linux整理-26 Shell三剑客grep,sed,awk
目录
grep 查找 , sed 编辑, awk 根据内容分析并处理
grep(文本生成器)
sed(流编辑器)
awk(报表生成器)
介绍
awk:AWK一次处理是一行, 而一次中处理的最小单位是一个区域
sed: (关键字: 编辑) 以行为单位的文本编辑工具
grep: (关键字: 截取) 文本搜集工具, 结合正则表达式非常强大
grep
是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来
sed
sed 是一种在线编辑器,它一次处理一行内容 。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。
awk
相较于sed 常常作用于一整个行的处理,awk 则比较倾向于一行当中分成数个『字段』来处理。 因此,awk 相当的适合处理小型的数据数据处理
工作原理:
第一步:执行BEGIN{ commands }语句块中的语句;
第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ commands}语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
第三步:当读至输入流末尾时,执行END{ commands }语句块。
脚本结构:
awk ‘BEGIN{ print “start” } pattern{ command } END{ print “end”}’ file(文件)
grep(文本生成器)
grep是一种强大的文本搜索工具,他能使用正则表达式搜索文本,并把匹配的行统计出来
命令:grep [选项] [–color=auto] ”搜索字符串” filename
常用参数:
-c:统计符合条件的字符串出现的总行数。
-E:支持扩展正则表达式。
-i:忽略字符大小写。
-n:在显示匹配到的字符串前面加上行号。
-v:显示没有”搜索字符串”内容的那一行。
-l:列出文件内容中有搜索字符串的文件名称。
-o:只输出文件中匹配到的部分。
-color=auto:将匹配到的字符串高亮出来。
1、基本使用
查询包含hadoop的行
grep hadoop /etc/passwd
[root@localhost ~]# grep hadoop /etc/passwd
hadoop:x:500:504:hadoop01:/home/hadoop:/bin/bash
grep huangbo ./*.txt ## 寻找当前路径下所有txt当中内容那些是带了huangbo字符串的
[root@localhost ~]# grep huangbo ./*.txt
./mazhonghua.txt:my name is huangbo is is huangbo
./sutdent.txt:huangbo 18 jiangxi
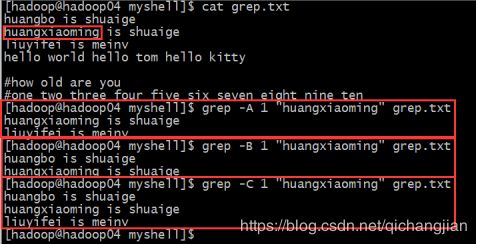
2、先看一份数据:grep.txt
huangbo is shuaige
huangxiaoming is shuaige
liuyifei is meinv
hello world hello tom hello kitty
#how old are you
#one two three four five six seven eight nine ten
2.1、统计出现某个字符串的行的总行数
grep -c ‘hello’ grep.txt
grep -c ‘is’ grep.txt
[hadoop@hadoop04 ~]# grep -c 'hello' grep.txt
[hadoop@hadoop04 ~]# grep -c 'is' grep.txt

2.2、查询不包含is的行
grep -v ‘is’ grep.txt
[hadoop@hadoop04 ~]# grep -v 'is' grep.txt

2.3、正则表达包含huang
grep '.*huang.*' grep.txt
[hadoop@hadoop04 ~]# grep '.*huang.*' grep.txt

2.4、输出匹配行的前后N行(会包括匹配行)
使用-A参数输出匹配行的后一行:grep -A 1 “huangxiaoming” grep.txt
使用-B参数输出匹配行的前一行:grep -B 1 “huangxiaoming” grep.txt
使用-C参数输出匹配行的前后各一行:grep -C 1 “huangxiaoming” grep.txt
3、正则表达(点代表任意一个字符)
grep ‘h.*p’ /etc/passwd
4、正则表达以hadoop开头
grep ‘^hadoop’ /etc/passwd
5、正则表达以hadoop结尾
grep 'hadoop$' /etc/passwd
以h或r开头的
grep '^[hr]' /etc/passwd
不是以h和r开头的
grep '^[^hr]' /etc/passwd
不是以h到r开头的
grep '^[^h-r]' /etc/passwd
正则表达式的简单规则:
. : 任意一个字符
a* : 任意多个a(零个或多个a)
a? : 零个或一个a
a+ : 一个或多个a
.* : 任意多个任意字符
\. : 转义.
