我用Python爬取了租房网站的信息,再也不怕租不到舒适的房啦
python爬虫需要学习那些知识呢?学习一些抓包知识,有些网站防爬,需要人工浏览一些页面,抓取数据包分析防爬机制,然后做出应对措施。比如解决cookie问题,或者模拟设备等。不过对前端也要比较熟悉,比如说html和简单的js和web框架什么的。现在我们用Python爬取租房网站信息,来学习pyhton。
猪短租是一个租房网站,上面有很多优质的民宿出租信息,下面我们以成都地区的租房信息为例,来尝试爬取这些数据。
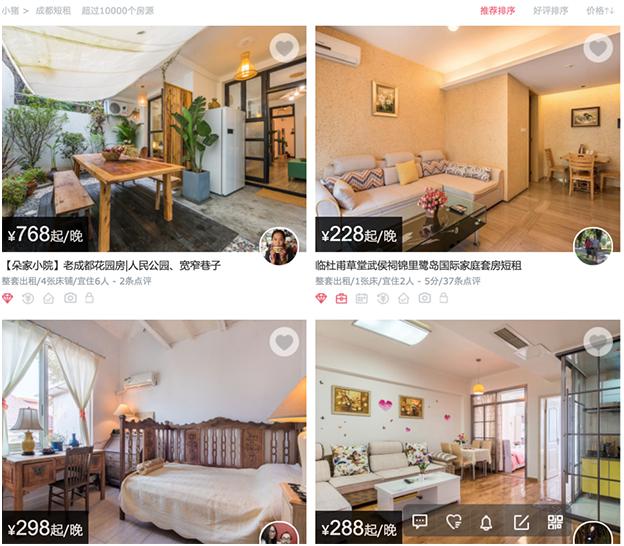
1.爬取租房标题
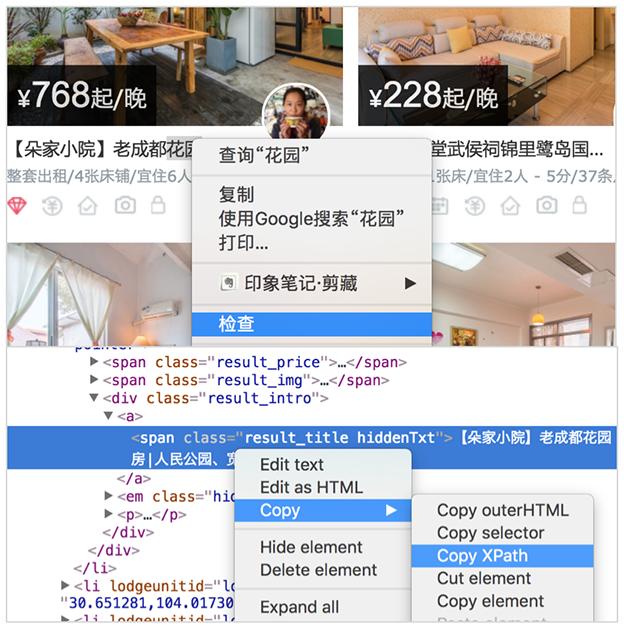
按照惯例,先来爬下标题试试水,找到标题,复制xpath。
多复制几个房屋的标题 xpath 进行对比:
//*[@id="page_list"]/ul/li[1]/div[2]/div/a/span
//*[@id="page_list"]/ul/li[2]/div[2]/div/a/span
//*[@id="page_list"]/ul/li[3]/div[2]/div/a/span
瞬间发现标题的 xpath 只在
· 后序号变化,于是,秒写出爬取整页标题的 xpath:
//*[@id=“page_list”]/ul/li/div[2]/div/a/span
·1
还是固定的套路,让我们尝试把整页的标题爬下来:
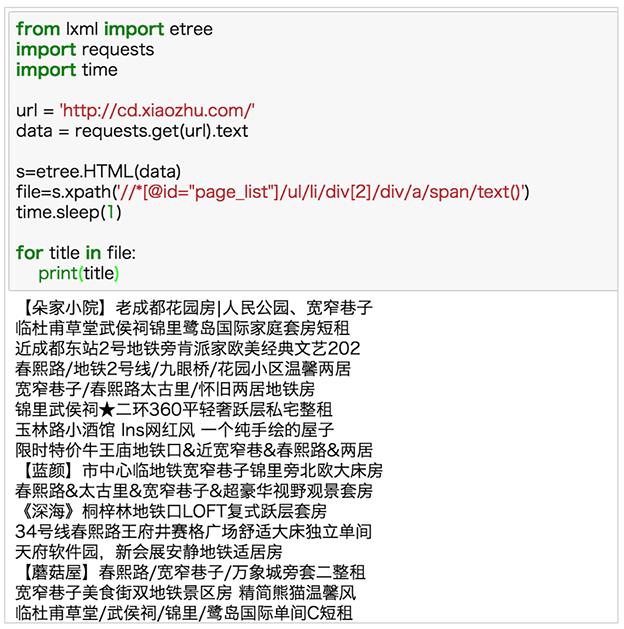
小猪在IP限制方面比较严格,代码中务必要加入 sleep() 函数控制爬取的频率

好了,再来对比下 xpath 信息
顺着标题的标签网上找,找到整个房屋信息标签, xpath 对比如下:
//*[@id=“page_list”]/ul/li #整体
//*[@id=“page_list”]/ul/li/div[2]/div/a/span #标题
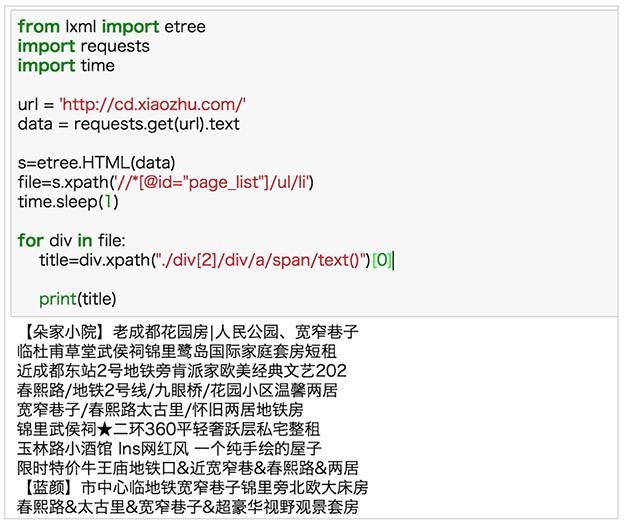
你应该知道该怎么来改代码了吧,写一个循环:
file=s.xpath(‘//*[@id=“page_list”]/ul/li’)
for div in file:
title=div.xpath("./div[2]/div/a/span/text()")[0]
好了,来运行一下试试:
2.爬取多个元素的信息
对比其他元素的 xpath:
//*[@id=“page_list”]/ul/li #整体
//*[@id=“page_list”]/ul/li/div[2]/div/a/span #标题
//*[@id=“page_list”]/ul/li/div[2]/span[1]/i #价格
//*[@id=“page_list”]/ul/li/div[2]/div/em #描述
//*[@id=“page_list”]/ul/li/a/img #图片
然后可以写出代码:
file=s.xpath(“//*[@id=“page_list”]/ul/li”)
for div in file:
title=div.xpath(“./div[2]/div/a/span/text()”)[0]
price=div.xpath(“./div[2]/span[1]/i/text()”)[0]
scrible=div.xpath(“./div[2]/div/em/text()”)[0].strip()
pic=div.xpath(“./a/img/@lazy_src”)[0]
来尝试运行一下:
3.翻页,爬取更多页面
看一下翻页时候 url 的变化:

http://cd.xiaozhu.com/search-duanzufang-p1-0/ #第一页
http://cd.xiaozhu.com/search-duanzufang-p2-0/ #第二页
http://cd.xiaozhu.com/search-duanzufang-p3-0/ #第三页
http://cd.xiaozhu.com/search-duanzufang-p4-0/ #第四页
……………………
url 变化的规律很简单,只是 p 后面的数字不一样而已,而且跟页码的序号是一模一样的,这就很好办了……写一个简单的循环来遍历所有的url。
for a in range(1,6):
url = ‘http://cd.xiaozhu.com/search-duanzufang-p{}-0/’.format(a)
# 我们这里尝试5个页面,你可以根据自己的需求来写爬取的页面数量
完整的代码如下:
from lxml import etree
import requests
import time
