EFK家族---Elasticsearch介绍
转载请注明出处:EFK家族—Elasticsearch介绍
介绍
ElasticSearch是一个基于Apache Lucene™的开源搜索引擎。它基于RESTful web接口提供了一个分布式多用户能力的全文搜索引擎。
Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级全文搜索引擎,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
官网
源码github
Elasticsearch中文社区
docker镜像
ElasticSearch的诞生和作用
无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
不过,Elasticsearch不仅仅是Lucene和全文搜索,我们还能这样去描述它:
分布式的实时文件存储,每个字段都被索引并可被搜索
分布式的实时分析搜索引擎
可以扩展到上百台服务器,处理PB级结构化或非结构化数据
而且,所有的这些功能被集成到一个服务里面,你的应用可以通过简单的RESTful API、各种语言的客户端甚至命令行与之交互。
上手Elasticsearch非常容易。它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它开箱即用(安装即可使用),只需很少的学习既可在生产环境中使用。
总结如下:
Elastic Search
简称 ES
设计用途 用于分布式全文检索
技术支持 通过HTTP使用JSON进行数据索引
主要目的 解决人们对于搜索的众多要求
关于Lucene
基于Java的全文索引/检索引擎——Lucene
Lucene不是一个完整的全文索引应用,而是是一个用Java写的全文索引引擎工具包,它可以方便的嵌入到各种应用中实现针对应用的全文索引/检索功能。
Lucene的作者:Lucene的贡献者Doug Cutting是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎(Apple的Copland操作系统的成就之一)的主要开发者,后在Excite担任高级系统架构设计师,目前从事于一些INTERNET底层架构的研究。他贡献出的Lucene的目标是为各种中小型应用程序加入全文检索功能。
Lucene的发展历程:早先发布在作者自己的www.lucene.com,后来发布在SourceForge,2001年年底成为APACHE基金会jakarta的一个子项目:http://jakarta.apache.org/lucene/
已经有很多Java项目都使用了Lucene作为其后台的全文索引引擎,比较著名的有:
Jive:WEB论坛系统;
Eyebrows:邮件列表HTML归档/浏览/查询系统,EyeBrows已经成为目前APACHE项目的主要邮件列表归档系统。
Cocoon:基于XML的web发布框架,全文检索部分使用了Lucene
Eclipse:基于Java的开放开发平台,帮助部分的全文索引使用了Lucene
全文检索的实现机制
Lucene的API接口设计的比较通用,输入输出结构都很像数据库的表==>记录==>字段,所以很多传统的应用的文件、数据库等都可以比较方便的映射到Lucene的存储结构/接口中。总体上看:可以先把Lucene当成一个支持全文索引的数据库系统。
建立一个高效检索系统的关键是建立一个类似于科技索引一样的反向索引机制,将数据源(比如多篇文章)排序顺序存储的同时,有另外一个排好序的关键词列表,用于存储关键词==>文章映射关系,利用这样的映射关系索引:[关键词==>出现关键词的文章编号,出现次数(甚至包括位置:起始偏移量,结束偏移量),出现频率],检索过程就是把模糊查询变成多个可以利用索引的精确查询的逻辑组合的过程。从而大大提高了多关键词查询的效率,所以,全文检索问题归结到最后是一个排序问题。
对于检索系统来说核心是一个排序问题。
与普通数据库的区别
由于数据库索引不是为全文索引设计的,因此,使用like “%keyword%“时,数据库索引是不起作用的,在使用like查询时,搜索过程又变成类似于一页页翻书的遍历过程了,所以对于含有模糊查询的数据库服务来说,LIKE对性能的危害是极大的。如果是需要对多个关键词进行模糊匹配:like”%keyword1%” and like “%keyword2%” …其效率极低。
