Hadoop单机版搭建
1. Jar包准备
在上一篇博客中已经准备好linux环境,看本篇博客之前请看楼主上一篇大数据简介博客,准备系统环境
下载以下jar包,传入linux服务器的opt目录下
hadoop-2.7.2-src.tar.gz ,apache-maven-3.6.0-bin.tar.gz,apache-ant-1.9.15-bin.tar.gz,protobuf-2.5.0.tar.gz
1.1 安装maven
# 1. 解压maven包
tar -zxvf apache-maven-3.6.0-bin.tar.gz
# 2. 修改profile文件
vim /etc/profile
# 3. 添加以下配置
export MAVEN_HOME=/opt/apache-maven-3.6.0
export PATH=$PATH:$MAVEN_HOME/bin
# 4. 文件生效
source /etc/profile
# 5. 验证
mvn -version

1.2 安装ant
# 1. 解压ant包
tar -zxvf apache-ant-1.9.15-bin.tar.gz
# 2. 修改profile文件
vim /etc/profile
# 3. 添加以下配置
export ANT_HOME=/opt/apache-ant-1.9.15
export PATH=$PATH:$ANT_HOME/bin
# 4. 文件生效
source /etc/profile
# 5. 验证
ant -version

1.3 安装glibc-headers和g++
yum install -y glibc-headers
yum install -y gcc-c++
1.4 安装make和cmake
yum install -y make
yum install -y cmake
1.5 安装protobuf
# 1. 解压protobuf包
tar -zxvf protobuf-2.5.0.tar.gz
# 2. 进入目录
cd protobuf-2.5.0
# 3. 编译
./configure
make
make check
make install
ldconfig
# 4. 修改profile文件
vim /etc/profile
# 5. 添加以下配置
export PROTOBUF_PATH=/opt/protobuf-2.5.0
export PATH=$PATH:$PROTOBUF_PATH
# 6. 文件生效
source /etc/profile
# 5. 验证
protoc --version
![]()
1.6 安装openssl库
yum install -y openssl-devel
1.7 安装ncurses库
yum install -y ncurses-devel
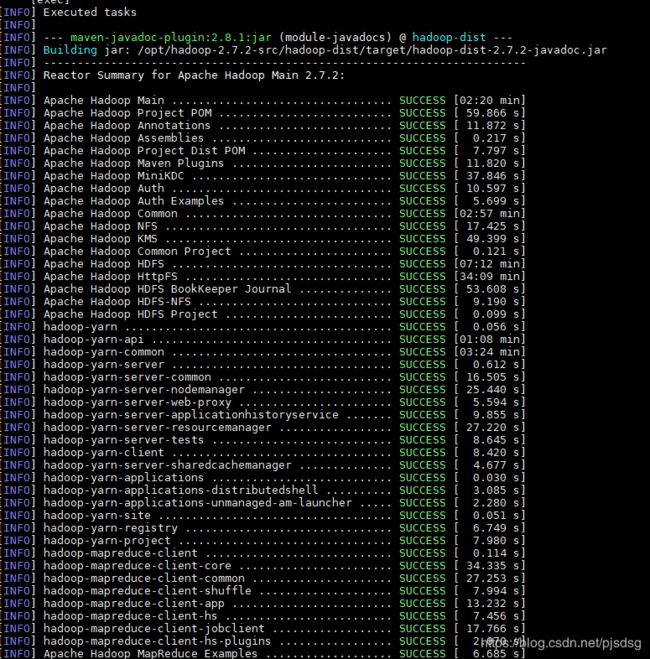
1.8 编译Hadoop源码
# 1. 回到opt目录
cd /opt
# 2. 解压hadoop
tar -zxvf hadoop-2.7.2-src.tar.gz
# 3. 进入hadoop目录
cd hadoop-2.7.2-src
# 4. 编译打包源码
mvn package -Pdist,native -DskipTests -Dtar
或者
mvn clean package -Pdist,native -DskipTests -Dtar
# 5. 复制编译报到opt目录下
cp hadoop-2.7.2.tar.gz /opt/
# 6. 解压
tar -zxvf hadoop-2.7.2.tar.gz
# 7. 修改profile文件
vim /etc/profile
# 8. 添加以下配置
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
# 9. 配置生效
source /etc/profile
1.9 修改core-site.xml
vim etc/hadoop/core-site.xml
添加以下配置
<!--指定HDFS中NameNode的地址-->
fs.defaultFS</name>
hdfs://localhost:9000</value>
</property>
<!--指定hadoop运行产生文件(DataNode)的存储目录-->
hadoop.tmp.dir</name>
/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
1.10 修改hdfs-site.xml
vim etc/hadoop/hdfs-site.xml
添加以下配置
<!--指定HDFS副本数量,这里只设置了一个节点(hadoop01)副本数量为1-->
dfs.replication</name>
1</value>
</property>
</configuration>
1.11 启动
1.11.1 格式化namenode
第一次启动时格式化,以后就不要格式化了,如果之后再格式化则namenode为新生成的,就找不到DataNode
bin/hdfs namenode -format
1.11.2 启动namenode
sbin/hadoop-daemon.sh start namenode
1.11.3 启动datanode
sbin/hadoop-daemon.sh start datanode
1.11.4 查看系统进程
jps

