R绘图 vs Python绘图(散点图、折线图、直方图、条形图、箱线图、饼图、热力图、蜘蛛图)
写在前面:为啥不用excel绘制这些图,用PoweBI,帆软BI等可视化软件来绘图,不是更方便吗?的确,这些工具都很方便,但同时,它们显得很呆,不够灵活,更为致命的是,它们绘制出的图形,分辨率不够,用来出版论文,是不合格的。所以,要做学术的朋友,对R,Python可视化绘图感兴趣的朋友,不妨下点功夫将这些技术学到手。
我之所以,将自己花费4个晚上,8个小时整理出来的文档分享出来,无非是为了减少大家学习技术的时间,我深知入门一种语言的艰辛,因为我在学习的时候,也是网上各种找资料,一个软件下载安装完毕,花费大半天的时间,当初学习一门语言的激情都走了大半;所以,希望大家能够快速上手,将时间花费在能真正提高技术的地方,比如设置图形的颜色,宽度,线条,灵活的修改图形等方面,这也是我接下来要研究的。
看在我这么辛苦的份上,看完不妨点个赞。。。文章最后放本文所需要的软件安装过程链接,用R与Python绘制中国地图,某省地图,以及可视化技术的介绍。。。
本文要绘制的图形以及如何使用这些图形:散点图、折线图、直方图、条形图、箱线图、饼图、热力图、蜘蛛图、二元变量分布和成对关系。
用R绘图
软件:w10版Rstudio
条形图通过垂直的或水平的条形展示了类别型变量的分布(频数)。
> install.packages("vcd")
> library(vcd)
> counts<-table(Arthritis$Improved)
> counts
None Some Marked
42 14 28
> barplot(counts,main="简单的条形图",xlab="Improvement",ylab="Frequency")
> counts<-table(Arthritis$Improved,Arthritis$Treatment)
> counts
Placebo Treated
None 29 13
Some 7 7
Marked 7 21
> plot(counts,main="堆砌条形图",xlab="Treatment",ylab="Frequency",col=c("red","yellow","green"))
> barplot(counts,main="堆砌条形图",xlab="Treatment",ylab="Frequency",col=c("red","yellow","green"),legend=rownames(counts))
> barplot(counts,main="分组条形图",xlab="Treatment",ylab="Frequency",col=c("red","yellow","green"),beside=T,legend=rownames(counts))
> states<-data.frame(state.region,state.x77)
> means<-aggregate(states$Illiteracy,by=list(state.region),FUN=mean)
> means<-means[order(means$x),]
> barplot(means$x,names.arg=means$Group.1)
> title("均值条形图")