因为模糊查询的效率低下,大部分数据库对全文检索支持有限。
Lucene最核心的特征是通过特殊的索引结构实现了传统数据库不擅长的全文索引机制,并提供了扩展接口,以方便针对不同应用的定制。
| Lucene全文索引引擎 | 数据库 | |
|---|---|---|
| 索引 | 将数据源中的数据都通过全文索引一一建立反向索引 | 对于LIKE查询来说,数据传统的索引是根本用不上的。数据需要逐个便利记录进行GREP式的模糊匹配,比有索引的搜索速度要有多个数量级的下降。 |
| 匹配效果 | 通过词元(term)进行匹配,通过语言分析接口的实现,可以实现对中文等非英语的支持。 | 使用:like “%net%” 会把netherlands也匹配出来,多个关键词的模糊匹配:使用like “%com%net%”:就不能匹配词序颠倒的xxx.net…xxx.com |
| 匹配度 | 有匹配度算法,将匹配程度(相似度)比较高的结果排在前面。 | 没有匹配程度的控制:比如有记录中net出现5词和出现1次的,结果是一样的。 |
| 结果输出 | 通过特别的算法,将最匹配度最高的头100条结果输出,结果集是缓冲式的小批量读取的。 | 返回所有的结果集,在匹配条目非常多的时候(比如上万条)需要大量的内存存放这些临时结果集。 |
| 可定制性 | 通过不同的语言分析接口实现,可以方便的定制出符合应用需要的索引规则(包括对中文的支持) | 没有接口或接口复杂,无法定制 |
| 结论 | 高负载的模糊查询应用,需要负责的模糊查询的规则,索引的资料量比较大 | 使用率低,模糊匹配规则简单或者需要模糊查询的资料量少 |
全文检索和数据库应用最大的不同在于:让最相关的头100条结果满足98%以上用户的需求
Lucene的创新之处
大部分的搜索(数据库)引擎都是用B树结构来维护索引,索引的更新会导致大量的IO操作,Lucene在实现中,对此稍微有所改进:不是维护一个索引文件,而是在扩展索引的时候不断创建新的索引文件,然后定期的把这些新的小索引文件合并到原先的大索引中(针对不同的更新策略,批次的大小可以调整),这样在不影响检索的效率的前提下,提高了索引的效率。
Lucene和其他一些全文检索系统/应用的比较:
| Lucene | 其他开源全文检索系统 | |
|---|---|---|
| 增量索引和批量索引 | Lucene 其他开源全文检索系统增量索引和批量索引 可以进行增量的索引(Append),可以对于大量数据进行批量索引,并且接口设计用于优化批量索引和小批量的增量索引。 | 很多系统只支持批量的索引,有时数据源有一点增加也需要重建索引。 |
| 数据源 | Lucene没有定义具体的数据源,而是一个文档的结构,因此可以非常灵活的适应各种应用(只要前端有合适的转换器把数据源转换成相应结构) | 很多系统只针对网页,缺乏其他格式文档的灵活性。 |
| 索引内容抓取 | Lucene的文档是由多个字段组成的,甚至可以控制那些字段需要进行索引,那些字段不需要索引,近一步索引的字段也分为需要分词和不需要分词的类型:需要进行分词的索引,比如:标题,文章内容字段 不需要进行分词的索引,比如:作者/日期字段 | 缺乏通用性,往往将文档整个索引了 |
| 语言分析 | 通过语言分析器的不同扩展实现:可以过滤掉不需要的词:an the of 等,西文语法分析:将jumps jumped jumper都归结成jump进行索引/检索非英文支持:对亚洲语言,阿拉伯语言的索引支持 | 缺乏通用接口实现 |
| 查询分析 | 通过查询分析接口的实现,可以定制自己的查询语法规则:比如: 多个关键词之间的 + - and or关系等 | |
| 并发访问 | 能够支持多用户的使用 |
分词机制
关于亚洲语言的的切分词问题(Word Segment)
对于中文来说,全文索引首先还要解决一个语言分析的问题,对于英文来说,语句中单词之间是天然通过空格分开的,但亚洲语言的中日韩文语句中的字是一个字挨一个,所有,首先要把语句中按“词”进行索引的话,这个词如何切分出来就是一个很大的问题。
首先,肯定不能用单个字符作(si-gram)为索引单元,否则查“上海”时,不能让含有“海上”也匹配。
但一句话:“北京天安门”,计算机如何按照中文的语言习惯进行切分呢?
