Elastic Stack日志查询平台第一篇:快速开始
本文最初发表在我的个人博客,查看原文。
本文会带你了解:
- Elastic Stack 可以干什么
- Elastic Stack 有哪些核心产品
- 为什么要搭建日志查询平台
- 如何快速搭建一个日志查询平台
Elastic Stack系列文章链接:
Elastic Stack日志查询平台第一篇:快速开始
Elastic Stack日志查询平台第二篇:Elasticsearch生产配置
本文是 Elastic Stack 日志查询平台系列的第一篇。后续我会分章节记录如何在生产环境构建一个日志查询平台。
一 简介
Elastic Stack 是应对多种搜索场景的一站式解决方案。主要产品包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。其中Beats 平台集合了多种单一用途数据采集器。它们可以从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。目前对各个平台支持的都比较好,主流的OS基本都支持,另外容器环境也是支持的,如Docker/K8S等。
其中 Beats 平台产品模块又包括 Filebeat,Metricbeat,Packetbeat,Winlogbeat,Auditbeat,Heartbeat,Functionbeat。
本系列文章主要使用其中的 Filebeat 模块作为日志采集器,因为 Filebeat 足够小巧和轻量,非常适合作为 agent 部署在目标服务器上。老牌的 Logstash(ELK中的“L”)同样也可以完成日志采集工作,但在过去的日子里由于性能和资源占用问题,现在已经慢慢退出日志采集工作,主要负责日志的二次加工处理工作。
本文将选用其中的 Elasticsearch、Kibana、以及 Beats 平台中的 Filebeat 进行介绍(即EFK)。其中 Elasticsearch 用于日志的索引及搜索,Kibana用于结果展示,Filebeat 用于日志采集。
二 环境要求
1. 操作系统:
本系列文章全部在CentOS 7以及Ubuntu Server 18.04上验证过。
2. JVM:
由于 Elasticsearch 是一个Java应用,所以需要一个Java运行环境,Elasticsearch 自身已经集成了一个JDK(OpenJDK 13)随发行版一起发布,推荐使用集成的就好了,如果你仍坚持想使用自己系统上已有的JDK,没关系,只需要在环境变量中配置一个JAVA_HOME变量即可,需要注意的是Elasticsearch要求JDK最低版本为8。另外,官方推荐使用长期支持版本(LTS)的发行版,像Java9,10,12这些短期发行版本不推荐使用。
参见详细平台支持列表。
3. 系统用户:
部分配置文件对权限要求很严格,除非特别说明,本文假设所有操作均使用具有sudo权限的devops用户。
三 下载安装
本系列文章所采用的Elastic Stack版本为7.4.1(7.4.x),如果你也想跟我一起搭建这个平台,请确保版本一致。
3.1 安装及启动顺序
务必按以下顺序安装并启动各个服务:
- Elasticsearch
- Kibana
- Filebeat
3.2 Elasticsearch
Elasticsearch是一个实时的分布式存储,搜索和分析引擎。它可以用于多种目的,但它擅长的一种场景是索引半结构化数据流,例如日志或解码的网络数据包。Elasticsearch使用称为倒排索引的数据结构,该结构支持非常快速的全文本搜索。
1. 下载
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.1-linux-x86_64.tar.gz
tar -zxvf elasticsearch-7.4.1-linux-x86_64.tar.gz
cd elasticsearch-7.4.1
解压后的目录elasticsearch-7.4.1我们称为$ES_HOME
Elastic Stack产品很多配置选项都提供了默认值,对于初次接触的用户很容易上手。
2. 启动
./bin/elasticsearch
默认情况下,Elasticsearch 运行在前台,要以后台进程运行,执行以下命令:
./bin/elasticsearch -d
3. 检查服务
我们可以使用以下命令测试一下服务是否运行起来:
curl http://127.0.0.1:9200
Elasticsearch 默认监听
9200及9300端口,请确认端口可用。
正常的话会返回以下内容:
{
"name" : "devServer1",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "7bThQB_TTWOHnQ70Jt6I6g",
"version" : {
"number" : "7.4.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "fc0eeb6e2c25915d63d871d344e3d0b45ea0ea1e",
"build_date" : "2019-10-22T17:16:35.176724Z",
"build_snapshot" : false,
"lucene_version" : "8.2.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
4. 结束进程
前台运行的话,直接按Ctrl+C即可。后台运行的话,先查找进程ID,再kill掉即可:
ps -ef |grep Elastic
kill -15 pid
