零基础Python爬虫教程和实战(一)
今天我们来学爬虫,这个系列预计会出11期
爬虫原理:
------------------什么是爬虫?-----------------
请求网站并提取数据的自动化程序
------------------爬虫的分类 --------------------
- 通用网络爬虫(全网爬取,搜索引擎,爬行的范围和速度是巨大的,但速度慢,有用和无用的数据需要很多的存储空间,而且需要很多只爬虫一起爬)
- 聚焦网络爬虫(我们平时要写的爬虫,有选择性的去爬取,不会获取无用的数据)
-------什么是requests和response?-------
他们两个也叫HTTP requests和HTTP response
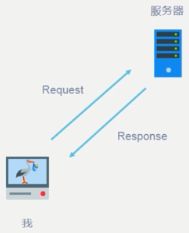
(1)浏览器发送消息给某个网址所在的服务器,这个过程就叫做HTTP requests
比如你在上方的网址区输入网址,它就会给该网址所在的服务区发送HTTP Requests
(2)服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应处理,然后把消息回传给浏览器。这个过程叫做HTTP Response.
比如你写出了某个网址,浏览器把请求上传到了那个网址的服务器中,服务器会传回给你一些HTML的代码,就构造了你想看到的网页
(3)浏览器收到服务器的Response信息后, 会对信息进行相应处理,然后展示
------------Requests中包含什么?-------------

请求方式
GET: 单纯地从服务器里提取数据,请求的时候不带任何数据和参数。
POST: 发送的请求当中携带一些数据,就像登陆,你需要填账号密码。
请求URL
在发出的请求中,总会包含URL,这样才能知道请求到哪个服务器去,服务器也会根据你发的URL来给你提供相应的服务。
请求头
User-Agent: 用来标识请求是从哪里来的,如果是从浏览器发起的请求,User-Agent会标示浏览器的信息。如果是爬虫发起的请求,User-Agent会标识编程语言的名字。
Host: 主机
Cookies: 用来存储用户的信息,比如你登录就会存储登录的信息。下次要是再去请求目标网址,由于你cookies里已经有登录的信息,就不用再去登陆。
请求体
存储发出请求时需要额外携带的数据。因为他是存储携带数据,所以当get请求的时候,请求体是空的。
------------Response中包含什么?------------

响应状态
200 代表 成功
301 代表 网址被移到其他地,要跳转
404 代表 找不到页面
502 代表 服务器错误
当我们向服务器发起请求的时候,第一件事就是要判断响应状态
响应头
它里面有内容类型,内容长度,还会帮我们设置cookie值
响应体
我们向网址发起请求时,希望得到网址背后的数据,就是包含在响应体当中。
有HTML的框架呀,有图片呀,或者还有视频。
例子:
一般来说每个浏览器都会有一些检查工具,就比如我是chrome浏览器,只要在你想要检查的页面右键就可以了。
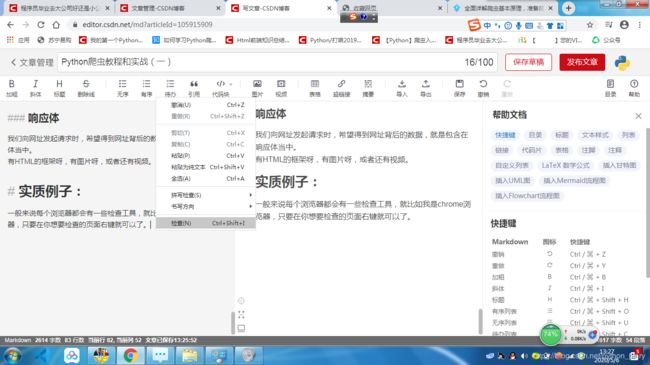