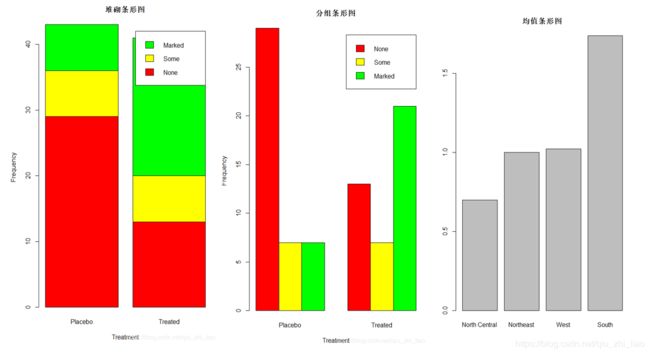
使用中注意:我用plot()与barplot()绘制的堆砌条形图并不一样!!!要想使得条形图“横着放”,barplot()函数中加上horiz=T
在绘图堆砌条形图时,使用table()函数将数据表格化,之所以使用table()是为了防止类别型变量不是因子,本例中Arthritis$Improved是一个因子。
散点图的英文叫做 scatter plot,它将两个变量的值显示在二维坐标中,非常适合展示两个变量之间的关系。
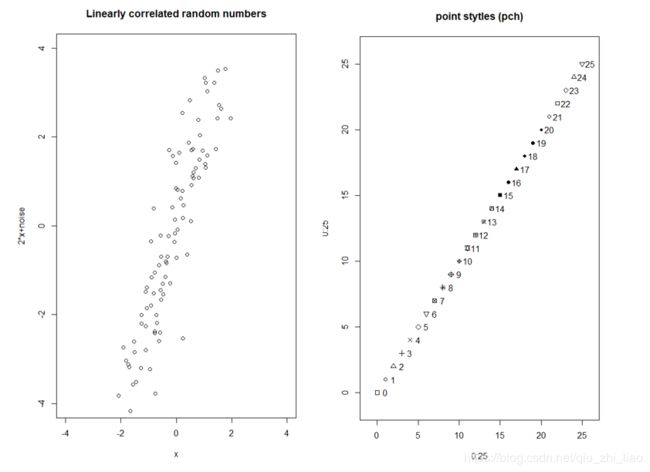
> x<-rnorm(100)
> y<-2*x+rnorm(100)
> plot(x,y,main="Linearly correlated random numbers",xlab="x",ylab="2*x+noise",xlim=c(-4,4),ylim=c(-4,4))
> plot(0:25,0:25,pch=0:25,xlim=c(-1,26),ylim=c(-1,26),main="point stytles (pch)")
> text(0:25+1,0:25,0:25)
> plot(x,y,pch=ifelse(x*y>1,16,1),main="scatter plot with conditional point styles")
> z<-sqrt(1+x^2)+rnorm(100)
> plot(x,y,pch=1,xlim=range(x),ylim=range(y,z),xlab="x",ylab="values")
> points(x,z,pch=17)
> title("scatter plot with two series")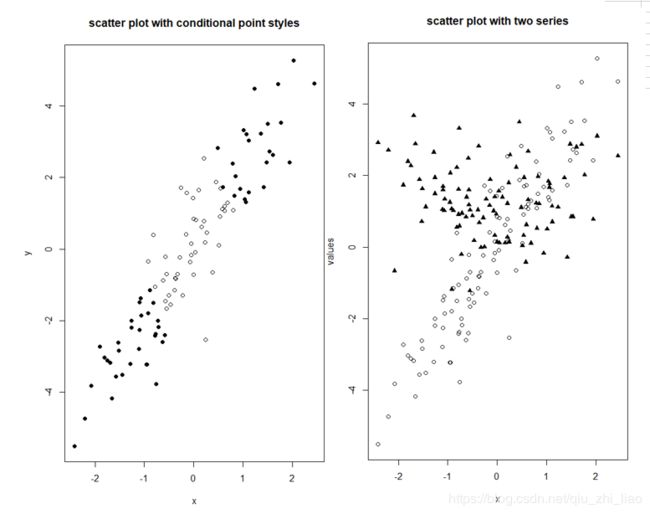
R语言有向量(python中没有),pch是向量,控制点的类型。col也是向量,控制点的颜色
> plot(x,y,pch=16,col="blue",main="scatter plot with blue points")
> plot(x,y,pch=16,col=ifelse(y>=mean(y),"red","green"),main="scatter plot with conditional colors")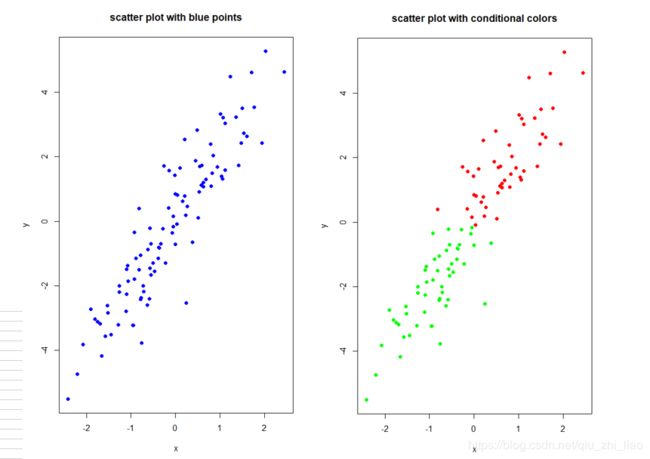
有没有一幅图中显示x,y的关系,x,z的相关关系了?(看我这么贴心,你们要是不点赞收藏,好好看都对不起我)
> plot(x,y,pch=16,col=ifelse(y>=mean(y),"red","green"),main="scatter plot with conditional colors")
> plot(x,y,col="blue",pch=0,xlim=range(x),ylim=range(y,z),xlab="x",ylab="value")
> points(x,z,col="red",pch=1)
> title("scatter plot with two series")
> t<-1:50
> y<-3*sin(t*pi/60)+rnorm(t)
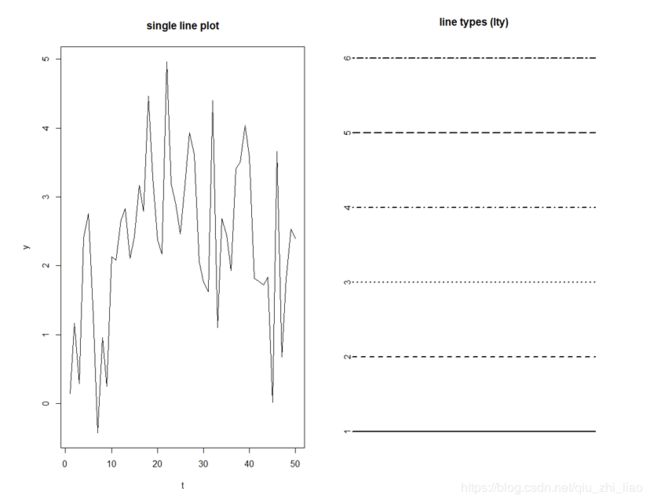