“北京 天安门” 还是“北 京 天安门”?让计算机能够按照语言习惯进行切分,往往需要机器有一个比较丰富的词库才能够比较准确的识别出语句中的单词。
另外一个解决的办法是采用自动切分算法:将单词按照2元语法(bigram)方式切分出来,比如:
“北京天安门” ==> “北京 京天 天安 安门”。
这样,在查询的时候,无论是查询"北京" 还是查询"天安门",将查询词组按同样的规则进行切分:“北京”,“天安安门”,多个关键词之间按与"and"的关系组合,同样能够正确地映射到相应的索引中。这种方式对于其他亚洲语言:韩文,日文都是通用的。
基于自动切分的最大优点是没有词表维护成本,实现简单,缺点是索引效率低,但对于中小型应用来说,基于2元语法的切分还是够用的。基于2元切分后的索引一般大小和源文件差不多,而对于英文,索引文件一般只有原文件的30%-40%不同
| 自动切分 | 词表切分 | |
|---|---|---|
| 实现 | 实现非常简单 | 实现复杂 |
| 查询 | 增加了查询分析的复杂程度 | 适于实现比较复杂的查询语法规则 |
| 存储效率 | 索引冗余大,索引几乎和原文一样大 | 索引效率高,为原文大小的30%左右 |
| 维护成本 | 无词表维护成本 | 词表维护成本非常高:中日韩等语言需要分别维护。还需要包括词频统计等内容 |
| 适用领域 | 嵌入式系统:运行环境资源有限;分布式系统:无词表同步问题;多语言环境:无词表维护成本 | 对查询和存储效率要求高的专业搜索引擎 |
目前比较大的搜索引擎的语言分析算法一般是基于以上2个机制的结合。关于中文的语言分析算法,大家可以在Google查关键词"wordsegment search"能找到更多相关的资料。
更多细节查看:
https://www.chedong.com/tech/lucene.html
Elasticsearch的使用场景
(1) 维基百科(类似百度百科): 全文检索, 高亮, 搜索推荐;
(2) The Guardian(新闻网站): 用户行为日志(点击, 浏览, 收藏, 评论) + 社交网络数据(对某某新闻的相关看法), 数据分析(将公众对文章的反馈提交至文章作者);
(3) Stack Overflow(IT技术论坛): 全文检索, 搜索相关问题和答案;
(4) GitHub(开源代码管理), 搜索管理其托管的上千亿行代码;
(5) 日志数据分析: ELK技术栈(Elasticsearch + Logstash + Kibana)对日志数据进行采集&分析;
(6) 商品价格监控网站: 用户设定某商品的价格阈值, 当价格低于该阈值时, 向用户推送降价消息;
(7) BI系统(Business Intelligence, 商业智能): 分析某区域最近3年的用户消费额的趋势、用户群体的组成结构等;
(8) 其他应用: 电商、招聘、门户等网站的内部搜索服务, IT系统(OA, CRM, ERP等)的内部搜索服务, 数据分析(ES的又一热门使用场景).
总结: Elasticsearch用于在较大用户量、较高访问量的分布式系统中, 对数据进行搜索与分析
基础概念
term(索引词)
在ES中, 索引词(term)是一个能够被索引的精确值, 可以通过term query进行准确搜索.
举例: foo、Foo、FOO是不同的索引词.
text(文本)
文本是一段普通的非结构化文字, 通长文本会被分析成多个Term, 存储在ES的索引库中.