for a in range(1,6):
url = 'http://cd.xiaozhu.com/search-duanzufang-p{}-0/'.format(a)
data = requests.get(url).text
s=etree.HTML(data)
file=s.xpath('//*[@id="page_list"]/ul/li')
time.sleep(3)
for div in file:
title=div.xpath("./div[2]/div/a/span/text()")[0]
price=div.xpath("./div[2]/span[1]/i/text()")[0]
scrible=div.xpath("./div[2]/div/em/text()")[0].strip()
pic=div.xpath("./a/img/@lazy_src")[0]
print("{} {} {} {} ".format(title,price,scrible,pic))
看一下爬了5个页面下来的效果:

相信你已经掌握爬虫基本的套路了,但你还需要去不断熟悉,能独立写出代码为止。
写代码不仅要细心,也需要耐心。很多人从入门到放弃,并不是因为编程这件事情有多难,而是某次实践过程中,遇到一个小问题。
下面我们再来爬取300个房源信息
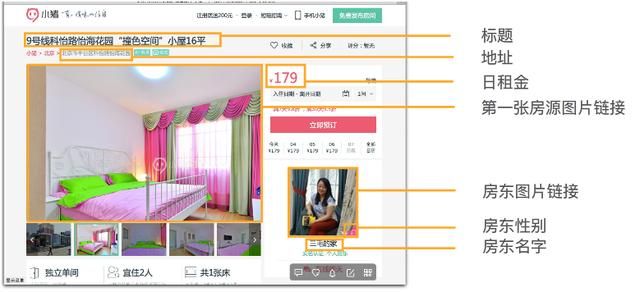
爬取网页上300个房源信息,包括标题,地址,日租金,第一张房源图片链接,房东图片链接,房东性别,房东名字

代码
from bs4 import BeautifulSoup
import requests
# 判断性别
def get_sex(sex_icon):
if sex_icon == ['member_ico']:
return "男"
if sex_icon == ['member_ico1']:
return "女"
else:
return "未标识"
# 获取每页的url链接
def get_page_url(url):
web_url = requests.get(url)
web_url_soup = BeautifulSoup(web_url.text,'lxml')
page_urls = web_url_soup.select('#page_list > ul > li > a')
for page_url in page_urls:
each_url = page_url.get('href')
get_detail_info(each_url)
def get_detail_info(url):
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text,'lxml')
titles = soup.select('body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > h4 > em')
addresses = soup.select('body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > p > span.pr5')
prices = soup.select('#pricePart > div.day_l > span')
pics1 = soup.select('#curBigImage')
owner_pics = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > a > img')
owner_names = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h6 > a')
sexes = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > div')
for title, address, price, pic1, owner_name, owner_pic, sex in zip(titles, addresses, prices, pics1, owner_names,
owner_pics, sexes):
data = {
'title': title.get_text(),
'address': address.get_text(),
'price': price.get_text(),
'pic': pic1.get('src'),
'owner_pic': owner_pic.get('src'),
'name': owner_name.get('title'),
'sex': get_sex(sex.get('class'))
