实战解析朝生暮死的Redis拓展应用—过期策略和LRU,继续强化学习
今天,我们继续Redis的拓展应用,继续深化了解、强化学习效果。
拓展 4:朝生暮死 —— 过期策略
Redis 所有的数据结构都可以设置过期时间,时间一到,就会自动删除。你可以想象 Redis 内部有一个死神,时刻盯着所有设置了过期时间的 key,寿命一到就会立即收割。

你还可以进一步站在死神的角度思考,会不会因为同一时间太多的 key 过期,以至于忙不过来。同时因为 Redis 是单线程的,收割的时间也会占用线程的处理时间,如果收割的太过于繁忙,会不会导致线上读写指令出现卡顿。 这些问题 Antirez 早就想到了,所以在过期这件事上,Redis 非常小心。
过期的 key 集合
redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定时遍历这个字典来删除到期的 key。除了定时遍历之外,它还会使用惰性策略来删除过期的 key,所谓惰性策略就是在客户端访问这个 key 的时候,redis 对 key 的过期时间进行检查,如果过期了就立即删除。定时删除是集中处理,惰性删除是零散处理。
定时扫描策略
Redis 默认会每秒进行十次过期扫描,过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。
- 1、从过期字典中随机 20 个 key;
- 2、删除这 20 个 key 中已经过期的 key;
- 3、如果过期的 key 比率超过 1/4,那就重复步骤 1;
同时,为了保证过期扫描不会出现循环过度,导致线程卡死现象,算法还增加了扫描时间的上限,默认不会超过 25ms。
设想一个大型的 Redis 实例中所有的 key 在同一时间过期了,会出现怎样的结果?
毫无疑问,Redis 会持续扫描过期字典 (循环多次),直到过期字典中过期的 key 变得稀疏,才会停止 (循环次数明显下降)。这就会导致线上读写请求出现明显的卡顿现象。导致这 种卡顿的另外一种原因是内存管理器需要频繁回收内存页,这也会产生一定的 CPU 消耗。
也许你会争辩说“扫描不是有 25ms 的时间上限了么,怎么会导致卡顿呢”?这里打个 比方,假如有 101 个客户端同时将请求发过来了,然后前 100 个请求的执行时间都是 25ms,那么第 101 个指令需要等待多久才能执行?2500ms,这个就是客户端的卡顿时间, 是由服务器不间断的小卡顿积少成多导致的。
所以业务开发人员一定要注意过期时间,如果有大批量的 key 过期,要给过期时间设置 一个随机范围,而不能全部在同一时间过期。
# 在目标过期时间上增加一天的随机时间 redis.expire_at(key, random.randint(86400) + expire_ts)在一些活动系统中,因为活动是一期一会,下一期活动举办时,前面几期的很多数据都可以丢弃了,所以需要给相关的活动数据设置一个过期时间,以减少不必要的 Redis 内存占用。如果不加注意,你可能会将过期时间设置为活动结束时间再增加一个常量的冗余时间, 如果参与活动的人数太多,就会导致大量的 key 同时过期。
掌阅服务端在开发过程中就曾出现过多次因为大量 key 同时过期导致的卡顿报警现象, 通过将过期时间随机化总是能很好地解决了这个问题,希望读者们今后能少犯这样的错误。
从库的过期策略
从库不会进行过期扫描,从库对过期的处理是被动的。主库在 key 到期时,会在 AOF 文件里增加一条 del 指令,同步到所有的从库,从库通过执行这条 del 指令来删除过期的 key。 因为指令同步是异步进行的,所以主库过期的 key 的 del 指令没有及时同步到从库的话,会出现主从数据的不一致,主库没有的数据在从库里还存在,比如上一节的集群环境分 布式锁的算法漏洞就是因为这个同步延迟产生的。

拓展 5:优胜劣汰 —— LRU
当 Redis 内存超出物理内存限制时,内存的数据会开始和磁盘产生频繁的交换 (swap)。 交换会让 Redis 的性能急剧下降,对于访问量比较频繁的 Redis 来说,这样龟速的存取效率 基本上等于不可用。
在生产环境中我们是不允许 Redis 出现交换行为的,为了限制最大使用内存,Redis 提 供了配置参数 maxmemory 来限制内存超出期望大小。
当实际内存超出 maxmemory 时,Redis 提供了几种可选策略 (maxmemory-policy) 来让 用户自己决定该如何腾出新的空间以继续提供读写服务。
- noeviction 不会继续服务写请求 (DEL 请求可以继续服务),读请求可以继续进行。这样可以保证不会丢失数据,但是会让线上的业务不能持续进行。这是默认的淘汰策略。
- volatile-lru 尝试淘汰设置了过期时间的 key,最少使用的 key 优先被淘汰。没有设置过期时间的 key 不会被淘汰,这样可以保证需要持久化的数据不会突然丢失。
- volatile-ttl 跟上面一样,除了淘汰的策略不是 LRU,而是 key 的剩余寿命 ttl 的值,ttl越小越优先被淘汰。
- volatile-random 跟上面一样,不过淘汰的 key 是过期 key 集合中随机的 key。