文本字段一般需要先分析再存储, 查询文本中的关键词时, 需要根据搜索条件搜索出原文本.
analysis(分析)
分析是将文本转换为索引词的过程, 分析的结果依赖于分词器.
比如: FOO BAR、Foo-Bar和foo bar可能会被分析成相同的索引词foo和bar, 然后被存储到ES的索引库中. 当用FoO:bAr进行全文搜索的时候, 搜索引擎根据匹配计算也能在索引库中查找到相关的内容.
cluster(集群)
集群由一个或多个节点组成, 对外提供索引和搜索服务. 集群中有且只能有一个节点被选举为主节点 —— 主从节点是集群内部的说法, 对用户是透明的 —— 去中心化, 访问任一节点等价于访问整个集群.
同一网络中, 每个ES集群都要有唯一的名称用于区分, 默认的集群名称为"elasticsearch".
水平扩展时, 只需要将新增节点的集群名称设置为要扩容的集群名称, 该节点就会自动加入集群中.
一个节点只能加入到一个集群中.
node(节点)
节点是逻辑上独立的服务, 是集群的一部分, 可以存储数据, 并参与集群的索引和检索功能.
节点也有唯一的名称, 用于集群的管理和通信. 节点名称在启动的时候自动分配 —— 当然可以自定义.
如果有多个节点在运行, 默认情况下, 这些节点会自动组成一个名为Elasticsearch的集群.
如果只有一个节点在运行, 该节点就会组成只有一个节点的名为Elasticsearch的集群.
每个节点属于哪个集群是通过"集群名称"来决定的.
shard(分片)
单台机器(节点)无法存储大量的索引数据, ES可以把一个完整的索引分成多个分片, 分布到不同的节点上, 从而构成分布式索引.
分片的数量只能在创建索引前指定, 创建索引后不能修改.
5.x 版本开始默认不能通过配置文件elasticsearch.yml定义分片个数.
每个分片都是一个Lucene实例, 即每个分片底层都有一个单独的Lucene提供索引和检索服务, 它们可以托管在集群的任一节点上.
单个Lucene中存储的索引文档最大值为 lucene-5843, 极限是2147483519(=integer.max_value - 128) 个文档. 可使用_cat/shards API 监控分片的大小.
replica(副本)
ES支持为每个Shard创建多个副本, 相当于索引数据的冗余备份.
副本的重要性:
① 解决单点问题, 提高可用性和容错性: 某个节点失败时服务不受影响, 可以从副本中恢复;
② 提高查询效率: 搜索可以在所有的副本上并行执行, 提高了服务的并发量.
分片分为Primary Shard(主分片)、Replica Shard(副本分片), 建立索引时, 系统会先将索引存储在主分片中, 然后再将主分片中的索引复制到不同的副本中.
注意: 主分片和副本分片不能存储在同一个节点中 —— 无法保证高可用.
主分片在建立索引时设置, 后期不能修改; 5.x版本中, 默认主分片为5个, 默认副本分片数为1个, 即每个主分片各有1个副本分片(共5个副本分片); 可随时修改副本分片的数量.
==> 默认情况下, 每个索引共有 5 primary shard + 5 * 1 replica shard = 10 shard.
==> 集群中至少要有2个节点: 最小的高可用配置.
river(数据源)
从其他存储方式 (如数据库) 中同步数据到ES的方法, 它是以插件方式存在的一个ES服务, 通过读取river中的数据并把它索引到ES中.
-官方的river有couchDB、RabbitMQ、Twitter、Wikipedia等.
gateway(网关)
ES索引的持久化存储方式. 默认是先把索引存放到内存中, 当内存满了时再持久化到硬盘.
ES集群重新启动时就会从gateway中读取索引数据.
ES支持多种类型的gateway: 本地文件系统(默认), 分布式文件系统, Hadoop的HDFS, 以及Amazon的s3云存储服务等.
discovery.zen(自动发现)
ES是一个基于p2p的系统: 先通过广播寻找存在的节点, 再通过多播协议进行节点之间的通信, 同时也支持点对点的交互.