Elements选项卡
Elements选项卡里面包含的是此网页的HTML代码文档右边跟着的styles是它的样式表。我们看到的那些网页都是HTML代码结合它的样式表呈现出来的。不懂也没关系,待会儿会讲
如果我想知道某个数据存在的位置,选项卡的左上角就会出现这样一个标志。
![]()
点开它,你的鼠标指到哪里,那里的代码就会显现给你
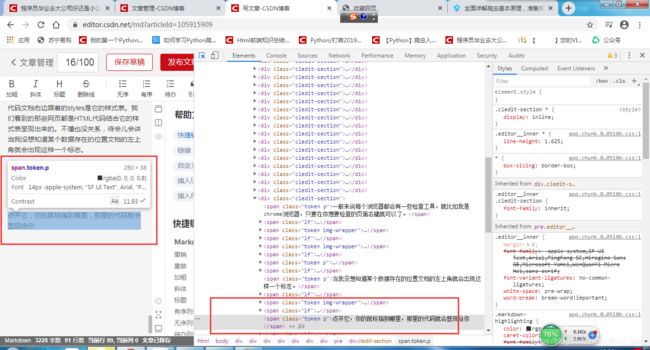
Network选项卡
Network选项卡他会完整的记录我们的浏览器在请求服务器中的完整过程。
我们就用百度来演示一下Network选项卡的用处。
打开百度并刷新一下

每一行都表示浏览器向服务器发起了一次请求,首先,我们向www.baidu.com发起了第一次请求,让我们来看一看这个请求当中的包含什么数据吧

General
这里的 requests URL 代表的是 向什么网址发起的请求
这里的 Request Method 代表的是 发起的请求方式,比如这里是直接请求,不在网页上输入什么东西,所以方式是get请求
这里的 Status Code 代表的是 请求的状态,这里是200,所以请求成功
这里的 Remote Address 代表的是 远程服务器的地址
Referrer Policy这东西没什么用
这里的 requests URL 代表的是 向什么网址发起的请求
Requests headers
这里的 Accept 代表的是 告诉服务器我的浏览器接受什么样格式的内容
这里的 Accept-Encoding 代表的是 编码格式
这里的 Accept-Language 代表的是 语言
这里的 Cache-Control 代表的是 缓存的控制
现在只用记住General就行了
第一个请求完之后,为什么后面还会连续的向服务器发送这么多请求呢?
从检查中的response中可以看到:
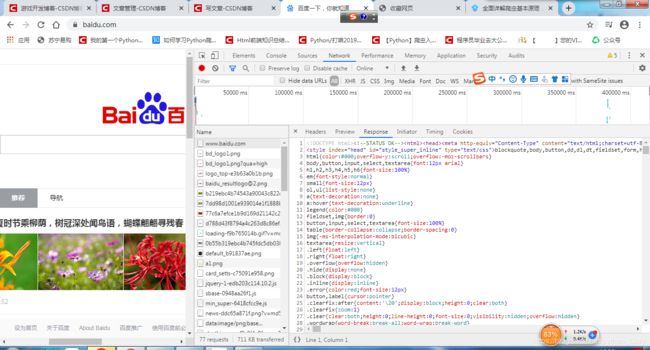
向浏览器中请求数据后会得到一份HTML的文档。在这文档里有各种的各样的超链接以及图片,这都是需要向服务器中获取的。

可以看到,虽然后面请求的那些数据的URL都有www.baidu.com,但是后面还有一些地址,因为各种图片信息存放的地址都不相同,我们顺着地址去找找看

如果想快速查看请求的结果,可以用preview选项卡:

刚才的百度请求数据是get请求方式,接下来我们要讲一下post请求方式
Post请求方式就是带数据的请求方式,登录就是其中一个例子

看,我登陆之后由于我是带着参数去向服务器请求,所以请求方式变成了post

看这里还记录了我们的登录信息。
----------------能抓怎样的数据?----------------

大部分来说,只要看得到就能抓到
我们之前曾提到过HTML文档,那么HTML究竟是什么东西呢?
我懒,所以![]()
b站的全套视频,只用看到40集,有兴趣可以看完
--------------------怎样来解析?------------------
一般来说,我们抓回来的数据都不是我们想要的
他抓回来的,可能是一整个网页。可是我需要的,可能只是一些链接标题。
在这里我们就得用到解析,不同的格式就要用到不同的解析方法。解析方式有:

直接处理: 直接处理就是说你把数据接收回来之后,它是一些二进制数据或者数据就是你想要的,你就可以直接保存
Json解析: 如果你抓回来的数据是Json格式的字符串,你就可以用到Json解析
正则表达式: 如果你抓回来的数据是一个HTML的页面,你就可以用正则表达式来作为解析。当然,HTML这并不是唯一的解析方法。正则表达式不仅适用于页面解析,它还可以用于匹配字符串的各个元素,它是通过定义一些模式,来达到匹配字符串的操作
BeautifulSoup: 这是一个Python的第三方库,它是专门用来做页面解析的,它是用来专门解析HTML页面和XML页面的。它是通过HTML页面的标签来做的解析。b站的视频说过,HTML的页面是由一个个标签组成的。而BeautifulSoup内部就定义了一个个通过标签来查找的一些方法
PyQuery: PyQuery这门解析方式我不喜欢用,因为前端有一个模板叫做jQuery。所以拍PyQuery是为熟练用jQuery的人设计的。如果你熟悉jQuery的话,你可以用一下PyQuery。但是你得上网找教程,因为我不会讲我不会的东西
XPath: 这个解析方式是用来把HTML文档构建成一棵树的形状,HTML本身就是相似一棵树,他有父节点,子节点,和兄弟节点。而XPath就是用来查找各个节点以达到解析页面的效果。
-为什么我抓到的和浏览器看到的不一样?-
有的时候我们抓回来的数据不一定就是我们想要的,只有抓回来的数据是我们想要的,我们才用解析的必要。就比如百度,每次你访问服务器baidu.com时候,你应该会发现每次他给我们刷新的信息都不一样。
简单来说,页面分为两种: 动态页面 和 静态页面 :

可能一张表看不出个所以然,我们就取一个实际的例子:
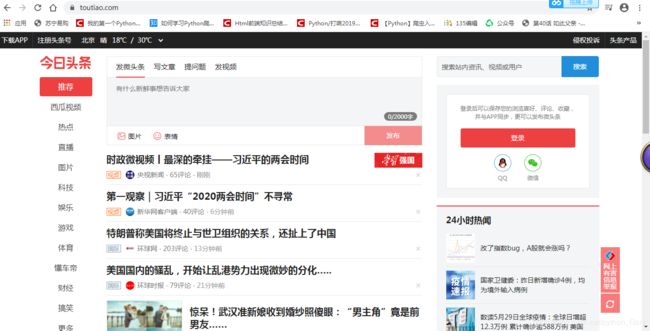
大家应该也知道今日头条这个网站。今日头条这个网站是一个动态页面。
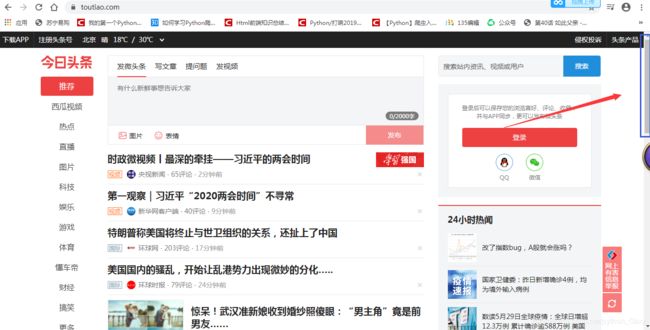
这是怎么个动态法呢?原本它的滚动长度就是这么多,当我往下滑的时候,它就变短了:
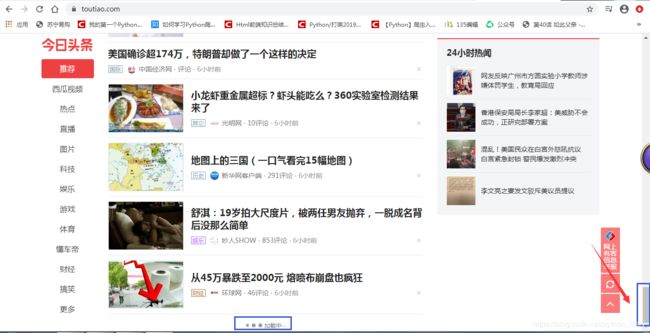
滚动条变短了,下面的加载中也正说明这个网页源代码,里面有一些js脚本在特定条件下会再次向服务器发起请求,而且不会触发新的页面和链接,不同的请求,这就叫做动态页面。我们的博客也是动态页面,在首页往下滚也会出现新的信息。不过不是所有的。