o\{2\} : o重复两次
[A-Z]
[ABC]
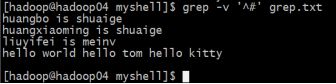
查找不是以#开头的行
grep -v '^#' grep.txt | grep -v '^$'
[root@localhost ~]# grep -v '^#' grep.txt
[root@localhost ~]# grep -v '^#' grep.txt | grep -v '^$'

sed(流编辑器)
sed叫做流编辑器,在shell脚本和Makefile中作为过滤一使用非常普遍,也就是把前一个程序的输出引入sed的输入,经过一系列编辑命令转换成为另一种格式输出。sed是一种在线编辑器,它一次处理一行内容,处理时,把当前处理的行存储在临时缓冲区中,称为"模式空间",接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。
选项:
-n:一般sed命令会把所有数据都输出到屏幕,如果加入-n选项的话,则只会把经过sed命令处理的行输出到屏幕。
-e:允许对输入数据应用多条sed命令编辑。
-i:用sed的修改结果直接修改读取数据的文件,而不是由屏幕输出。
动作:
a:追加,在当前行后添加一行或多行。
c:行替换,用c后面的字符串替换原数据行。
i:插入,在当前行前插入一行或多行。
p:打印,输出指定的行。
s:字符串替换,用一个字符串替换另外一个字符串。格式为'行范围s/旧字符串/新字符串/g'
(如果不加g的话,则表示只替换每行第一个匹配的串)
1、删除:d命令
sed '2d' sed.txt -----删除sed.txt文件的第二行。
sed '2,$d' sed.txt -----删除sed.txt文件的第二行到末尾所有行。
sed '$d' sed.txt -----删除sed.txt文件的最后一行。
sed '/test/d ' sed.txt -----删除sed.txt文件所有包含test的行。
sed '/[A-Za-z]/d ' sed.txt -----删除sed.txt文件所有包含字母的行。
2、整行替换:c命令
将第二行替换成hello world
sed '2c hello world' sed.txt
3、字符串替换:s命令
sed ‘s/hello/hi/g’ sed.txt
## 在整行范围内把hello替换为hi。如果没有g标记,则只有每行第一个匹配的hello被替换成hi。
sed 's/hello/hi/2' sed.txt
## 此种写法表示只替换每行的第2个hello为hi
sed 's/hello/hi/2g' sed.txt
## 此种写法表示只替换每行的第2个以后的hello为hi(包括第2个)
sed -n 's/^hello/hi/p' sed.txt
## (-n)选项和p标志一起使用表示只打印那些发生替换的行。也就是说,如果某一行开头的hello被替换成hi,就打印它。
sed -n '2,4p' sed.txt
## 打印输出sed.txt中的第2行和第4行
sed -n 's/hello/&-hi/gp' sed.txt
sed 's/^192.168.0.1/&-localhost/' sed.txt
sed 's/^192.168.0.1/[&]/' sed.txt
## &符号表示追加一个串到找到的串后。所有以192.168.0.1开头的行都会被替换成它自已加 -localhost,变成192.168.0.1-localhost。第三句表示给IP地址添加中括号
sed -n 's/\(liu\)jialing/\1tao/p' sed.txt
sed -n 's/\(liu\)jia\(ling\)/\1tao\2ss/p' sed.txt
## liu被标记为\1,所以liu会被保留下来(\1 == liu)
## ling被标记为\2,所以ling也会被保留下来(\2 == ling)
## 所以最后的结果就是\1tao\2ss == "liu" + "tao" + "ling" + "ss"
此处切记:\1代表的是被第一个()包含的内容,\1代表的是被第一个()包含的内容,……
上面命令的意思就是:被括号包含的字符串会保留下来,然后跟其他的字符串比如tao和ss组成新的字符串liutaolingss
sed 's#hello#hi#g' sed.txt
## 不论什么字符,紧跟着s命令的都被认为是新的分隔符,所以,"#"在这里是分隔符,代替了默认的"/"分隔符。表示把所有hello替换成hi。
选定行的范围:逗号
sed -n '/today/,/hello/p' sed.txt
## 所有在模板today和hello所确定的范围内的行都被打印。都找第一个,也就是说,从第一个today到第一个hello
sed -n '5,/^hello/p' sed.txt
sed -n '/^hello/,8p' sed.txt
## 打印从第五行开始到第一个包含以hello开始的行之间的所有行。
sed '/today/,/hello/s/$/www/' sed.txt
## 对于模板today和hello之间的行,每行的末尾用字符串www替换。
sed '/today/,/hello/s/^/www/' sed.txt
## 对于模板today和hello之间的行,每行的开头用字符串www替换。
sed '/^[A-Za-z]/s/5/five/g' sed.txt
## 将以字母开头的行中的数字5替换成five
4、多点编辑:e命令
sed -e ‘1,5d’ -e ‘s/hello/hi/’ sed.txt