> plot(t,y,type="l",main="single line plot")
> lty_values<-1:6
> plot(lty_values,type="n",axes=F,ann=F)
> abline(h=lty_values,lty=lty_values,lwd=2)
> mtext(lty_values,side=2,at=lty_values)
> title("line types (lty)")
> p<-40
> plot(t[t<=p],y[t<=p],col="red",type="l",xlim=range(t),xlab="t")
> lines(t[t>=p],y[t>=p],col="blue",lty=2)
> plot(y,type="l")
> points(y,pch=16)

> x<-1:30
> y<-2*x+6*rnorm(30)
> z<-3*sqrt(x)+8*rnorm(30)
> plot(x,y,type="l",ylim=range(y,z),col="black")
> points(y,pch=15)
> lines(z,lty=2,col="blue")
> points(z,pch=16,col="blue")
> title("plot of two series")
> legend("topleft",legend=c("y","z"),col=c("black","blue"),lty=c(1,2),pch=c(15,16),cex=0.8,x.intersp = 0.5,y.intersp=0.8)
> barplot(1:10,names.arg =LETTERS[1:10])
> data("flights",package="nycflights13")
> carriers<-table(flights $carrier)
> sorted_carriers<-sort(carriers,decreasing=T)
> barplot(head(sorted_carriers,8),ylim=c(0,max(sorted_carriers)*1.1),xlab="carrier",ylab="flights",main="top 8 carriers with the most flights in record")

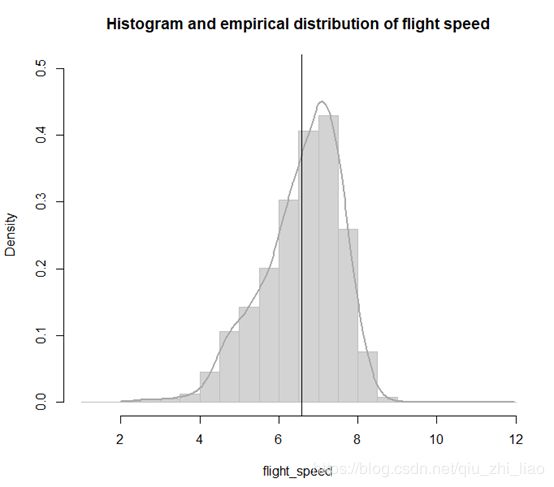
> hist(flight_speed,probability = T,ylim=c(0,0.5),main="Histogram and empirical distribution of flight speed",border="gray",col="lightgray")
> lines(density(flight_speed,from=2,na.rm=T),col="darkgray",lwd=2)
> abline(v=mean(flight_speed,na.rm=T,col="blue",lty=2))
Hist():画出flight_speed的柱状图
Density():估计飞行速度的经验分布,并在上面绘制光滑的概率分布曲线
Abline():绘制飞行速度的平均水平线