比如我的博客页面,就算使劲往下翻,我没有多做博客,他也就不会继续加载。这种无论鼠标怎么滚动都不会发生变化的页面就叫静态页面。
注意:静态页面也包含一些能动的部分,就比如一些GIF的动画,尽管我博客意面的背景能动,但是它仍然是静态的。静态页面的网页是每次你打开网页之后都都是一样的,除非改动它。而动态网页是向服务器去请求一些信息,像百度一样,每次进去之后效果都是不一样的。
感觉有点跑题了,继续跑
JavaScript:
动态页面它是怎么实现的呢?想要编写动态页面,就需要在HTML代码里嵌入一些家JavaScript编程语言的信息。

现在我要用灵犀教育作为例子

当你看到Scripts的标签的时候,你就会知道后面的将会是JavaScript的代码。

JavaScript的代码会给你的浏览器增加一些功能。比如这个就是给你的浏览器判断你的账号密码是否为空。这样会给你的网页增加一些动态的功能。

JSON:

有时候我们爬取回来的会是一个Json格式的数据,它是一种数据交换的格式,所以说他不属于任何编程语言,也就是说,无论是哪种语言都可以用Json这种格式。
其实它实际上就是一个特殊格式的字符串,非常像Python语言里的字典,但却不是字典。所以我们如果爬回来的数据是Json格式,之后往往要做的事就是把它和字典做一次类型转换,把Json格式转换成字典。然后再对他做各种各样的操作。
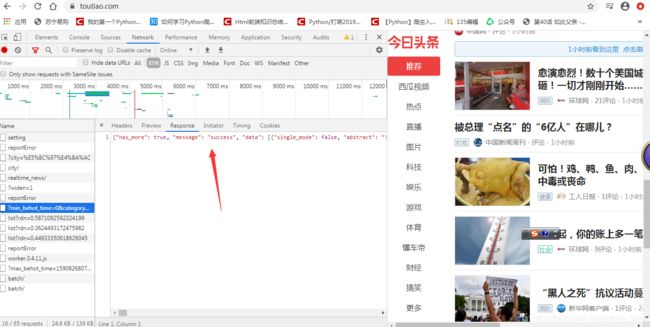
看,这个就是JSON格式。是不是很像Python字典?
注意:Json只是一种数据格式,并不是一种语言。还有,Json不是字典,所以不能直接进行操作,必须先转换。
Ajax:
除了Json这种格式之外,我们还需要注意的就是Ajax。

Ajax也不是一种编程语言,之前我们讲的JavaScript是继续向服务器请求信息,在今日头条里,鼠标向下滚动也只会刷新新的新闻,不会去动之前的新闻。而这整个JavaScript异步传输的技术就叫Ajax。所以说它不是任何一个实际的东西,它只是一个技术。
而我们判断一个网页是否用了Ajax,最简单的办法就是当我们和网页触发了一个事件之后页面有没有刷新的状态。
如果是整个页面都刷新,那就没有动用Ajax。如果是之前的内容还在,只不过是增加了新的内容,那他就动用了Ajax。
------------怎样解决JavaScript渲染问题?------------
有的时候由于Java script的原因,我们看到的和我们抓到的不一样,这种怎么解决呢?