}
print (data)
urls = ["http://bj.xiaozhu.com/search-duanzufang-p{}-0/".format(number) for number in range(1, 10)]
for url in urls:
get_page_url(url)
成果
{'name': '想要', 'address': '北京市朝阳区望京利泽西园 ', 'price': '395', 'owner_pic': 'http://image.xiaozhustatic1.com/21/5,0,44,1477,329,329,ea609ac8.jpg', 'title': '望京华彩十四号线精美豪华大一居', 'sex': '未标识', 'pic': 'http://image.xiaozhustatic1.com/00,800,533/6,0,39,2965,1800,1200,f17d1a3e.jpg'}
{'name': '暖阳洋Sunny', 'address': '北京市朝阳区彩虹路 ', 'price': '798', 'owner_pic': 'http://image.xiaozhustatic1.com/21/2,0,86,206,375,375,d46c51ef.jpg', 'title': '紧邻798、望京、酒仙桥,精品大三居。', 'sex': '未标识', 'pic': 'http://image.xiaozhustatic1.com/00,800,533/3,0,34,2819,1800,1200,e051c333.jpg'}
{'name': '小小西红柿', 'address': '北京市丰台区六里桥太平桥西里40号 ', 'price': '368', 'owner_pic': 'http://image.xiaozhustatic1.com/21/6,0,72,1777,260,260,887558a2.jpg', 'title': '临近 北京西站 距电力医院3分钟 两居', 'sex': '女', 'pic': 'http://image.xiaozhustatic1.com/00,800,533/6,0,28,4451,1800,1200,e3bb1749.jpg'}
{'name': '想要', 'address': '北京市朝阳区广顺北大街利泽西园 ', 'price': '395', 'owner_pic': 'http://image.xiaozhustatic1.com/21/5,0,44,1477,329,329,ea609ac8.jpg', 'title': '望京商圈,毗邻地铁5分钟,漫威主题大两居', 'sex': '未标识', 'pic': 'http://image.xiaozhustatic1.com/00,800,533/6,0,66,803,1800,1200,38a4c686.jpg'}
{'name': '最美好的时光遇到你', 'address': '北京市朝阳区小关北里 ', 'price': '218', 'owner_pic': 'http://image.xiaozhustatic1.com/21/4,0,84,10730,260,260,6d756363.jpg', 'title': '惠新西街南口阳光大主卧', 'sex': '女', 'pic': 'http://image.xiaozhustatic1.com/00,800,533/5,0,47,2122,1800,1200,8830e613.jpg'}
{'name': '暖阳洋Sunny', 'address': '北京市朝阳区彩虹路 ', 'price': '268', 'owner_pic': 'http://image.xiaozhustatic1.com/21/2,0,86,206,375,375,d46c51ef.jpg', 'title': '独立卫浴邻798、望京、酒仙桥更多优惠房源。', 'sex': '未标识', 'pic': 'http://image.xiaozhustatic1.com/00,800,533/2,0,71,458,1800,1200,a9c5ea82.jpg'}
{'name': '阳光艳艳', 'address': '北京市朝阳区苹果社区北区 ', 'price': '398', 'owner_pic': 'http://image.xiaozhustatic1.com/21/5,0,59,2841,363,363,8b6cf3d7.jpg', 'title': '国贸双井10号线苹果酒店式公寓', 'sex': '女', 'pic': 'http://image.xiaozhustatic1.com/00,800,533/6,0,25,3184,1800,1200,4b993d38.jpg'}
