NLP算法岗面试知识点总结
1.梯度下降做线性回归求解; 参数优化 ; 参数都初始化为0时有啥问题 ;逻辑回归和线性回归的本质区别
参数都初始化为0的问题
w初始化全为0,使得在反向传播的过程中所有参数结点可能变得相同,进而很可能直接导致模型失效,无法收敛。因此应该把参数初始化为随机值。
逻辑回归和线性回归的本质区别
- 逻辑回归引入了sigmoid函数,这是一个非线性函数,增加了模型的表达能力
- 逻辑回归输出有限离散值,可以用来解决概率问题、分类问题等。
- 两者使用的成本函数不同,线性回归使用的平方差,逻辑回归使用的是对数损失函数(更本质来讲,线性回归使用最小二乘方法、或梯度下降方法进行成本函数的求解,而逻辑回归使用最大似然方法进行求解)
2.损失函数有哪些;多分类下softmax的损失函数;softmax交叉熵反向推到公式
2.1 损失函数有哪些
- 平方损失(预测)
- 交叉熵(分类问题)
- hinge损失(SVM支持向量机)
- CART回归树的残差损失
2.2 多分类下的softmax损失函数
L = ∑ i N ∑ k = 1 C y ( i k ) l o g ( y ^ ( i k ) ) L = \sum{_{i}^{N}}\sum{_{k=1}^{C}}y^{(ik)}log(\hat{y}^{(ik)}) L=∑iN∑k=1Cy(ik)log(y^(ik))
2.3 softmax交叉熵反向推导公式
3.self-attention的公式;self-attention的作用;Attntion的作用;
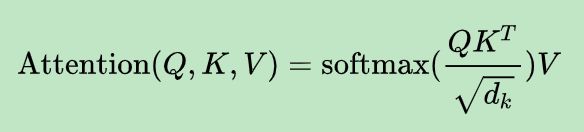
self-attention的作用
自注意力(self-attention)层,这层帮助编码器在对每个单词编码时关注输入句子的其他单词。
4.梯度消失、梯度爆炸的原因和解决方案
4.1 梯度消失和梯度爆炸的原因
反向传播算法中要对激活函数进行求导,如果此部分大于1,那么神经网络层数增多的时候,最终的求出的梯度更新将以指数形式增加,即发生梯度爆炸,如果此部分小于1,那么随着神经网络层数增多,求出的梯度更新信息将会以指数形式衰减,即发生了梯度消失。梯度消失也和激活函数的选择有很大关系,如果激活函数选择不合适,在进行链式求导的时候其结果小于1,就非常容易发生梯度消失。
4.2 梯度消失和梯度爆炸的解决方案
-
预训练加微调
-
加入正则化
-
梯度修剪
-
选择合适的激活函数,relu、leakrelu、elu等激活函数
-
batchnorm
Batchnorm本质上是解决反向传播过程中的梯度问题。batchnorm全名是batch normalization,简称BN,即批规范化,通过规范化操作将输出信号x规范化保证网络的稳定性。
-
LSTM
LSTM全称是长短期记忆网络(long-short term memory networks),是不那么容易发生梯度消失的,主要原因在于LSTM内部复杂的“门”(gates),如下图,LSTM通过它内部的“门”可以接下来更新的时候“记住”前几次训练的”残留记忆“,因此,经常用于生成文本中。
5.Word2vec,BERT,ELMo详细介绍;BERT微调 ;BERT如何使用transformer的encoding模块;BERT的输入和transformer有什么不同;BERT有什么缺点;transformer中attention和self-attention机制;BERT为什么只用Transformer的Encoder而不用Decoder;
一些关于BERT的问题整理记录
一些关于Transformer问题整理记录
一些关于ELMo问题整理记录
5.1 解读Transformer, 一篇文章解决
http://blog.itpub.net/31562039/viewspace-2375080/
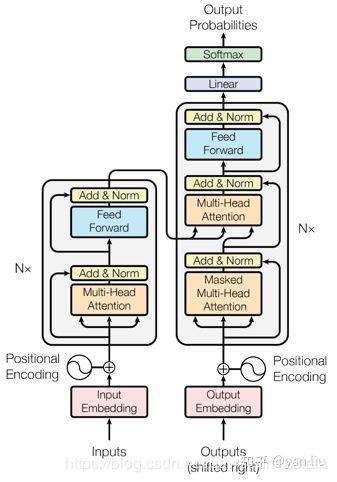
5.2 解读BERT
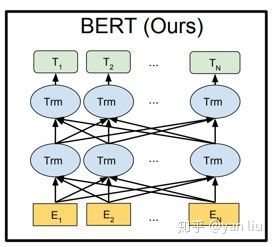
上图中的Trm就对应Transformer结构中左侧的Transformer Block。其中的$T_{1}, T_{2},…, T_{N}对应的就是由BERT得到的词向量。
5.3 BERT的微调策略
-
预训练的长本文,因为Bert的最长文本序列是512
-
层数选择,每一层都会捕获不同的信息,因此我们需要选择最适合的层数
-
过拟合问题,因此需要考虑合适的学习率。Bert的底层会学习到更多的通用的信息,文中对Bert的不同层使用了不同的学习率。 每一层的参数迭代可以如下所示:
θ t l = θ t l − 1 − \theta_{t}^{l}=\theta_{t}^{l-1}- θtl=θtl−1−
5.4 BERT如何使用transformer的encoding模块