## (-e)选项允许在同一行里执行多条命令。如例子所示,第一条命令删除1至5行,第二条命令用hello替换hi。命令的执行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。
sed --expression='s/hello/hi/' --expression='/today/d' sed.txt
## 一个比-e更好的命令是--expression。它能给sed表达式赋值。
5、从文件读入:r命令
sed ‘/hello/r file’ sed.txt
## file里的内容被读进来,显示在与hello匹配的行下面,如果匹配多行,则file的内容将显示在所有匹配行的下面。
6、写入文件:w命令
sed -n '/hello/w file' sed.txt
## 在huangbo.txt中所有包含hello的行都被写入file里。
7、追加命令:a命令
sed ‘/^hello/a\—>this is a example’ sed.txt
## '—>this is a example’被追加到以hello开头的行(另起一行)后面,sed要求命令a后面有一个反斜杠。
8、插入:i命令
sed '/will/i\\some thing new -------------------------' sed.txt
## 如果test被匹配,则把反斜杠后面的文本插入到匹配行的前面。
9、下一个:n命令
sed '/hello/{n; s/aa/bb/;}' sed.txt 替换下一行的第一个aa
sed '/hello/{n; s/aa/bb/g;}' sed.txt 替换下一行的全部aa
## 如果hello被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行,然后继续。
10、退出:q命令
sed '10q' sed.txt
## 打印完第10行后,退出sed。
同样的写法:
sed -n '1,10p ' sed.txt
问题:
在一行数据特定位置加入一个字母
echo 'abc' | sed 's/a/&d/g'
awk(报表生成器)
Awk是一个强大的处理文本的编程语言工具,其名称得自于它的创始人Alfred Aho、Peter Weinberger和Brian Kernighan 姓氏的首个字母,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。AWK 提供了极其强大的功能:可以进行样式装入、流控制、数学运算符、进程控制语句甚至于内置的变量和函数。简单来说awk就是扫描文件中的每一行,查找与命令行中所给定内容相匹配的模式。如果发现匹配内容,则进行下一个编程步骤。如果找不到匹配内容,则继续处理下一行。
1、假设last -n 5的输出如下:
[root@localhost ~]# last -n 5
root pts/0 192.168.123.1 Wed Dec 28 01:55 still logged in
reboot system boot 2.6.32-573.el6.x Tue Dec 27 04:25 - 03:11 (22:46)
root pts/1 192.168.123.1 Tue Dec 27 02:00 - 02:00 (00:00)
root pts/1 192.168.123.1 Tue Dec 27 01:59 - 02:00 (00:00)
root pts/0 192.168.123.1 Tue Dec 27 01:59 - down (00:16)
2、只显示五个最近登录的账号:
[root@localhost ~]# last -n 5 | awk '{print $1}'
root
reboot
root
root
root
awk工作流程是这样的:读入有’\n’换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域, 1 表 示 第 一 个 域 , 1表示第一个域, 1表示第一个域,n表示第n个域。默认域分隔符是"空白键" 或 “[tab]键”,所以$1表示登录用户,$3表示登录用户ip,以此类推
3、显示/etc/passwd的账户:
[root@localhost ~]# cat /etc/passwd |awk -F ':' '{print $1}'
root
bin
daemon
adm
lp
这种是awk+action的示例,每行都会执行action{print $1}。
-F指定域分隔符为’:’
4、显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以tab键分割
[root@localhost ~]# cat /etc/passwd |awk -F ':' '{print $1"\t"$7}'
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
5、BEGIN and END
如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割,而且在所有行添加列名name,shell,在最后一行添加"blue,/bin/nosh"。
cat /etc/passwd |awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print "blue,/bin/nosh"}'
cat /etc/passwd | awk -F ':' 'BEGIN {print "name \t shell"} {print$1"\t"$7} END {print "blue,/bin/bash"}'
name,shell
root,/bin/bash
daemon,/bin/sh
....