{'name': '兰花姐', 'address': '北京市朝阳区十里河左安东路弘善家园 ', 'price': '279', 'owner_pic': 'http://image.xiaozhustatic1.com/21/4,0,2,9806,329,329,4656b7f6.jpg', 'title': '潘家园十里河地铁十号十四号临近国贸', 'sex': '女', 'pic': 'http://image.xiaozhustatic1.com/00,800,533/6,0,83,2043,1800,1200,cc659348.jpg'}
{'name': 'Alicejy', 'address': '北京市朝阳区望京南湖中园 ', 'price': '195', 'owner_pic': 'http://image.xiaozhustatic1.com/21/6,0,3,3065,160,160,ba886bf8.jpg', 'title': '望京亲水微豪庭,独享奢华对望东湖湾', 'sex': '女', 'pic': 'http://image.xiaozhustatic1.com/00,800,533/6,0,62,3156,1800,1200,7d5aa8bc.jpg'}
{'name': '小肖肖', 'address': '北京市东城区南锣鼓巷 ', 'price': '158', 'owner_pic': 'http://image.xiaozhustatic1.com/21/5,0,55,1517,260,260,ea96ce11.jpg', 'title': '南锣鼓巷0距离,鼓楼、后海、故宫、簋街', 'sex': '女', 'pic': 'http://image.xiaozhustatic1.com/00,800,533/1,0,53,2309,825,550,5a3a9a34.jpg'}
{'name': '豹子楠', 'address': '北京市西城区高粱桥斜街长河湾 ', 'price': '398', 'owner_pic': 'http://image.xiaozhustatic1.com/21/1,0,8,5386,333,333,764cfdb4.jpg', 'title': '西直门 长河湾 韩式田园温馨2居', 'sex': '女', 'pic': 'http://image.xiaozhustatic1.com/00,800,533/1,0,3,5482,825,550,f874984d.jpg'}
{'name': '幸福姐姐', 'address': '北京市朝阳区红军营南路 ', 'price': '128', 'owner_pic': 'http://image.xiaozhustatic1.com/21/1,0,93,4699,375,375,f8bc8f9b.jpg', 'title': '北五环5.13号地铁高档的温馨公寓', 'sex': '女', 'pic': 'http://image.xiaozhustatic1.com/00,800,533/1,0,42,4845,825,550,57c0343f.jpg'}
{'name': 'Rolling_meng', 'address': '北京市朝阳区劲松华腾园 ', 'price': '318', 'owner_pic': 'http://image.xiaozhustatic1.com/21/5,0,96,1555,375,375,ea000c2a.jpg', 'title': '10号线劲松/双井/国贸CBD采光舒适大一居', 'sex': '男', 'pic': 'http://image.xiaozhustatic1.com/00,800,533/6,0,40,333,1800,1200,c8e516a7.jpg'}
{'name': '啵妞的家', 'address': '北京市朝阳区十里堡润枫嘉尚 ', 'price': '338', 'owner_pic': 'http://image.xiaozhustatic1.com/21/1,0,33,4216,366,366,c589a192.jpg', 'title': '6号线地铁公寓', 'sex': '女', 'pic': 'http://image.xiaozhustatic1.com/00,800,533/6,0,60,2088,1800,1200,3b057da1.jpg'}
好了,今天的知识就分享到这里,如果文章对你有有帮助,请收藏关注,在今后与你分享更多学习python的文章。同时欢迎在下面评论区留言如何学习python。