5.5 BERT的输入和transformer有什么不同
与Transformer本身的Encoder端相比,BERT的Transformer Encoder端输入的向量表示,多了Segment Embeddings。
5.5.1 BERT的输入是包括三部分
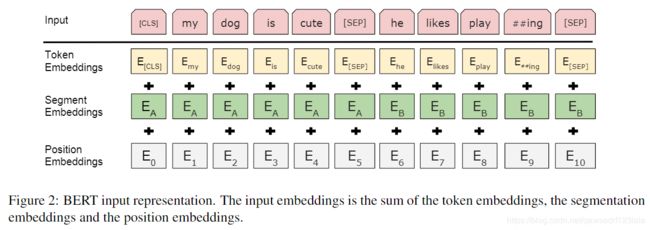
- wordpiece-token向量
- 位置向量:512个。训练
- 段向量:sentence A B两个向量。训练
- 一些符号:
- CLS:special classification embedding,用于分类的向量,会聚集所有的分类信息
- SEP:输入是QA或2个句子时,需添加SEP标记以示区别
- E A E_{A} EA 和 E B E_{B} EB:输入是QA或2个句子时,标记的sentence向量。如只有一个句子,则是sentence A向量
5.5.2 Transformer的输入
Transformer的输入涉及到两个部分既word embedding 和position embedding。没有段向量以CLS和SEP标识符。
5.6 BERT的缺点
- 模型参数太多,而且模型太大,少量数据训练时,容易过拟合。
- BERT在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,然而有时候这些单词之间是有关系的。
- BERT的在预训练时会出现特殊的[MASK],但是它在下游的fine-tune中不会出现,这就出现了预训练阶段和fine-tune阶段不一致的问题。
- 另外还有一个缺点,是BERT在分词后做[MASK]会产生的一个问题,为了解决OOV的问题,我们通常会把一个词切分成更细粒度的WordPiece。
6.为什么使用交叉熵,不用平方差;手写交叉熵公式;手推Softmax交叉熵损失函数;
6.1 为什么使用交叉熵而不用平方差
在激活函数是sigmoid之类的函数的时候,用平方损失的话会导致误差比较小的时候梯度很小,这样就没法继续训练了,这时使用交叉熵损失就可以避免这种衰退
6.2 交叉熵公式(二分类)
单个样本的损失函数
y ^ = P ( y = 1 ∣ x ) \hat{y} = P(y=1|x) y^=P(y=1∣x)
1 − y ^ = P ( y = 0 ∣ x ) 1-\hat{y} = P(y=0|x) 1−y^=P(y=0∣x)
从极大似然情况组合以上两个公式
P ( y ∣ x ) = y ^ y ⋅ ( 1 − y ^ ) 1 − y P(y|x)=\hat{y}^y \cdot (1-\hat{y})^{1-y} P(y∣x)=y^y⋅(1−y^)1−y
l o g ( P ( y ∣ x ) ) = l o g ( y ^ y ⋅ ( 1 − y ^ ) 1 − y ) = y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) log(P(y|x)) = log(\hat{y}^y \cdot (1-\hat{y})^{1-y}) = y log\hat{y} + (1-y) log(1-\hat{y}) log(P(y∣x))=log(y^y⋅(1−y^)1−y)=ylogy^+(1−y)log(1−y^)
所有样本的损失函数
我们期望 l o g ( P ( y ∣ x ) ) log(P(y|x)) log(P(y∣x)) 越大越好,所以既有下列损失函数,使得 L L L 越小越好。
L = ∑ − [ y ( i ) l o g y ^ ( i ) + ( 1 − y ( i ) ) l o g ( 1 − y ^ ( i ) ) ] L=\sum{-[y^{(i)} log\hat{y}^{(i)} + (1-y^{(i)}) log(1-\hat{y}^{(i)})]} L=∑−[y(i)logy^(i)+(1−y(i))log(1−y^(i))](二分类的交叉熵损失函数)
L = − ∑ i N ∑ c = 1 M y ( i ) l o g ( y ^ ( i ) ) L = -\sum{_{i}^{N}\sum_{c=1}^{M}}y^{(i)}log(\hat{y}^{(i)}) L=−∑iNc=1∑My(i)log(y^(i)) (多分类的交叉熵损失函数)
其他文章对交叉熵函数的一些解释


6.3 手推Softmax交叉熵损失函数
https://zhuanlan.zhihu.com/p/60042105
7.降维(PCA)的原理以及涉及的公式;
8.Bagging和Boosting的区别;XGBoot,LGB 和 GBDT的区别;LSTM各类门结构;GBDT和RF (随机森林) 的区别;
8.1 Bagging 和 Boosting的区别