5.x版本关闭了广播, 需要自定义.
Transport(通信)
ES内部节点或集群与客户端的交互方式, 默认使用TCP协议进行交互, 同时也支持HTTP协议(JSON格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成).
节点间通信端口默认为: 9300-9400.
recovery(数据恢复)
又叫数据重新分布: 当有节点加入或退出时, ES会根据机器的负载对索引分片进行重新分配, 挂掉的节点重新启动时也会进行数据恢复.
Kibana工具中通过 GET /_cat/health?v 可以看到集群所处的状态.
index(索引)
索引是具有相似结构的文档的集合, 比如可以有一个商品分类索引, 订单索引.
索引的名称要小写, 通过索引名称来执行索引、搜索、更新和删除等操作.
type(类型)
每个索引中可以定义一个或多个type, type是index的逻辑分类.
一种type一般被定义为具有一组公共field的document, 比如对博客系统中的数据建立索引, 可以定义用户数据type, 博客数据type, 评论数据type.
即每个document都有与之对应的type.
document(文档)
文档是存储在ES中的一个个JSON格式的字符串, 是ES索引中的最小数据单元.
文档由field(字段)构成.
一个document可以是一条商品分类数据, 一条订单数据, 例如:
# book document
{
"book_id": "1",
"book_name": "Thinking in Java(Java 编程思想)",
"book_desc": "Java学习者不得不看的经典书籍",
"book_price": 108.00,
"category_id": "5"
}
mapping(映射)
类似于关系数据库中的表结构, 每个index都有一个映射: 定义索引中每个字段的类型.
所有文档在写进索引之前都会先进行分析, 如何对文本进行分词、哪些词条又会被过滤, 这类行为叫做映射(mapping).
映射可以提前定义, 也可以在第一次存储文档时自动识别. 一般由用户自己定义规则.
类似于Solr中约束schema.xml文件的作用.
field(字段)
字段可以是一个简单的值(如字符串、数字、日期), 也可以是一个数组, 还可以嵌套一个对象或多个对象.
字段类似于关系数据库中表数据的列, 每个字段都对应一个类型.
可以指定如何分析某一字段的值, 即对Field指定分词器.
ES的索引中, 各概念的关系为: Field =组成=> Document =组成=> Type =组成=> Index, 索引结构图如下:
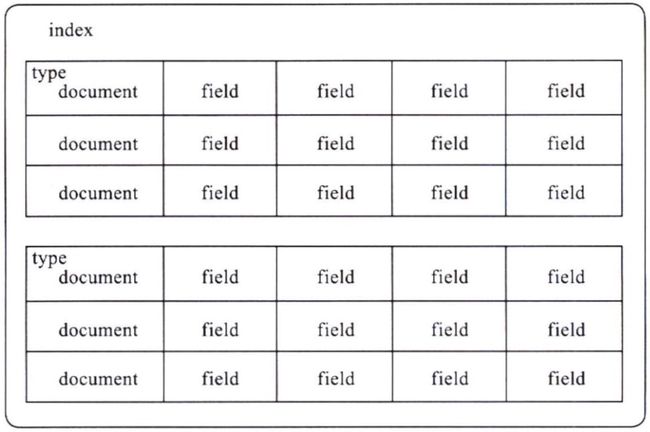
与关系型数据库的对比
| Elasticsearch | RDBMS |
|---|---|
| Index(索引) | DataBase(数据库) |
| Type(类型) | Table(表) |
| Document(文档) | Row(行) |
| Field(字段) | Column(列) |
其他项目中集成使用
Python Elasticsearch Client
系统学习参考
Elasticsearch权威指南中文版在线阅读
elasticsearch权威指南中文版pdf下载
转载请注明出处:EFK家族—Elasticsearch介绍