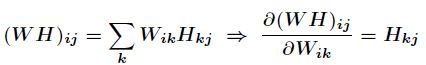
那么得到

同理有

接下来就可以使用梯度下降法进行迭代了。如下
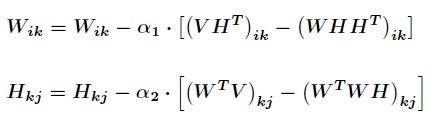
如果选取

那么最终得到迭代式为
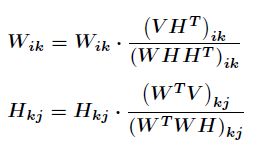
可看出这是乘性迭代规则,每一步都保证了结果为正数,一直迭代下去就会收敛,当然收敛性的证明省略。
(2)噪声服从泊松分布
若噪声为泊松噪声,那么得到损失函数为
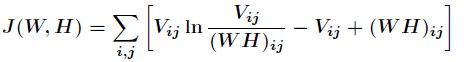
同样经过推到得到

[非负矩阵分解(NMF) ]
写法2


- Cost function 1,欧几里得距离( Euclidean distance):
![]() (1)
(1)
在此代价函数下的乘性更新法则有:
![]() 及
及 ![]() (2)
(2)
-
cost function 2,分离度(divergence):
![]() (3)
(3)
在此代价函数下的乘性更新法则为:
_{i \mu}}}{\sum_{k}W_{k \alpha}}") 以及
以及 _{i \mu}}}{\sum_{\nu }H_{\alpha \nu}}") (4)
(4)
另外有加性更新法则如下:
欧几里得距离( Euclidean distance)下的加性更新为:
![]() (5)
(5)
此时只要迭代步长 的所有元素设为足够小的正数那么欧式距离会随着迭代而减小。而当迭代步长满足:
的所有元素设为足够小的正数那么欧式距离会随着迭代而减小。而当迭代步长满足:![]() ,可以得到此时的加性更新等价于式子(2)中的乘性更新。
,可以得到此时的加性更新等价于式子(2)中的乘性更新。
分离度(divergence)下的加性更新为:
![]() (6)
(6)
同样迭代步长若为足够下的正数的话,分离度代价函数的值会随着更新而减小,而当迭代步长满足:![]() ,可同样得到此时的加性更新等价于式子(4)中的乘性更新法则。
,可同样得到此时的加性更新等价于式子(4)中的乘性更新法则。
收敛性证明
如上所述,《Algorithms for Non-negative Matrix Factorization》文中还通过构造辅助函数对迭代算法的收敛性进行了证明。小小整理如下:






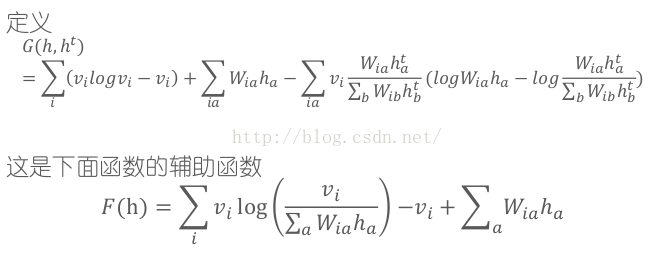


[凯:非负矩阵分解Algorithms for Non-negative Matrix Factorization]
NMF的相关算法
Local NMF(LNMF),Discriminant NMF(DNMF),non-negative sparse coding(NNSC),non-smooth NMF(nsNMF),projective NMF,temporal NMF with spatial decorrelation constraints,shifted NMF,incremental NMF,sparse higher order NMF and polynomial NMF 等等,对于NMF分解的唯一性探讨也是NMF最近比较受关注的方面。
非负矩阵分解已经有了很多算法,例如Multiplicative Update,Projected Gradient Method,Gradient Descent。交替最小二乘法比较符合上面的解释,具有更好的统计意义,而且收敛性质很好,计算速度快。已有的交替最小二乘法都使用冷冰冰的二次规划算法求解非负回归,在bignmf中使用的最小角回归的思路解非负回归,更有统计的感觉,而且速度更快。
非负矩阵分解的具体算法
输入参数:X,R,MAXITER,其中X为被分解的矩阵,R为降阶后B的秩,MAXITER为迭代次数
输出参数:B,H
1):初始化矩阵B,H为非负数,同时对B的每一列数据归一化
2):for i=1:MAXITER
a:更新H矩阵一行元素:H(i,j)=H(i,j)*(B'*X)(i,j)/(B'*B*H)(i,j)
b:更新B的一列元素:B(k,j)=B(k,j)*(X*H')(k,j)/(B*H*H')(k,j);
c: 重新对B进行列归一化
3)end
非负矩阵分解的实现代码
matlab源程序如下:
dim=size(X); %计算x的规格
X=double(X);
B=10*rand(dim(1),r); %初始化BH,为非负数
B=B./(ones(dim(1),1)*sum(B)); %归一化B的每一列
H=10*rand(r,dim(2));
maxiter=100; %最大迭代次数for iter=1:maxiter
H=H.*(B'*(X./(B*H)));
B=B.*((X./(B*H))*H');
B=B./(ones(dim(1),1)*sum(B));
end
[matlab中的NMF函数及其使用说明NMFfuction- Mathworks]
[Chih-Jen Lin关于NMF的一些源代码 NMF工具
MATLAB Scripts download nmf.m.
Python: nmf.py by Anthony Di Franco (numpy needed; see an example.py here).
Go: nmf.go by Dan Kortschak and examples.
C: NMF.c by Dong Li]
[NMF算法简介及python实现]
[NMF的R实现:bignmf:https://github.com/panlanfeng/bignmf]
[NMF的Julia实现:https://github.com/JuliaStats/NMF.jl]
皮皮blog
非负矩阵分解相关的其它高级主题
[NMF与pLSA的对比《Non-negative Matrix Factorization and Probabilistic Latent Semantic Analysis》]
[除了NMF分解以外,还有一种非负分解也用的比较多,而且很有效,叫做非负张量分解法:http://www.doc88.com/p-8942237517189.html]
[浅析基于张量分解的隐变量模型参数学习]
[Structured PCA带结构的主成分分析:主成分分析是找到给定数据的结构信息的主要手段之一,然而对于某些特殊的输入数据传统的主成分分析, 并不能真正得到问题的主成分, 这时我们在建模时就需要考虑到这些特殊的结构。
NMF分解和SSPAC分解在主成分较小的数据上,表现similarity,在主成分较多的数据上,SSPAC表现较好。(Jenatton R, Obozinski G, Bach F R. Structured Sparse Principal Component Analysis[C]//AISTATS. 2010: 366-373)
Structured Variable Selection with Sparsity-Inducing Norms
Structured Principal Component Analysis.tar.gz ]
from: http://blog.csdn.net/pipisorry/article/details/52098864
ref: [wikipedia: Non-negative matrix factorization]
[1] Daniel D lee and H.SebastianSeung(1999).”Learning the parts of objects by non-negative matrix factorization”. Nature
[2] Daniel D.Leeand H.SebastianSeung(2001). Algorithms for Non negative Matrix Factorization.Advancesin Neural Information
[3] Lee D D, Seung H S. Learning the parts of objects by non-negative matrix factorization[J]. Nature, 1999, 401(6755): 788-791.
[4] Bach F, Jenatton R, Obozinski G. Structured sparse principal component analysis[J]. J. Mach. Learn. Res, 366-373.
[5] Jenatton R, Obozinski G, Bach F R. Structured Sparse Principal Component Analysis[C]//AISTATS. 2010: 366-373.
[6] python sklearn http://scikitlearn.org/stable/modules/decomposition.html#pca