Bagging和Boosting的简单了解
8.1.1 Bagging
Bagging 的核心思路是——民主。
Bagging 的思路是所有基础模型都一致对待,每个基础模型手里都只有一票。然后使用民主投票的方式得到最终的结果。
具体的过程:
- 从原始样本集中使用Bootstraping 方法随机抽取n个训练样本,共进行k轮抽取,得到k个训练集(k个训练集之间相互独立,元素可以有重复)。
- 对于k个训练集,我们训练k个模型,(这个模型可根据具体的情况而定,可以是决策树,knn等)
- 对于分类问题:由投票表决产生的分类结果;对于回归问题,由k个模型预测结果的均值作为最后预测的结果(所有模型的重要性相同)。

8.1.2 Boosting
Boosting 的核心思路是——挑选精英。
Boosting 和 bagging 最本质的差别在于他对基础模型不是一致对待的,而是经过不停的考验和筛选来挑选出「精英」,然后给精英更多的投票权,表现不好的基础模型则给较少的投票权,然后综合所有人的投票得到最终结果。
具体过程:
- 通过加法模型将基础模型进行线性的组合。
- 每一轮训练都提升那些错误率小的基础模型权重,同时减小错误率高的模型权重。
- 在每一轮改变训练数据的权值或概率分布,通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值,来使得分类器对误分的数据有较好的效果。
8.1.3 Bagging 和 Boosting 的 4 点差别
样本选择上:
- Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
- Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
样例权重:
- Bagging:使用均匀取样,每个样例的权重相等
- Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
预测函数:
- Bagging:所有预测函数的权重相等。
- Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
并行计算:
- Bagging:各个预测函数可以并行生成
- Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
8.2 XGBoot,LGB 和 GBDT的区别
9.SGD 和 min-SGD的区别
-
随机梯度下降 (SGD):相对于梯度下降,可以看到多了随机两个字,随机也就是说我每次用样本中的一个例子来近似我所有的样本,用这一个例子来计算梯度并用这个梯度来更新 θ \theta θ。因为每次只用了一个样本因而容易陷入到局部最优解中。
-
批量随机梯度下降 (mini-SGD):他用了一些小样本来近似全部的,其本质就是1个样本的近似不一定准,那就用更大的30个或50个样本来近似。将样本分成m个mini-batch,每个mini-batch包含n个样本;在每个mini-batch里计算每个样本的梯度,然后在这个mini-batch里求和取平均作为最终的梯度来更新参数;然后再用下一个mini-batch来计算梯度,如此循环下去直到m个mini-batch操作完就称为一个epoch结束。
10.CRF, HMM的细节
CRF和HMM并不是多么明白。
利用中文分词实例讲解HMM
http://yanyiwu.com/work/2014/04/07/hmm-segment-xiangjie.html
两者的区别
- HMM是生成模型,CRF是判别模型
- HMM是概率有向图,CRF是概率无向图
- HMM求解过程可能是局部最优,CRF可以全局最优
- CRF概率归一化较合理,HMM则会导致label bias 问题
11.优化器系统的讲一下
12.L1 L2正则化;
-
L1正则化指的是权值向量 w w w 中各个元素的绝对值之和,通常表示为 ∣ ∣ w ∣ ∣ 1 ||w||_{1} ∣∣w∣∣1
-
L2正则化指的是权值向量 w w w 中各个元素的平方和然后再求平方根,通常表示为 ∣ ∣ w ∣ ∣ 2 ||w||_{2} ∣∣w∣∣2
-
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
-
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
13.SVM了解吗?有什么优点?优化方法?
14.什么是过拟合?产生的原因?如何解决?
-
产生原因:模型太复杂;训练数据不够;
-
解决方案:数据集扩增;加入正则;添加dropout;提前停止;batchnomalization;
15.精确率 § / 召回率 ® / F1值
16.反向传播算法的意义是什么?
