Hive入门级教程(详细)
什么是Hive
- Hive 是建立在 Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
- Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
- Hive的表其实就是HDFS的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
Hive的metastore
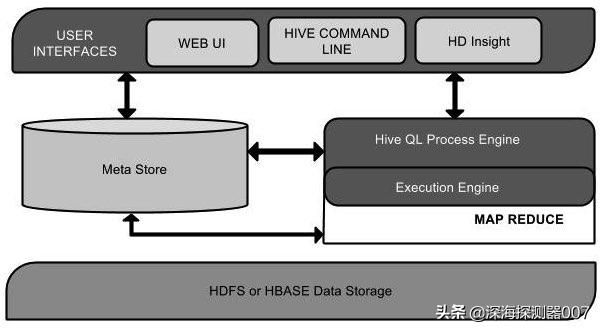
- metastore是hive元数据的集中存放地(元数据存在hive数据库的数据表与HDFS存储文件的对应关系)
- metastore默认使用内嵌的derby数据库作为存储引擎
- Derby引擎的缺点:一次只能打开一个会话
- 使用Mysql作为外置存储引擎,多用户同时访问
Hive系统架构
Hive安装
把hive-0.12.0.tar.gz解压到/data/目录下
[root@master conf]# tar -zxvf hive-0.12.0.tar.gz -C /data
配置Hive环境变量,可参考java环境变量配置。
[root@master conf]# source /etc/profile
配置mysql metastore
上传mysql数据库驱动mysql-connector-java-5.1.28.jar到/data/hive-0.12.0/lib
如果hive-site.xml 文件不存在,则新建一个文件,内容如下所示。
创建数据库
hive> create database user;
删除数据库
hive> drop database user;
创建表
hive> create table student(id int,name string,age int,address string);
加载数据
hive> load data [local] inpath '/home/testData/studentData.txt' [overwrite] into table student;
说明:local加载本地数据文件
overwrite 是否覆盖表中的数据
修改表
ALTER TABLE name RENAME TO new_name
ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...])
ALTER TABLE name DROP [COLUMN] column_name
ALTER TABLE name CHANGE column_name new_name new_type
ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])
删除表
hive> DROP TABLE IF EXISTS student;
分区表
hive> create table partition_people(id int,name string,age int,address string)
partitioned by (dq string)
row format delimited fields terminated by ','
stored as sequencefile;
说明:
partitioned by (dq string) 按照dq进行分区
row format delimited fields terminated by ','; 按照”,”进行分割
stored as sequencefile; #用哪种方式存储数据,sequencefile是hadoop自带的文件压缩格式
新增分区
hive> alter table partition_people add partition(dq='shanghai');
加载数据
hive> load data local inpath '/home/testData/people.txt' overwrite into table partition_people partition(dq='shanghai');
重命名分区
hive> ALTER TABLE employee PARTITION (year=’1203’)
> RENAME TO PARTITION (Yoj=’1203’);
删除分区
hive> ALTER TABLE employee DROP [IF EXISTS]
> PARTITION (year=’1203’);
桶表
桶表是对数据进行哈希取值,然后放到不同文件中存储。
Hive数据模型外部表
指向已经在 HDFS 中存在的数据,可以创建 Partition
它和内部表 在元数据的组织上是相同的,而实际数据的存储则有较大的差异
内部表的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除
外部表 只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个 外部表 时,仅删除该链接