分析Ajax请求:
我们可以通过分析在传输数据的过程中,浏览器向服务器发起了怎样的请求,才能把我要的这些数据抓取回来。

这些就是我们向服务器发起的请求

因为我们越往下滑,这些请求就会越频繁的出现,所以说明这些就是我们向服务器发起的请求。
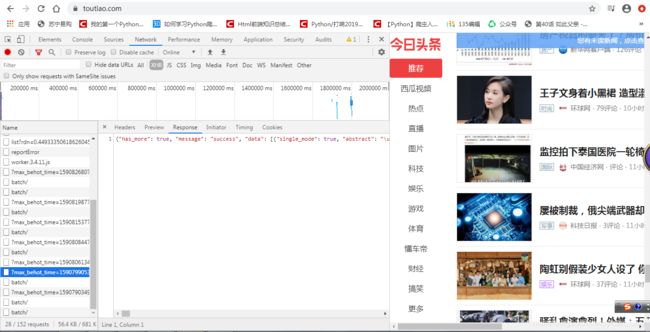
我们可以判断返回来的response是不是我们要找的新闻。如果他不是,我们就可以去找一下其他的请求
所以说,我们可以先分析一下发起的Ajax请求,然后找到我们要的网址,然后我们再对那个网址发起请求就可以了。
不过这种方法也不是对所有网站都管用,因为有些网站可能会让你找不到你想要的东西。这种情况我们就要借助另外一个工具: Selenium 。它是一个浏览器驱动,可以像我们人一样来操控浏览器。不过它只是一个测试包,所以能不用就不用。
其他的解析方式我也比较少用,所以今天不讲原理
--------------------可以怎样保存文件?-------------------
如果我们抓的静态页面,我们还可以通过一些解析方式来解析。如果我们抓的页面是个动态页面,那我们就要进一步的分析那个请求,把真正请求的URL找出来,对他发起请求。那我们要怎么保存数据呢?
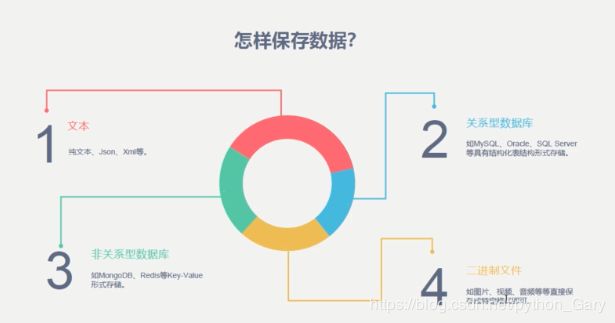
保存的方法有很多种,你可以保存成纯文本的文件。比如我抓回来的,如果是个Json格式的字符串,我就可以把它直接存到我的文本文件里面。如果我们抓回来的数据是一个关系型的数据,我们就可以把它保存到一些关键型的数据库,非关键型的数据也是同理。如果你抓到的是一个二进制的文件,比如是视频或者是图片,你就可以保存成特定格式就可以了。就比如你可以把它保存到桌面,视频后缀名可以是mp4,图片后缀名可以是ico。
这样说来,我们整个爬虫的流程就学完了。去请求URL,分析,判断,数据保存。
接下来,等我们下节课进入写代码流程的时候,我们要做这些准备工作:
准备工作:
- urllib 标准库,无需安装直接import使用
- requests 库,需要安装,pip install requests
- selenium库,需要安装,pip install selenium
selenium库要想驱动浏览器的话,还需要下载浏览器驱动。
我用的是chrome浏览器,我也推荐你们用chrome浏览器。这是chrome的驱动下载地址:
http://npm.taobao.org/mirrors/chromedriver/
注意:浏览器的驱动必须和你的浏览器版本一致,要不然无法驱动。
比如我的浏览器是80.3987

下载完压缩包之后,把压缩包里的软件解压到path的Scripts的地址里

- re #正则,标准库,不需要安装
- BeautifulSoup,html/xml 解析库,需要安装,pip install beautifulsoup4
不要拼错 - pymysql, MYSQL 数据库驱动,需要安装,pip install pymysql
期待我们的下次相见。
ps:
我又把之前出的基础知识框架的博客检查了一遍,发现有一些重点地方我没有讲,所以我还会出一期,当做是整理复习。