17.各种优化算法
一文看懂各种神经网络优化算法:从梯度下降到Adam方法
18. K-Means算法流程
从数据集中随机选择K个聚类样本作为初始的聚类中心,然后计算数据集中每个样本到这K个聚类中心的距离,并将此样本分到距离最小的聚类中心所对应的类中。将所有样本归类后,对于每个类别重新计算每个类别的聚类中心既每个类中所有样本的质心,重复以上操作直到聚类中心不变为止。
RNN;LSTM;GRU;结构以及计算公式
深度学习 (一)
这里主要对牛客网的面经中不熟悉的点再手敲一遍,加深记忆。
1.Batchnormallization的作用
由于神经网络层数的加深,在反向传播时底层的神经网络可能发生梯度消失的问题,BatchNormalization的作用就是规范化输入,把不规范的分布拉到正态分布,使得数据能够分布在激活函数的敏感区域。进而可以使得梯度变大,加快学习的收敛速度,避免梯度消失的问题。
2.梯度消失
3.循环神经网络,为什么好
4.什么是Group Convolutional
若卷积神经网络的上一层有N个卷积核,则对应的通道数也为N。设群体数目为M,在进行卷积操作的时候,那么该群卷积层的操作就是,先将channel分成M份。每一个group对应N/M个channel,与之独立连接。然后各个group卷积完成后将输出叠在一起(concatenate),作为这一层的输出channel。
5.什么是RNN
6.训练过程中,如果一个模型不收敛,那么是否说明这个模型无效?导致模型不收敛的原因有哪些?
不能说明模型无效;导致不收敛的原因可能是数据分类的标注不准确,样本信息量太大导致模型不足以fit整个样本空间。学习率设置太大容易产生震荡,太小容易不收敛。数据没有进行归一化操作等
7.为什么用2个3*3的卷积核而不是5*5
因为两者有相同的感受野,但是前者的参数更少
8.ReLU比Sigmoid好在哪里
Sigmoid只在0的附近时有比较好的激活性,而在正负饱和区的梯度趋近于0,从而产生梯度消失问题;而relu在大于0的部分梯度为常数,所以不会有梯度消失。ReLU的导数计算更快。ReLu在负半导数区为0,所以神经元激活值为负时,梯度为0,此神经元不参与训练,具有稀疏性。
9.权值共享问题
10.激活函数
relu,sigmoid,tanh
11.在深度学习中,通常会finetuning已有的成熟模型,再基于新数据,修改最后几层神经网络权值,为什么?
实践中的数据集质量参差不齐,可以使用训练好的网络来进行特征提取。把训练好的网络当作特征提取器。
12.Attention的作用
- 减小处理高维输入数据的计算负担,通过结构化的选取输入的子集,降低数据维度。
- “去伪存真”,让任务处理系统更专注于找到输入数据中显著的与当前输出相关的有用信息,从而提高输出的质量。
13.LSTM

14.LSTM和GRU的原理
15.什么是dropout
在神经网络的计算过程中,对于神经单元按照一定的概率将其随机从网络中丢弃,从而达到对于每个mini-batch都是在训练不同的网络的效果,防止过拟合。
深度学习 (二)
16.优化器Adam
Adam算法和传统的SGD不同。SGD保持单一的学习率更新所有权重,学习率在训练过程中不会改变。而Adam通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应学习率。
17.RNN梯度消失问题,为什么LSTM和GRU可以解决此问题
RNN由于网络比较深,后面层的输出误差很难影响到前面层的计算,RNN的某一单元主要受他附近单元的影响。而LSTM可以通过阀门记忆一些长期的信息,相应的保留了更多的梯度。而GRU也可以通过重置和更新两个阀门保留长期的记忆,进而相对解决梯度消失的问题。
18.1*1卷积的作用
- 实现跨通道的交互和信息整合
- 实现卷积核通道的降维和升维
- 可以实现多个feature map的线性组合而且可以实现与全连接等价的效果
19.如何提升模型泛化能力 - 数据:搜集更多数据;对数据做一些变化
- 算法:更好的权重初始化方式;调整学习率;调节batch和epoach的大小;添加正则;尝试其他优化器;使用early stopping。
20. RNN和LSTM的区别
21.如何防止过拟合
- 扩增数据集
- 加入dropout
- 加入正则
- batchnomaliztaion
- early stopping
22. 为什么需要神经元稀疏
更好的挖掘相关特征,拟合数据。而由于ReLU激活函数可以实现一半激活一半抑制,因而可以能够更好的实现神经元的稀疏。
深度学习 (三)
LSTM的正向推导和反向推导过程
二面
1.手写svm,
2.手写LR,
3.手推前向传播。
4.xgb详细讲解。
5.knn,k-mean。
6.旋转数组:用额外内存和不用。
7.判断是不是后续遍历中序二叉树。
8.python内存管理,内存池最大?
9.python可变不可变数据结构。
10 python lamba与def 定义函数的区别
三面:
1.redis和mongodb与mysql。。真不会。
2.加快搜索速度方法。
3.计算相似度方法。
4.bert微调。
5.研究生最大收获。
6.研究生与本科生区别。
问面试官的问题:
7有啥问题:1.你们干啥的,2.你看起来为啥像95后,不应该是总监么。3.多久能收到反馈。