- allkeys-lru 区别于 volatile-lru,这个策略要淘汰的 key 对象是全体的 key 集合,而不只是过期的 key 集合。这意味着没有设置过期时间的 key 也会被淘汰。
- allkeys-random 跟上面一样,不过淘汰的策略是随机的 key。
- volatile-xxx 策略只会针对带过期时间的 key 进行淘汰,allkeys-xxx 策略会对所有的key 进行淘汰。如果你只是拿 Redis 做缓存,那应该使用 allkeys-xxx,客户端写缓存时不必携带过期时间。如果你还想同时使用 Redis 的持久化功能,那就使用 volatile-xxx策略,这样可以保留没有设置过期时间的 key,它们是永久的 key 不会被 LRU 算法淘汰。
LRU 算法
实现 LRU 算法除了需要 key/value 字典外,还需要附加一个链表,链表中的元素按照一定的顺序进行排列。当空间满的时候,会踢掉链表尾部的元素。当字典的某个元素被访问时,它在链表中的位置会被移动到表头。所以链表的元素排列顺序就是元素最近被访问的时间顺序。
位于链表尾部的元素就是不被重用的元素,所以会被踢掉。位于表头的元素就是最近刚刚被人用过的元素,所以暂时不会被踢。 下面我们使用 Python 的 OrderedDict(双向链表+字典) 来实现一个简单的 LRU 算法。
from collections import OrderedDict
class LRUDict(OrderedDict):
def __init__(self, capacity):
self.capacity = capacity
self.items = OrderedDict()
def __setitem__(self, key, value):
old_value = self.items.get(key)
if old_value is not None:
self.items.pop(key)
self.items[key] = value
elif len(self.items) < self.capacity:
self.items[key] = value
else:
self.items.popitem(last=True)
self.items[key] = value
def __getitem__(self, key):
value = self.items.get(key)
if value is not None:
self.items.pop(key)
self.items[key] = value
return value
def __repr__(self):
return repr(self.items)
d = LRUDict(10)
for i in range(15):
d[i] = i
print d近似 LRU 算法
Redis 使用的是一种近似 LRU 算法,它跟 LRU 算法还不太一样。之所以不使用 LRU算法,是因为需要消耗大量的额外的内存,需要对现有的数据结构进行较大的改造。近似LRU 算法则很简单,在现有数据结构的基础上使用随机采样法来淘汰元素,能达到和 LRU算法非常近似的效果。Redis 为实现近似 LRU 算法,它给每个 key 增加了一个额外的小字段,这个字段的长度是 24 个 bit,也就是最后一次被访问的时间戳。
之前咱们提到过处理 key 过期方式分为集中处理和懒惰处理,LRU 淘汰不一样,它的处理方式只有懒惰处理。当 Redis 执行写操作时,发现内存超出 maxmemory,就会执行一次LRU 淘汰算法。这个算法也很简单,就是随机采样出 5(可以配置) 个 key,然后淘汰掉最旧的 key,如果淘汰后内存还是超出 maxmemory,那就继续随机采样淘汰,直到内存低于maxmemory 为止。
如何采样就是看 maxmemory-policy 的配置,如果是 allkeys 就是从所有的 key 字典中随机,如果是 volatile 就从带过期时间的 key 字典中随机。每次采样多少个 key 看的是maxmemory_samples 的配置,默认为 5。
下面是随机 LRU 算法和严格 LRU 算法的效果对比图:
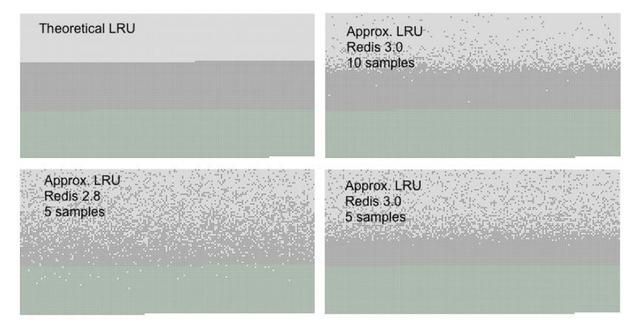
图中绿色部分是新加入的 key,深灰色部分是老旧的 key,浅灰色部分是通过 LRU 算 法淘汰掉的 key。从图中可以看出采样数量越大,近似 LRU 算法的效果越接近严格 LRU 算法。同时 Redis3.0 在算法中增加了淘汰池,进一步提升了近似 LRU 算法的效果。
淘汰池是一个数组,它的大小是 maxmemory_samples,在每一次淘汰循环中,新随机出 来的 key 列表会和淘汰池中的 key 列表进行融合,淘汰掉最旧的一个 key 之后,保留剩余较旧的 key 列表放入淘汰池中留待下一个循环。
好了,这就是本期小编整理的Redis拓展应用——过期策略和LRU,只是小编自己的理解,有哪里不准确的地方,还请大佬们指出,咱们共同进步。
喜欢的话请多多点赞评论分享,让更多人看到获益,关注小编,后续小编会带来更丰富的学习内天更新,你们的支持就是小编最大的动力!!!