浅谈智能客服机器人的产品设计
序言
智能客服发展空间
中国客服行业正处在云客服+智能客服机器人的阶段,2018年智能客服业务规模达到27.2亿元,以NLP技术为主的客服机器人业务规模为7.9亿元。预计2022年智能客服机器人的业务规模将为71亿元。以上数据来源于艾瑞咨询,详情见下图:

智能客服服务场景
目前一个较为完整的智能客服行业解决方案中,一般包含的服务场景有:智能机器人、智能语音导航IVR、智能外呼/营销、智能质检等。以下是阿里云对外公布的智能客服应用框架。
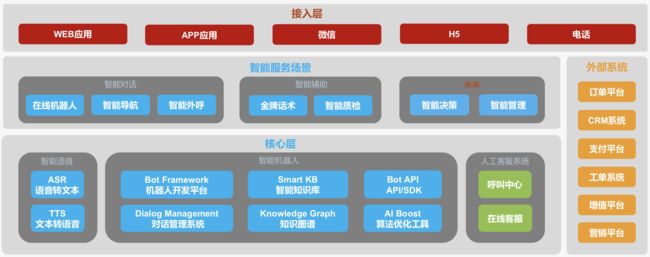
智能客服给B端企业带来的价值:降低人工成本(一般来讲能节省10%客服运营成本)、提高工作效率、提供更精准准业回答等。
而智能客服最大的隐性价值在于实际场景中得到的标准化后的数据积累,可以在挖掘客服价值信息中起到降本增效的作用,后续还可以作精准营销和产品升级。
本文我主要梳理的是客服机器人的产品设计。
一、用户诉求与产品目标
在我的上一篇文章中提过问答型和任务型机器人的优化目标在于:用最短的对话轮次,满足用户的需求。这在智能客服机器人同样适用,所以我们的产品设计目标应该是:用最短的对话轮次,或者说最短的路径,来为用户提供服务。
用户的诉求是:通过最短路径,获得精准、直接的答案以及很好地完成任务。
二、基于场景的产品架构
1.用户问题分类
客服机器人目前被大量使用在电商、金融、银行等系统中,所以我们以银行业务为例分析使用客服的业务场景后,将用户的问答归为下面几类:
1)常见问题。如:手机银行转账限额多少。
2)咨询理财/贷款产品和服务。比如某个基金的赎回时间,或者更精准的问题:哪款产品预期收益率最高?
3)个人信息查询或业务办理。比如查询余额、转账业务、购买理财产品、申请贷款等。
4)聊天/寒暄。银行业务场景下,一般都是起兜底作用的寒暄。
2.路由机器人
为了解决用户的以上的问题,在应用中通常会包含不同类型的机器人,那到底当用户输入问题后,应该选择哪类型机器人呢,这就是智能路由机器人(Route-Bot)的工作了。看下图的基于场景的产品架构图(此图来源于 关于对话机器人,你需要了解这些技术)

路由机器人在对用户问题的意图识别后,会结合历史背景,决定把问题发送给哪些机器人,以及将最终使用哪个机器人的答案作为提供给用户的最终答复。
根据上面关于银行业务的问题划分,我们需要用到机器人类型有:检索型对话机器人FAQ-Bot、知识图谱型机器人KG-Bot、任务型机器人Task-Bot,同时可能会有用于寒暄的闲聊型机器人。下面分析这几种类型bot的设计。
三、检索型机器人FAQ-Bot
在客服处理的问题中70%都是简单的问答业务,只要找到QA知识库中与用户当前问句语义最相近的标准问句,取出答案给用户就可以了。FAQ-Bot就是处理这类问题的。在没有使用深度学习算法之前,通常采用检索+NLP技术处理。
1.适用场景
适用于解答非用户个性化的问题,返回的是静态知识,无需调用接口返回答案。
2.问答系统处理流程