3.3 Kibana
Kibana是一个开源的数据可视化平台,与 Elasticsearch 一起,完成数据的搜索,展示及分析等。
推荐将Kibana与 Elasticsearch 安装在同一台服务器上,但这不是必须的,如果你将其安装在另一台服务器,请确保修改配置文件中的URL地址。
1. 下载
curl -L -O https://artifacts.elastic.co/downloads/kibana/kibana-7.4.1-linux-x86_64.tar.gz
tar -zxvf kibana-7.4.1-linux-x86_64.tar.gz
cd kibana-7.4.1-linux-x86_64/
2. 启动
如果你不是在本地运行的,请先修改config/kibana.yml配置文件,找到#server.host: "localhost"一行,将前面的注释去掉,并将localhost修改为实际的IP地址,如192.168.0.132。
./bin/kibana
Kibana默认监听5601端口,确保端口可用。
3. 查看
Kibana默认监听本地5601端口,打开地址http://127.0.0.1:5601查看。如果你不是在本地运行的,修改为实际的IP地址,如192.168.0.132。:
由于默认没有启用鉴权,所以打开后直接就可以进入首页了。
4. 结束
按Ctrl+C即可。
Kibana默认也是运行在前台,但是官方并未提供后台运行的方案,所以只能按照普通的脚本来处理了,我们可以使用以下命令让其在后台运行:
mkdir -p logs && \
nohup ./bin/kibana >> logs/kibana.log 2>&1 &
该命令运行成功后会返回进程的ID:
[1] 4370
如果后续找不到该ID,或者忘记了,很简单,只需要查看一下日志既可以了,日志中会记录下这个pid:
tail -n1 logs/kibana.log
日志是JSON格式,在结果中找到pid字段对应的值就是Kibana的PID,例如下面的第4个字段:
“pid”:4370
{"type":"log","@timestamp":"2019-11-24T08:38:39Z","tags":["warning","telemetry"],"pid":4370,"message":"Error scheduling task, received [task:oss_telemetry-vis_telemetry]: version conflict, document already exists (current version [3]): [version_conflict_engine_exception] [task:oss_telemetry-vis_telemetry]: version conflict, document already exists (current version [3]), with { index_uuid=\"29HpkrjHTzylpGl7-zR0mA\" & shard=\"0\" & index=\".kibana_task_manager_1\" }"}
找到后kill就可以结束该进程了。
如果你的服务器上没有node.js应用,还可以使用
ps -ef |grep bin/node查找PID。
3.4 Filebeat
Filebeat 是Beats家族中的一员。用于采集各种日志文件,它足够小巧,轻量,简单,可以作为agent安装在服务上。Filebeat 内置有多种模块(auditd、Apache、NGINX、System、MySQL 等等),可针对常见格式的日志大大简化收集、解析和可视化过程,只需一条命令即可。
Filebeat 运行的前提是 Elasticsearch 和Kibana已经运行起来。
1. 下载
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.4.1-linux-x86_64.tar.gz
tar -zxvf filebeat-7.4.1-linux-x86_64.tar.gz
cd filebeat-7.4.1-linux-x86_64
2. 准备日志收集目录
假设以下目录是我们的日志存放的目录:
sudo mkdir -p /opt/data/my-app1-log && \
sudo chown devops:devops /opt/data/my-app1-log
注意权限,将devops用户替换为你实际要运行Filebeat的用户。
3. 准备一些测试日志
编辑/opt/data/my-app1-log/app.log并存入以下示例日志内容:
2019-10-06 11:40:36.652 INFO http-bio-10009-exec-302 - start someMethod for some params
2019-10-06 11:40:36.652 INFO http-bio-10009-exec-302 - getUser for someField null,paramId 1111
2019-10-06 11:40:36.653 DEBUG http-bio-10009-exec-302 - ooo Using Connection [com.alibaba.druid.proxy.jdbc.ConnectionProxyImpl@5f324b3c]
2019-10-06 11:40:36.653 DEBUG http-bio-10009-exec-302 - ==> Preparing: select * from t_user where login_name=?