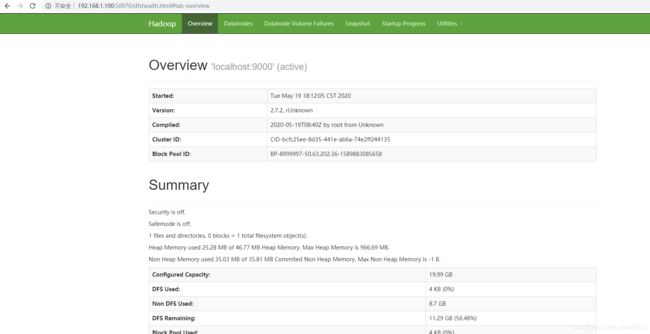
1.11.5 测试是否启动成功
访问 http://192.168.1.100:50070查看是否启动成功
2. 词频统计
安装完单机版hadoop之后,我们做一个词频统计,在一个文本中查看每个字母出现的次数
2.1 创建存储目录
bin/hdfs dfs -mkdir -p /user/root/input
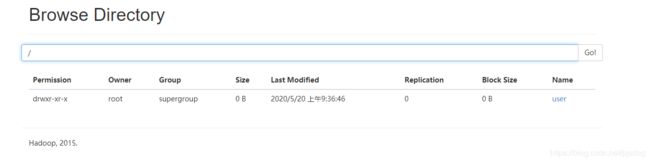


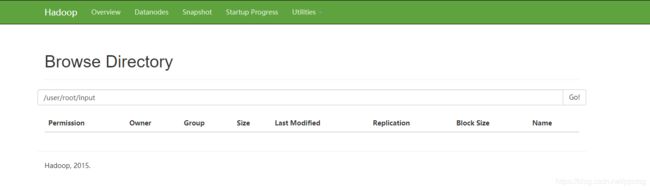
文件夹创建成功
2.2 上传文件资源
创建一个wc.txt文件,在文件里写入任务英文字母
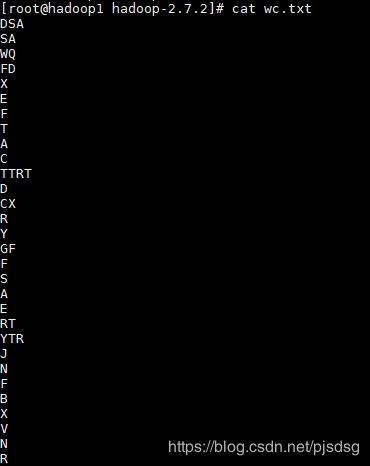
上传文件资源
bin/hdfs dfs -put wc.txt /user/root/input
查看是否上传成功
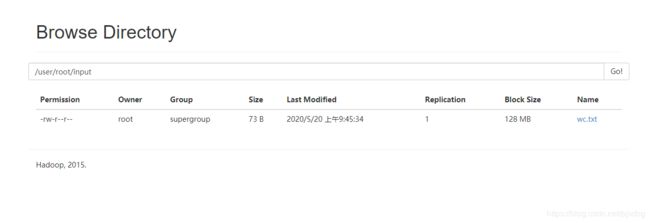
2.3 运行MapReduce程序
这个是在单机版下本地版运行,并没有提交到yarn上。
hadoop会给我们提供一些mapreduce程序,我们由于没写mapreduce程序,可以用hadoop的示例来进行演示
执行命令
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/root/input /user/root/output
参数讲解
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar :mapreduce程序
wordcount : 词频统计
/user/root/input : 测试文件目录
/user/root/output : 结果输入目录,输出目录必须是一个不存在的文件夹
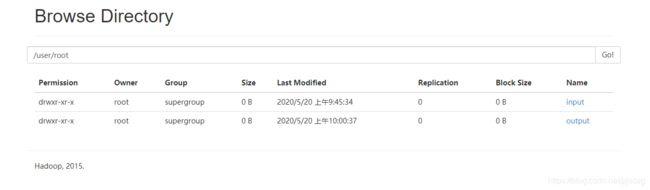