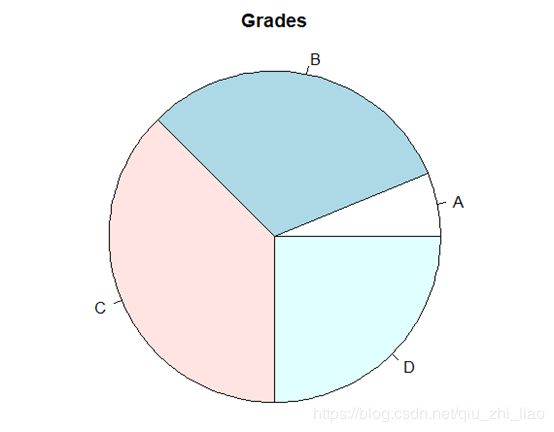
> grades<-c(A=2,B=10,C=12,D=8)
> pie(grades,main="Grades",radius=1)
boxplot(distance/air_time~carrier,data=flights,main="box plot of light speed by carrier")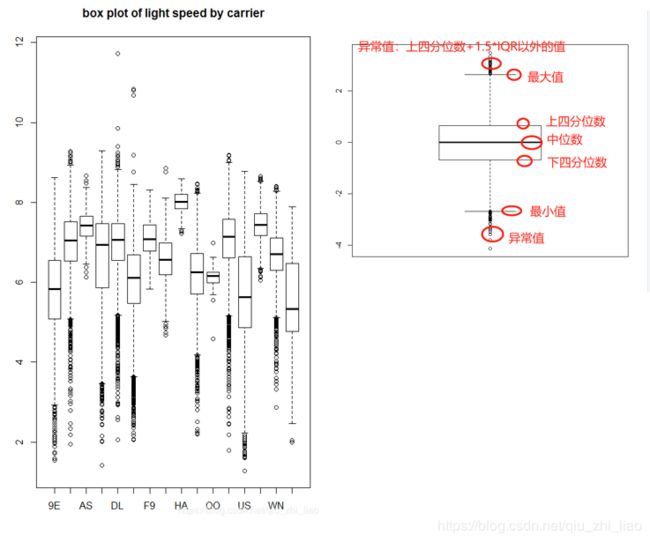
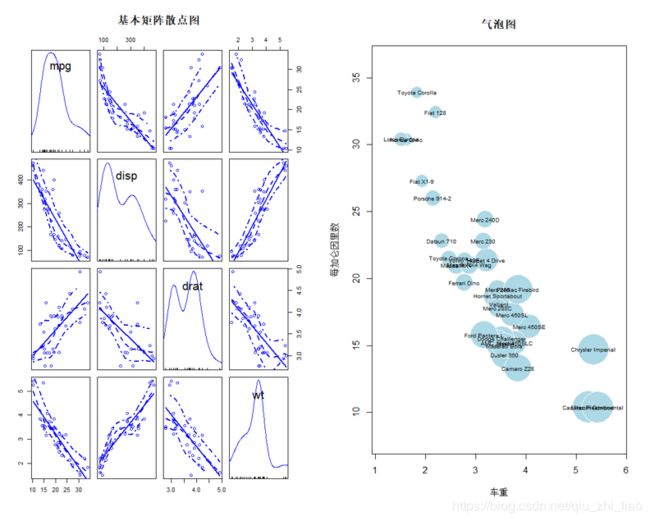
散点图矩阵&气泡图
散点图矩阵:可以看到线性和平滑(loess)拟合曲线被默认添加,主对角线处添加了核密度曲 线和轴须图。spread = FALSE选项表示不添加展示分散度和对称信息的直线,lty.smooth = 2设定平滑(loess)拟合曲线使用虚线而不是实线。
气泡图:我们避免用三维散点图的表达;先创建一个二维散点图,第三个变量用气泡大小表示。
你可用symbols()函数来创建气泡图。该函数可以在指定的(x, y)坐标上绘制圆圈图、方形 图、星形图、温度计图和箱线图。以绘制圆圈图为例: symbols(x,y,circle=radius);x,y表示坐标,circle表示圆半径。如果你想要用面积而不是半径来表示第三个变量,(r=sqrt(s/pi) )变 换即可:
在气泡图中,x轴代表车重,y轴代表每加仑英里数,气泡大 小代表发动机排量
> attach(mtcars)
> library(car)
> scatterplotMatrix(~mpg+disp+drat+wt,data=mtcars,spread=F,lty.smooth=2,main="基本矩阵散点图")
> attach(mtcars)
> r<-sqrt(disp/pi)
> symbols(wt,mpg,circles = r,inches=0.3,fg="white",bg="lightblue",main="气泡图",xlab="车重",ylab="每加仑因里数")
> text(wt,mpg,rownames(mtcars),cex=0.6)
Python绘图
软件环境:
如果说通过直方图可以看到变量的数值分布,那么条形图可以帮我们查看类别的特征。在条形图中,长条形的长度表示类别的频数,宽度表示类别。
在 Matplotlib 中,我们使用 plt.bar(x, height) 函数,其中参数 x 代表 x 轴的位置序列,height 是 y 轴的数值序列
在 Seaborn 中,我们使用 sns.barplot(x=None, y=None, data=None) 函数,参数 data 为 DataFrame 类型,x、y 是 data 中的变量。
import matplotlib.pyplot as plt
import seaborn as sns
# 数据准备
x = ['Cat1', 'Cat2', 'Cat3', 'Cat4', 'Cat5']
y = [5, 4, 8, 12, 7]
# 用 Matplotlib 画条形图
plt.bar(x, y)
print (plt.show())
# 用 Seaborn 画条形图
sns.barplot(x, y)
print (plt.show())