blue,/bin/nosh
awk工作流程是这样的:先执行BEGIN,然后读取文件,读入有/n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域, 1 表 示 第 一 个 域 , 1表示第一个域, 1表示第一个域,n表示第n个域,随后开始执行模式所对应的动作action。接着开始读入第二条记录••••••直到所有的记录都读完,最后执行END操作。
6、搜索/etc/passwd有root关键字的所有行
awk -F: ‘/root/’ /etc/passwd
root:x:0:0:root:/root:/bin/bash
这种是pattern的使用示例,匹配了pattern(这里是root)的行才会执行action(没有指定action,默认输出每行的内容)。
搜索支持正则,例如找root开头的: awk -F: ‘/^root/’ /etc/passwd
搜索/etc/passwd有root关键字的所有行,并显示对应的shell
awk -F ‘:’ ‘/root/{print $7}’ /etc/passwd
/bin/bash
这里指定了action{print $7}
7、awk常见内置变量
FILENAME:awk浏览的文件名
FNR:浏览文件的记录数,也就是行数。awk是以行为单位处理的,所以每行就是一个记录
NR:awk读取文件每行内容时的行号
NF:浏览记录的域的个数。可以用它来输出最后一个域
FS:设置输入域分隔符,等价于命令行-F选项
OFS:输出域分隔符
统计/etc/passwd:文件名,每行的行号,每行的列数,对应的完整行内容
awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd
awk -F':' '{print "filename:" FILENAME ",linenumber:" NR ",colums:" NF "linecotent:" $0}' /etc/passwd
filename:/etc/passwd,linenumber:3,columns:7,linecontent:bin:x:2:2:bin:/bin:/bin/sh
filename:/etc/passwd,linenumber:4,columns:7,linecontent:sys:x:3:3:sys:/dev:/bin/sh
使用printf替代print,可以让代码更加简洁,易读
awk -F ':' '{printf("filename:%s,linenumber:%s,columns:%s,linecontent:%s\n",FILENAME,NR,NF,$0)}' /etc/passwd
指定输入分隔符,指定输出分隔符:
awk 'BEGIN {FS=":"; OFS="\t"} {print $1, $2}' /etc/passwd
sshd x
tcpdump x
linux x
8、实用例子**
A:打印最后一列:
awk -F: '{print $NF}' /etc/passwd
awk -F: '{printf("%s\n",$NF);}' /etc/passwd
B:统计文件行数:
awk 'BEGIN {x=0} {x++} END {print x}' /etc/passwd
C:打印9*9乘法表:
awk 'BEGIN{for(n=0;n++<9;){for(i=0;i++=1;i--){for(j=i;j>=1;j--){printf i"*"j"="i*j" ";}print ""}}'
D:计算1-100之和:
echo "sum" | awk 'BEGIN {sum=0;} {i=0;while(i<101){sum+=i;i++}} END {print sum}'