基本的问答流程如下:
1)用户提出问题:“怎样才能使用刷脸转账”
2)本体识别:用户问题分析后,识别出本体为“刷脸转账”
3)计算FAQ相似度:问题与知识库里的标准问题根据相似度计算后召回,例如:
- Q1: “如何使用刷脸转账?”,相似度0.56;
- Q2: “使用刷脸转账的前提条件有哪些?”, 相似度0.92 。
4)候选答案排序:Q2-Q1
5)若阀值设定为0.9,Q2达到阀值,返回Q2问题的答案。如果有多个答案都到达阀值,选相似度最高的标准问题的答案返回给用户。如果都没有达到阀值的,但达到推荐阀值的答案有几个的,显示推荐的答案。
6)本体继承:把“刷脸转账”继承至下文
7)继续提问:用户问“怎么刷”,话题继承。
3.知识库的设计
FAQ-Bot是基于知识库匹配算法设计的,所以首先需要搭建本体知识库,通过新增和维护机器人知识库,来提升机器人问答的准确率和用户体验。下图是云小蜜的知识库管理页面:

1)它的层级结构是:类目—> 词条, 这里的词条就可以理解为本体,它是关键词的模板。所以当用户问“如何开户”时,识别出来的本体/词条就是“开户”。
2)每个词条需要维护的信息有:同义词、关联问题、相似问题、分类等。其中分类主要用于知识点的管理,当某一分类下数据量较大时,分类还可以作为算法聚类的一个标记,认为分类下的问题相关度高,在检索匹配时作为一个计算因子。

3)本体识别,可看作一个文本分类问题。
QA语料添加与维护,可以分为三个阶段:
1)机器人上线前,处理已有QA。
- 若业务上线前,客户已经有一定的原始用户语料积累,比如通过线上客服渠道或者论坛等积累的问答对,或者有大量用户咨询的问题。可以使用聚类工具自动聚类后,再人工进行调整。知识库应该提供“批量导入”的功能(银行业务的场景基本都有原始的线上数据,可以通过爬取这些数据后做清洗,提炼出高频问题,然后进行优先处理)
2)冷启动阶段,人工添加+NLP手段扩充语料。
前期没有标注数据的,需要人工手动标注数据。但因为问题和候选答案包含的词通常都很少,此时可以利用同义词、复述句对问题和候选答案进行扩展和改写。
- 功能上:在编辑界面支持“增加同义词”、“新增相似问句”的功能(如小蜜的划词功能)

- 算法上:用词表示工具,如Word2vec、Glove、 Fasttext来获得每个词的向量表示,然后使用词向量计算每对词之间的相似性,获得同义词候选集; 也可通过已经存在的结构化知识源如WordNet、HowNet等获得同义词; 相似问句方面,系统可以使用自动聚类的方式推荐相似问句。
以上这些手段都可以提高模型的泛化能力。
3)机器人上线后,人工标注迭代。
- 系统上线后,对于回流数据(没有答案的、机器推荐而用户没有点击的、机器回答错误的、用户不满意的问题等)进行诊断,系统将这些语料先做聚类,然后由标注人员作统一处理。
- 具体处理方式可以有:答案纠错、标注到已有问题的相似问题里、新增知识/词条、标注为负训练样本、优化词条和问题标题/关键词等。
- 从产品层面上,应该提供知识库的“badcase标注”功能,以及提供测试模拟窗口功能(测试demo也是一般平台都会有)
4.语义相似度计算
通常根据训练方式不同,从前期无标注数据到有一定量标注数据,语义相似度的算法也向深度学习迭代:
1)无监督学习:冷启动阶段没有足够标注数据时,通常使用无监督学习算法。将用户问句和标准问题作降维得到向量表示,用余弦相似度等方法计算出句子间语义相似度(值越靠近1说明越相似)
2)监督学习:机器人上线后经过用户问题和重新标注过程,积累了一定的数据后,通常可使用深度学习算法。如基于RNN的语言模型。用RNN训练出来的语言模型,采用其隐层状态作为词向量,将词向量代入其他需要word embedding的问答匹配方法中,经验证,可以取得比原方法更优秀的表现。
5.阀值
1)关注阀值的可配置性:从产品层面输入阀值后,改变相对应的输出结果。如果阀值配得过高,会影响召回率;太低又会影响准确率。要根据业务场景做权衡。
2)在云小蜜中,还设置了问题推荐的阀值。处理逻辑是:当结果达到直出阀值,直接给出答案; 未达到直出阀值,但达到推荐阀值的,给出几个推荐回答; 未达到推荐阀值的,给出无答案回复。无答案回复可以进入配置后台进行配置。