点击下载查看次词频统计结果cd

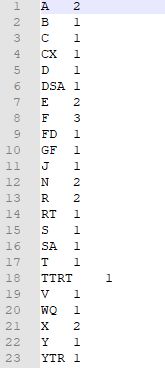
2.4 删除输出结果
# 删除文件
hadoop dfs -rm -f /user/root/input/wc.txt
# 递归删除全部
hadoop dfs -rm -r /user/root/output
2.5 递归查看目录
hadoop fs -lsr /
3. 在YARN上运行MapReduce程序
3.1 停止datanode和namenode
要先停止datanode再停止namenode
sbin/hadoop-daemon.sh stop datanode
sbin/hadoop-daemon.sh stop namenode
3.2 yarn-env.sh 添加java环境变量
cd /etc/hadoop/
vim yarn-env.sh
添加以下配置

3.3 配置yarn-site.xml
vim yarn-site.xml
添加以下内容
<!--reducer获取数据的方式-->
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
<!--指定yarn的resourcemanager地址-->
yarn.resourcemanager.hostname</name>
hadoop1.com</value>
</property>
3.4 配置mapred-site.xml
mapred-site.xml.template模板文件重命名mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
修改mapred-site.xml
vim mapred-site.xml
添加以下配置
<!--运行MapReduce作业的运行时框架-->
mapreduce.framework.name</name>
yarn</value>
</property>
3.5 启动namenode和datanode
启动时先启动namenode再启动datanode
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
3.6 启动resourcemanager
sbin/yarn-daemon.sh start resourcemanager
3.7 启动nodemanager
sbin/yarn-daemon.sh start nodemanager
3.8 检查启动成功
web浏览器中查看 : http://192.168.1.100:8088
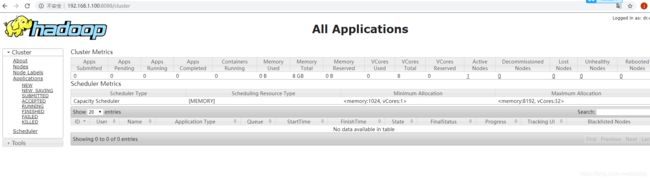
3.9 执行mapreduce程序(wordcount示例)(如果以前执行产生过output目录,先删除)
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/root/input /user/root/output
运行成功

4. 配置日志
MapReduce 的 JobHistory Server,这是一个独立的服务,可通过 web UI 展示历史作业日志,之所以将其独立出来,是为了减轻 ResourceManager 负担。JobHistory Server 将会分析作业 运行日志,并展示作业的启动时间、结束时间、各个任务的运行时间,各种Counter数据等,并产生一个指向作业和任务日志的链接,其默认端口号为 19888。通常可以启动在一台独立的机器上。
4.1 停止各项服务
sbin/hadoop-daemon.sh stop datanode
sbin/hadoop-daemon.sh stop namenode
sbin/yarn-daemon.sh stop nodemanager
sbin/yarn-daemon.sh stop resourcemanager
4.2 配置mapred-site.xml
在mapred-site.xml文件中添加以下配置
<!--配置历史服务器的地址及端口-->
mapreduce.jobhistory.address</name>
hadoop1.com:10020</value>
</property>
<!--配置历史服务器的web界面地址与端口-->
mapreduce.jobhistory.webapp.address</name>
hadoop1.com:19888</value>
</property>
4.3 配置日志聚合
在yarn-site.xml文件中添加以下配置
<!--日志聚集功能使能-->
yarn.log-aggregation-enable</name>
true</value>
</property>
<!--日志保留时间设置7天-->
yarn.log-aggregation.retain-seconds</name>
604800</value>
</property>
4.4 启动服务
sbin/hadoop-daemon.sh start datanode
sbin/hadoop-daemon.sh start namenode
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
mr-jobhistory-daemon.sh start historyserver

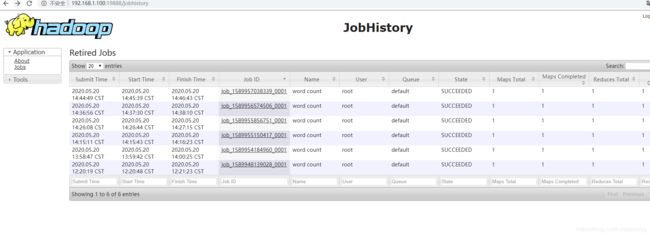
4.5 执行wordcount程序查看日志
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/root/input /user/root/output
访问http://192.168.1.100:19888/jobhistory 查看日志