散点图
画散点图,需要使用 plt.scatter(x, y, marker=None) 函数。marker 代表了标记的符号。比如“x”、“>”或者“o”。
除了 Matplotlib 外,你也可以使用 Seaborn 进行散点图的绘制。使用 sns.jointplot(x, y, data=None, kind=‘scatter’) 函数,data 就是我们要传入的数据,一般是 DataFrame 类型;kind 这类我们取 scatter,代表散点的意思
import numpy as np
import pandas as pd
# 数据准备
N = 1000
x = np.random.randn(N)
y = np.random.randn(N)
# 用 Matplotlib 画散点图
plt.scatter(x, y,marker='x')
plt.show()
# 用 Seaborn 画散点图
df = pd.DataFrame({'x': x, 'y': y})
sns.jointplot(x="x", y="y", data=df, kind='scatter');
plt.show()

折线图可以用来表示数据随着时间变化的趋势。
在 Matplotlib 中,我们可以直接使用 plt.plot() 函数,当然需要提前把数据按照 x 轴的大小进行排序,要不画出来的折线图就无法按照 x 轴递增的顺序展示。
在 Seaborn 中,我们使用 sns.lineplot (x, y, data=None) 函数,data 就是我们要传入的数据,一般是 DataFrame 类型。
# 数据准备
x = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019]
y = [5, 3, 6, 20, 17, 16, 19, 30, 32, 35]
# 使用 Matplotlib 画折线图
plt.plot(x, y)
plt.show()
# 使用 Seaborn 画折线图
df = pd.DataFrame({'x': x, 'y': y})
sns.lineplot(x="x", y="y", data=df)
plt.show()

直方图是比较常见的视图;
在 Matplotlib 中,我们使用 plt.hist(x, bins=10) 函数,其中参数 x 是一维数组,bins 代表直方图中的箱子数量,默认是 10。
在 Seaborn 中,我们使用 sns.distplot(x, bins=10, kde=True) 函数。参数 x 是一维数组,bins 代表直方图中的箱子数量,kde 代表显示核密度估计,默认是 True.核密度估计是通过核函数帮我们来估计概率密度的方法。
# 数据准备
a = np.random.randn(100)
s = pd.Series(a)
# 用 Matplotlib 画直方图
plt.hist(s)
plt.show()
# 用 Seaborn 画直方图
sns.distplot(s, kde=False)
plt.show()
sns.distplot(s, kde=True)
plt.show()