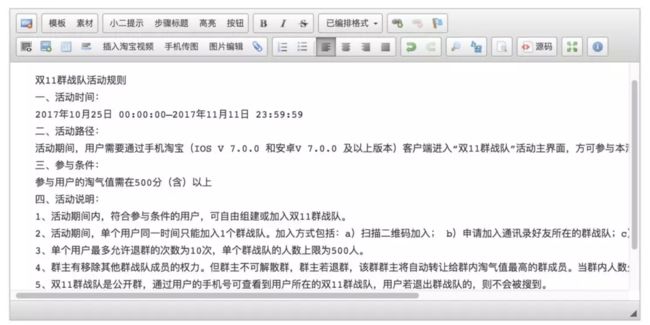
小蜜的这个推荐阀值是基于机器阅读理解模型训练的,目前设计是在知识库的词条中进行维护,添加段落,模型会自动列出将关联问题和答案。但此模型与领域相关,向其他领域快速扩展是一个比较大的挑战。下图是阿里双11的活动设置案例
6.信息咨询型多轮对话
简单问答中除了单轮对话外,也多轮对话的情况。这类咨询型多轮与任务型多轮有所区分。以下类型的多轮对话情况在FAQ-Bot中处理
1)情况1:条件挖掘。用户提问“如何开户?” ,机器人会返回“开户”的条件相关的提问“请问是希望通过下面哪个渠道办理:手机、网站、营业厅”,用户作出回答后,机器人返回答案。这个对话虽然是多轮,但不涉及用户的个性化信息,还是用语义匹配来实现。
2)情况2:话题继承。如用户提问“怎样才能用刷脸转账”,话题“刷脸转账”被记录下来了,若用户问“怎么刷”,机器人应该识别到是同一话题下的关联问题,并返回相应答案。
四、知识图谱型机器人KG-Bot
1.知识图谱的基础学习
知识图谱,拥有知识推断能力,能更直接回答用户的问题。
举个例子:
百度查询春节还剩多少天,会直接以卡片的形式显示答案“距今还有140天”,而不是给出一堆文档/网页的集合让用户自己去筛选和计算。这就是基于知识图谱做的。

PM要对知识图谱有基础了解。我参考了以下三个文章,也算获得了基础学习:
最全知识图谱综述#1: 概念以及构建技术
知识图谱的应用
浅谈知识图谱基础
这里讲下知识图谱的逻辑结构,它分为两个层次:数据层和模式层。
数据层一般存在两种三元组作为事实的表达方式。这两种三元组为:“实体—关系—实体”、“实体—属性—值”。
知识图谱结构示例图:

张三 is_father_of 李四: 张三、李四是实体,is_father_of是关系,指张三是李四的父亲。李四 has_phone 电话:电话也是实体,关系是has_phone。再在电话上加上属性如“开通时间”、“号码”,以及相应的值。这些通过预设定好的关系进行实体之间关系的定义最终形成知识图谱。
2.知识图谱可解决的问题
前面讲述的FAQ-bot解决了大部分的简单问句,但它无法解决更精准更复杂的问题。而知识图谱的优势在于:1)在对话结构和流程的设计中支持实体间的上下文会话识别与推理 2)且通常在一般型问答的准确率相对比较高(当然具备推理型场景的需要特殊的设计,会有些复杂。)基于这些优势,用知识图谱可推理的问题种类有如下(以下来源于百度AI赋能的搜索和对话交互报告):
- 『主语+谓词』:刘德华的老婆
- 『谓词+取值范围』:180cm以上的男明星
- 『谓词+排名』:世界第五/第八/第十高峰
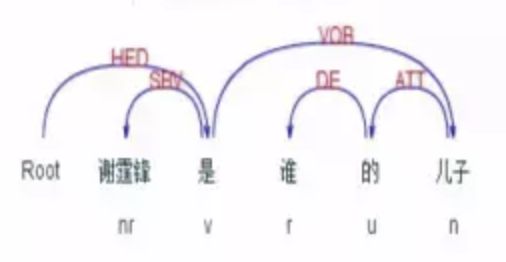
- 多步推理:谢霆锋的爸爸的儿子的前妻的年龄
- 但有些问句需要先对其进行[句法分析],才能确定如何查询知识图谱。如“谢霆锋的儿子是谁”
3.KG-Bot的难点
KG-Bot有两大难点:
- 知识图谱的构建
- 把用户问题转化为知识图谱上的查询语言。
1)关于知识图谱的构建可参考上面文章链接,简单的构建流程是:
数据爬取—>数据解析(实体、关系、属性)—>数据插入—>关系建立。
2)转化为查询语言的实现流程可以简化为:意图识别—>实体识别—>属性识别—>问题分类
4.PM应该关注什么
1)在开发建构数据之前,应该重点关注和确认所有数据类型都包含在内。对每个节点(实体)建模和关系建模都要有所了解。避免遗漏部分所需数据,造成最后缺乏对应关系,无法关联上数据。
2)需要根据不同的场景,决定知识图谱最后的可视化呈现格式。
五、任务型机器人Task-Bot
任务型bot顾名思义是为用户完成某项任务,这类用户问题通常是需要调用第三方接口返回结果的。目标是在多轮交互中不断理解用户的意图,和根据用户的意图结果优化排序的结果和交互的过程。
国内外bot framework平台,如dialogflow、Alexa Skills Kit、Luis.ai、DuerOS、UNIT、Dui.ai中关于任务型机器人的设计思想大体相似。具体我的上篇文章点亮技能 I 人机对话系统全面理解讲开放平台体验中也有讲到,这里不再细讲。
任务型场景的三个要素是:领域、意图、参数
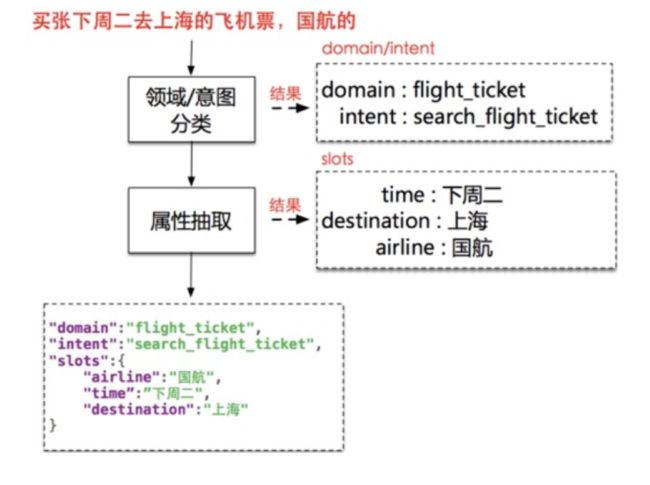
下图是小蜜任务型多轮对话交互设计中,配置“手机转账”意图页面例子:

意图的配置中包含的要素有:意图上下文(即语境)、用户表述、参数(含追问提示语句)、回复。
六、闲聊型机器人Chat-Bot
闲聊型bot的风格是娱乐风趣,对答案的准确性要求较低,知识的数据来源也是全部领域。
还是银行为例子,银行业务是垂直的领域,对问答准确性要求极高,要求智能客服机器人也是要严肃、负责的。所以闲聊型在此类场景优先级放在后面。在设计bot产品前,就要定义好产品边界和分析业务需求,来选择会用到的bot类型。
最后
衡量智能客服机器人的综合评估指标,一般是问题解决率。下面还有细分数据指标。分析未解决的原因,如果想要真正解决企业和客户的问题,还是要深入掌握领域的知识,切实到每个落地场景做分析。所以,懂行业/目标领域的PM才更具有优势,修炼成为行业专家也是我一直努力的方向。