2019-10-06 11:40:36.653 DEBUG http-bio-10009-exec-302 - ==> Parameters: 18888888888(String)
2019-10-06 11:40:37.254 INFO http-bio-10009-exec-302 - Filtering response of path: /some/controller/path
2019-10-06 11:40:37.254 INFO http-bio-10009-exec-308 - Filtering request of path: /some/controller/path
2019-10-06 11:40:37.254 INFO http-bio-10009-exec-308 - init session with something=,xxxxxxxx,userId=1234
2019-10-06 11:40:37.254 INFO http-bio-10009-exec-308 - start someMethod for some params
2019-10-06 11:40:37.255 INFO http-bio-10009-exec-308 - getUser for someField null,paramId 2222
2019-10-06 11:40:37.255 DEBUG http-bio-10009-exec-308 - ooo Using Connection [com.alibaba.druid.proxy.jdbc.ConnectionProxyImpl@5f324b3c]
2019-10-06 11:40:37.255 DEBUG http-bio-10009-exec-308 - ==> Preparing: select * from t_user where login_name=?
2019-10-06 11:40:37.255 DEBUG http-bio-10009-exec-308 - ==> Parameters: 19999999999(String)
2019-10-06 11:40:37.262 INFO http-bio-10009-exec-171 - Filtering request of path: /some/controller/path
2019-10-06 11:40:37.262 INFO http-bio-10009-exec-171 - init session with something=,xxxxxxxx,userId=1256
2019-10-06 11:40:37.262 INFO http-bio-10009-exec-171 - Filtering response of path: /some/controller/path
2019-10-06 11:40:37.262 INFO http-bio-10009-exec-308 - Filtering response of path: /another/controller/path
2019-10-06 11:40:37.263 INFO http-bio-10009-exec-135 - Filtering request of path: /another/controller/path
2019-10-06 11:40:37.263 INFO http-bio-10009-exec-135 - init session with something=,xxxxxxxx,userId=5678
2019-10-06 11:40:37.277 DEBUG http-bio-10009-exec-135 - ooo Using Connection [com.alibaba.druid.proxy.jdbc.ConnectionProxyImpl@5f324b3c]
2019-10-06 11:40:37.277 DEBUG http-bio-10009-exec-135 - ==> Preparing: select a.* from sometable a where a.user_id = ?
2019-10-06 11:40:37.277 DEBUG http-bio-10009-exec-135 - ==> Parameters: 5678(Long)
2019-10-06 11:40:37.277 INFO http-bio-10009-exec-135 - Filtering response of path: /another/controller/path
这是一段典型的Java应用日志输出示例。
4. 配置输入源
vi filebeat.yml,
在开头Filebeat inputs部分找到以下片段:
- type: log
# Change to true to enable this input configuration.
enabled: false
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/*.log
将enabled的值修改为true,并将paths下的内容修改为如下所示:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /opt/data/my-app1-log/*.log
你也可以将该路径指向你的应用日志目录。
保存退出。
这里指定日志采集器的类型是log,路径就是我们上一步创建的路径。
5. 测试配置
可以使用test命令对修改后的配置进行一个测试,确保没有问题。
./filebeat test config -e
如果没有问题的话最后会输出Config OK字样。
6. 启动
./filebeat -e
其中
-e参数表示将Filebeat本身的日志输出到标准错误中,并关闭syslog/file的输出。
同样,Filebeat官方也没有提供后台运行的方法,使用以下命令让它在后台运行:
nohup ./filebeat > /dev/null 2>&1 &
要结束的话,如果是前台运行,按Ctrl+C即可。如果是后台运行,使用以下命令查找PID,然后kill即可。
ps -ef |grep filebeaet
kill -15 pid
没问题的话,会看到以下内容输出(部分):
2019-11-24T18:17:07.729+0800 INFO instance/beat.go:292 Setup Beat: filebeat; Version: 7.4.1
2019-11-24T18:17:07.729+0800 INFO [index-management] idxmgmt/std.go:178 Set output.elasticsearch.index to 'filebeat-7.4.1' as ILM is enabled.
2019-11-24T18:17:07.729+0800 INFO elasticsearch/client.go:170 Elasticsearch url: http://localhost:9200
2019-11-24T18:17:07.730+0800 INFO [publisher] pipeline/module.go:97 Beat name: devServer1
2019-11-24T18:17:07.730+0800 INFO [monitoring] log/log.go:118 Starting metrics logging every 30s
2019-11-24T18:17:07.730+0800 INFO instance/beat.go:422 filebeat start running.