饼图饼图是常用的统计学模块,可以显示每个部分大小与总和之间的比例。在 Matplotlib 中,我们使用 plt.pie(x, labels=None) 函数,其中参数 x 代表要绘制饼图的数据,labels 是缺省值,可以为饼图添加标签。
# 数据准备
nums = [25, 37, 33, 37, 6]
labels = ['High-school','Bachelor','Master','Ph.d', 'Others']
# 用 Matplotlib 画饼图
plt.pie(x = nums, labels=labels)
plt.show()

箱线图,又称盒式图,它是在 1977 年提出的,由五个数值点组成:最大值 (max)、最小值 (min)、中位数 (median) 和上下四分位数;它可以帮我们分析出数据的差异性、离散程度和异常值等。
在 Matplotlib 中,我们使用 plt.boxplot(x, labels=None) 函数
在 Seaborn 中,我们使用 sns.boxplot(x=None, y=None, data=None) 函数;参数 data 为 DataFrame 类型,x、y 是 data 中的变量。
# 数据准备
# 生成 0-1 之间的 10*4 维度数据
data=np.random.normal(size=(10,4))
lables = ['A','B','C','D']
# 用 Matplotlib 画箱线图
plt.boxplot(data,labels=lables)
plt.show()
# 用 Seaborn 画箱线图
df = pd.DataFrame(data, columns=lables)
sns.boxplot(data=df)
plt.show()

热力图是一种非常直观的多元变量分析方法。
我们一般使用 Seaborn 中的 sns.heatmap(data) 函数,其中 data 代表需要绘制的热力图数据。
# 数据准备
flights = sns.load_dataset("flights")
data=flights.pivot('year','month','passengers')
# 用 Seaborn 画热力图
sns.heatmap(data)
plt.show()

蜘蛛图
蜘蛛图是一种显示一对多关系的方法。在蜘蛛图中,一个变量相对于另一个变量的显著性是清晰可见的。假设我们想要给王者荣耀的玩家做一个战力图,指标一共包括推进、KDA、生存、团战、发育和输出。那该如何做呢?
这里我们需要使用 Matplotlib 来进行画图,首先设置两个数组:labels 和 stats。他们分别保存了这些属性的名称和属性值。
因为需要计算角度,所以我们要准备 angles 数组;又因为需要设定统计结果的数值,所以我们要设定 stats 数组。并且需要在原有 angles 和 stats 数组上增加一位,也就是添加数组的第一个元素。
代码中 flt.figure 是创建一个空白的 figure 对象---画幕布 ;add_subplot(111) 可以把画板划分成 1 行 1 列;
再用 ax.plot 和 ax.fill 进行连线以及给图形上色。
Matplotlib 对中文的显示不是很友好,我在网上下载了中文字体;(记得记载包from matplotlib.font_manager import FontProperties
,否则报错!!!)
