亲和性分析示例:根据购买商品习惯推荐商品
本片文章主要是学习笔记分享
先做一个自我的简单介绍,本人在IT这个行业的底子非常薄,之前学习过java但是因为学历的问题找了很久没有找到java开发的工作,面对当时的现实问题放弃了继续找java开发工作,这件事情对于我个人还是有影响和压力的,但是内心中并没有放弃写代码,当一个正规程序员的理想,正好我现在工作是数据分析师,但我想说没有灵魂的数据分析师不是一个好厨子,个人感觉真正的数据分析师是一个对综合要求很高的工作,所以长期对自己保持充电才能升任这份工作。
刚学Python不久,买了一本Python的基础教程又看了一些视频,把Python的基础学习了一遍,因为本人之前学习过Java所以接收起来还算可以,最近又买了一本Python数据挖掘基础入门的书,Python能做的事情真的是太多了,但是我个人为什么选用Python来做数据挖掘和数据分析,因为之前在学习Python基础的时候发现Python的语法简单明了,第三方库也是非常强大所以新手开荒起来相比其他数据挖掘语言相比还是很容易上手的。
接下来进入正题第一章的亲和性示例分析,那什么是亲和性分析呢?亲和性分析根据样本的个体(物体)之间的相似度,确定他们关系的亲疏.亲和性有多种测量的方法。例如,统计两件商品同时出售的频率,或者统计顾客购买了商品A在购买商品B的比率。
不废话了直接上代码:
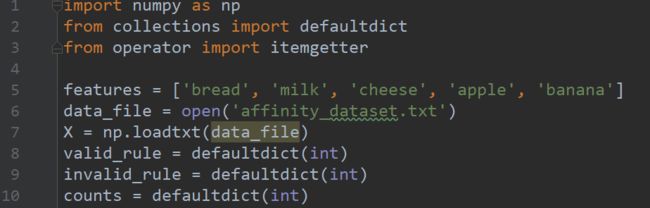
解释一下1-10行的意思,前三行不必多说引入我们接下来需要用到的第三方库,第五行是建立一个列表里面存放了5中商品,第6行是读取一个数据文件,数据文件大概是这样的,每一列对应了上面列表中建立的5中商品,0代表未购买,1代表已购买,每一行可以看作是一个顾客的购买记录。

第七行是读取数据返回的是一个嵌套列表,这里把这个方法的其他参数我都列出来了np.loadtxt(fname=txt的路径或者名称, dtype=数据类型, comments='#'这里的comment的是指, 如果行的开头为#就会跳过该行, delimiter=数据之间的分隔符',', converters=这个是对数据进行预处理的参数, 我们可以先定义一个函数, 这里的converters是一个字典, skiprows=跳过开头的行数,缺省值0, usecols=可选取数据的列例如(1,5), unpack=如果是True,返回的数组将被转置,以便可以使用`x,y,z=loadtxt(...)‘’解压参数。当与记录数据类型一起使用时,每个字段都返回数组。默认是False, ndmin=返回的数组将至少具有“ndmin”维度。否则,mono-dimensional axes will be squeezed。合法值:0(默认)、1或2。)。
第8-10行建立三个变量为什么要用defaultdict这个方法,是为了防止在使用字典的时候key Error,defaultdict类的初始化函数接受一个类型作为参数,当所访问的键不存在的时候,可以实例化一个值作为默认值,这个地方不多说网上有很多关于defaultdict类的使用介绍。
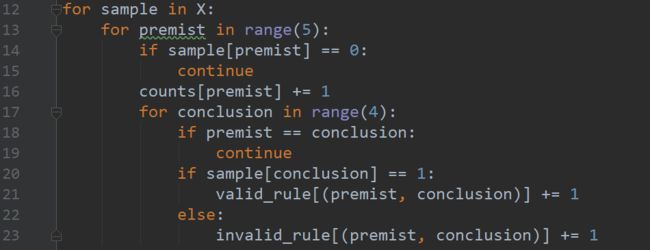
12-23行是今天学习比较核心地方,因为今天学习的就是亲和性分析所以我们要实现简单的排序规则,我们要找出"如果顾客购买了商品X,那么他们可能愿意购买商品Y"这样的规则,简单的办法就是找出数据集中所有同时购买的两种商品,找出规则后判断其优劣.规则的优劣有多种衡量方法,其中最常用的就是,支持度&置信度,支持度指数据集中规则应验的次数,置信度衡量的是规则的准确度如何,即符合给定的所有规则里跟当前规则结论一致的比例有多大,计算方法为首先统计当前规则出现的次数,在用它来除以条件相同规则的数量。第一个for循环是从嵌套列表取出第一个元素,第二个否循环就是前提条件,第一个if如果等于0表示顾客没有购买商品,接着返回第二个循环直到不等于0,就记录一次哪种商品被购买了一次,以字典的形式存入counts[premist]中例如{2:1}就表示苹果被购买了一次,第三个for循环表示结论在购买苹果的同时是否也购买了其它一件商品,第二个if判断的意思是排除比如购买了苹果也购买苹果因为这样的条件没有意义(其实这个地方的意思就是假设premist是元素2的时候,conclusion正好也循环到2的时候就接着循环不接着往下走,这个其实就相当于如果购买了苹果也买苹果),接着在说第三个if这个其实就是找到同时购买的另一商品,等于1就相当于购买了另一种商品就证明规则有效else就是无效的规则。
得到所有必要的统计量后,在来计算每条规则的支持度&置信度

36-40行支持度就是规则应验次数support来存放,在建立一个confidence来存放置信度,第一个循环就是从支持度中取出键这个键是一个元组,分别代表了购买了哪种商品的同时又购买了那种商品例如(2,3),分别赋给premist和conclusion,在存到一个单独的元组中,接下来计算置信度,每个有效的规则除以每个商品被购买的总次数得到了置信度,到这里我们所需要的支持度和置信度都计算完成了在做一个排序输出置信度或者支持度前五的。

这里我使用了置信度作为排序,items()返回包含字典所有元素的列表,在使用itemgetter(1)作为键,reveres=True表示降序排列,在解释一下52行的sorted_confidence[index][0]取出列表中元组的元素。现在使用置信度排序的然后格式化一下输出结果如图


今天就到这里了所有的学习内容都分享出来了,第一次发表不足的地方希望大家多多体谅,如果有不对的地方也希望大家及时提出来我会及时修改,其实学习没有什么诀窍,最好的诀窍就是不断实践和总结,在有看不懂的代码不断Debug看执行过程和不断的print,也可以重复的理解着写5次以上绝对有意想不到的效果,喜欢交流或者一起学习的朋友可以加我QQ409894945。