2019-11-24T18:17:07.730+0800 INFO registrar/registrar.go:145 Loading registrar data from /var/lib/filebeat-7.4.1-linux-x86_64/data/registry/filebeat/data.json
2019-11-24T18:17:07.730+0800 INFO registrar/registrar.go:152 States Loaded from registrar: 0
2019-11-24T18:17:07.730+0800 INFO crawler/crawler.go:72 Loading Inputs: 1
2019-11-24T18:17:07.730+0800 INFO log/input.go:152 Configured paths: [/opt/data/my-app1-log/*.log]
2019-11-24T18:17:07.735+0800 INFO input/input.go:114 Starting input of type: log; ID: 6209541038125597693
2019-11-24T18:17:07.735+0800 INFO crawler/crawler.go:106 Loading and starting Inputs completed. Enabled inputs: 1
2019-11-24T18:17:07.735+0800 INFO cfgfile/reload.go:171 Config reloader started
2019-11-24T18:17:07.735+0800 INFO cfgfile/reload.go:226 Loading of config files completed.
2019-11-24T18:17:07.736+0800 INFO log/harvester.go:251 Harvester started for file: /opt/data/my-app1-log/app.log
2019-11-24T18:17:10.729+0800 INFO add_cloud_metadata/add_cloud_metadata.go:87 add_cloud_metadata: hosting provider type not detected.
2019-11-24T18:17:11.729+0800 INFO pipeline/output.go:95 Connecting to backoff(elasticsearch(http://localhost:9200))
2019-11-24T18:17:11.825+0800 INFO elasticsearch/client.go:743 Attempting to connect to Elasticsearch version 7.4.1
2019-11-24T18:17:11.866+0800 INFO [index-management] idxmgmt/std.go:252 Auto ILM enable success.
2019-11-24T18:17:12.018+0800 INFO [index-management] idxmgmt/std.go:265 ILM policy successfully loaded.
2019-11-24T18:17:12.018+0800 INFO [index-management] idxmgmt/std.go:394 Set setup.template.name to '{filebeat-7.4.1 {now/d}-000001}' as ILM is enabled.
2019-11-24T18:17:12.018+0800 INFO [index-management] idxmgmt/std.go:399 Set setup.template.pattern to 'filebeat-7.4.1-*' as ILM is enabled.
2019-11-24T18:17:12.018+0800 INFO [index-management] idxmgmt/std.go:433 Set settings.index.lifecycle.rollover_alias in template to {filebeat-7.4.1 {now/d}-000001} as ILM is enabled.
2019-11-24T18:17:12.018+0800 INFO [index-management] idxmgmt/std.go:437 Set settings.index.lifecycle.name in template to {filebeat-7.4.1 {"policy":{"phases":{"hot":{"actions":{"rollover":{"max_age":"30d","max_size":"50gb"}}}}}}} as ILM is enabled.
2019-11-24T18:17:12.019+0800 INFO template/load.go:169 Existing template will be overwritten, as overwrite is enabled.
2019-11-24T18:17:12.125+0800 INFO template/load.go:108 Try loading template filebeat-7.4.1 to Elasticsearch
2019-11-24T18:17:12.332+0800 INFO template/load.go:100 template with name 'filebeat-7.4.1' loaded.
2019-11-24T18:17:12.332+0800 INFO [index-management] idxmgmt/std.go:289 Loaded index template.
2019-11-24T18:17:13.870+0800 INFO [index-management] idxmgmt/std.go:300 Write alias successfully generated.
2019-11-24T18:17:13.870+0800 INFO pipeline/output.go:105 Connection to backoff(elasticsearch(http://localhost:9200)) established
可以看到Filebeat检测到了一个日志输入并立即开始采集该日志:
2019-11-24T18:17:07.730+0800 INFO crawler/crawler.go:72 Loading Inputs: 1
2019-11-24T18:17:07.730+0800 INFO log/input.go:152 Configured paths: [/opt/data/my-app1-log/*.log]
2019-11-24T18:17:07.735+0800 INFO input/input.go:114 Starting input of type: log; ID: 6209541038125597693
2019-11-24T18:17:07.735+0800 INFO crawler/crawler.go:106 Loading and starting Inputs completed. Enabled inputs: 1
2019-11-24T18:17:07.735+0800 INFO cfgfile/reload.go:171 Config reloader started
2019-11-24T18:17:07.735+0800 INFO cfgfile/reload.go:226 Loading of config files completed.
2019-11-24T18:17:07.736+0800 INFO log/harvester.go:251 Harvester started for file: /opt/data/my-app1-log/app.log
2019-11-24T18:17:10.729+0800 INFO add_cloud_metadata/add_cloud_metadata.go:87 add_cloud_metadata: hosting provider type not detected.
2019-11-24T18:17:11.729+0800 INFO pipeline/output.go:95 Connecting to backoff(elasticsearch(http://localhost:9200))
2019-11-24T18:17:11.825+0800 INFO elasticsearch/client.go:743 Attempting to connect to Elasticsearch version 7.4.1
采集的日志接着被发送到了 Elasticsearch 中,以下是ElasticSearch的部分日志:
[2019-11-24T18:17:12,359][INFO ][o.e.c.m.MetaDataCreateIndexService] [devServer1] [filebeat-7.4.1-2019.11.24-000001] creating index, cause [api], templates [filebeat-7.4.1], shards [1]/[1], mappings [_doc]
四 数据展示及搜索
经过前面的操作以后,现在文件中的日志已经被发送到了 Elasticsearch 中。现在我们就可以检索我们的日志了。
4.1 创建索引模式
打开Kibana页面,点击菜单 Management >> Index Patterns,然后点击页面上的Create index pattern,在Index pattern输入框中输入filebeat-*关键字,当提示Success! Your index pattern matches 1 index.时,我们点击Next step:
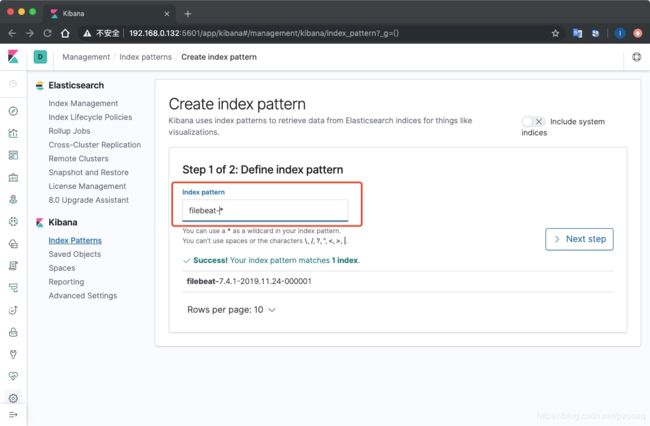
然后在Time Filter field name下拉列表中选择@timestamp作为时间过滤字段,最后点击Create index pattern按钮,稍等几秒,完成索引模式创建。
4.2 查询日志
索引模式创建完成后,现在终于可以查询日志了。点击左侧菜单Discover,进入查询页面,当前页面默认查询过去15分钟的日志,如果你的页面显示没有查到任何东西,请调整一下时间段,比如将时间改为查找今天,然后就能查到内容了:
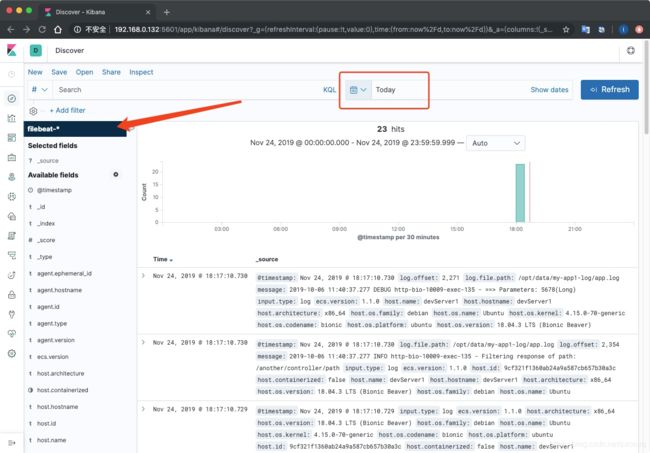
你也可以试着在输入框输入日志中出现的某个关键字进行搜索,搜索结果会高亮显示。
五 最后
到此,我们的日志查询平台就算告一段落了。可以看到,我们将日志从应用节点采集汇总到了 Elasticsearch 中,然后可以通过 Kibana 进行各种检索,这比登录到服务器上使用tail,cat,grep等命令方便多了,重要的是,Elastic Stack可以将你的多个应用的多个节点产生的日志聚合到一块,方便检索和分析。
接下来,我们需要看看还有哪些配置需要注意,以及如何满足在生产环境中的需要。
参考:
- Getting started with the Elastic Stack。
- Getting Started With Filebeat。