# 数据准备
from matplotlib.font_manager import FontProperties
labels=np.array([u" 推进 ","KDA",u" 生存 ",u" 团战 ",u" 发育 ",u" 输出 "])
stats=[83, 61, 95, 67, 76, 88]
# 画图数据准备,角度、状态值
angles=np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats=np.concatenate((stats,[stats[0]]))
angles=np.concatenate((angles,[angles[0]]))
# 用 Matplotlib 画蜘蛛图
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)
# 设置中文字体
font = FontProperties(fname=r"C:\Windows\Fonts\simhei.ttf", size=14)
ax.set_thetagrids(angles * 180/np.pi, labels, FontProperties=font)
plt.show()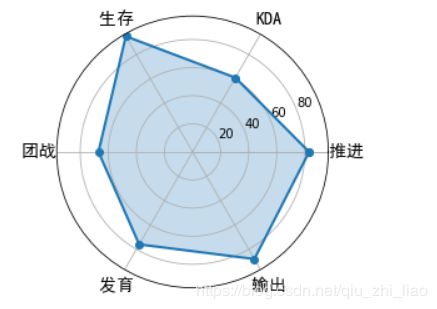
散点图,核密度图,Hexbin 图
如果我们想要看两个变量之间的关系,就需要用到二元变量分布。散点图就是一种二元变量分布。
在 Seaborn 里,使用二元变量分布是非常方便的,直接使用 sns.jointplot(x, y, data=None, kind) 函数即可。其中用 kind 表示不同的视图类型:“kind=‘scatter’”代表散点图,“kind=‘kde’”代表核密度图,“kind=‘hex’”代表 Hexbin 图,它代表的是直方图的二维模拟。
# 数据准备
tips = sns.load_dataset("tips")
print(tips.head(10))
# 用 Seaborn 画二元变量分布图(散点图,核密度图,Hexbin 图)
sns.jointplot(x="total_bill", y="tip", data=tips, kind='scatter')
sns.jointplot(x="total_bill", y="tip", data=tips, kind='kde')
sns.jointplot(x="total_bill", y="tip", data=tips, kind='hex')
plt.show()
散点图矩阵
如果想要探索数据集中的多个成对双变量的分布,可以直接采用 sns.pairplot() 函数。它可以说是探索性分析中的常用函数,可以很快帮我们理解变量对之间的关系。
pairplot 函数的使用,就像在 DataFrame 中使用 describe() 函数一样方便!!!
在这里,直接使用anaconda自带包中的数据;
# 数据准备
iris = sns.load_dataset('iris')
# 用 Seaborn 画成对关系
sns.pairplot(iris)
plt.show()
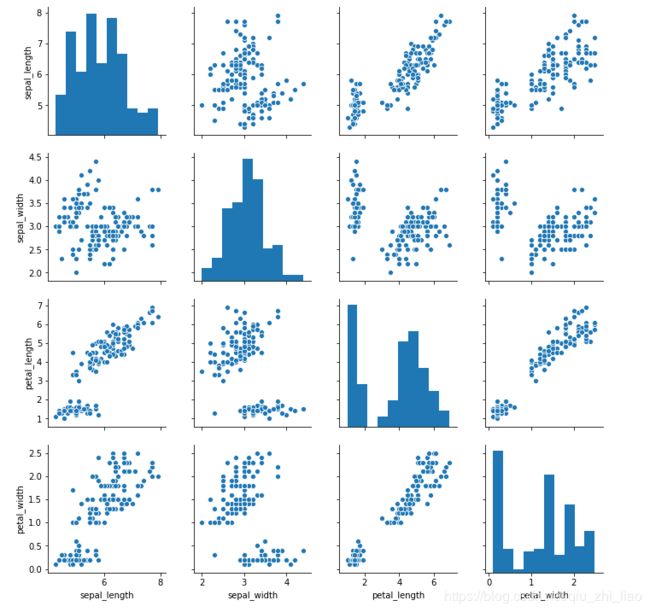
如何描述这幅图:只看右上角就行,(与左下角对称)横轴找一个变量,纵轴找一个变量,图形就显示二者间的相关关系。
总结: Python 可视化工具包 Matplotlib 和 Seaborn 工具就好比 NumPy 和 Pandas 的关系。Seaborn 是基于 Matplotlib 更加高级的可视化库。
如果你想设置修改颜色、宽度等视图属性。你可以看之后,我写的文档(相信我一定会放的,毕竟在学习的路上,不能停)。也可以在网上自己学习相关函数文档。
“老弟,来了”。能看到这里,我为你手动点个赞,感谢大家。
可视化技术:https://www.zhihu.com/people/wu-shu-cheng-12/answers
用PYTHON绘制中国地图VS用R绘制中国地图:https://blog.csdn.net/qiu_zhi_liao/article/details/85564131
R就使用Rstudio,安装起来非常方便,快速,一个轻量型的R可以做到如此贴心的地步,默默为R点个赞。(切记,先装R,再Rstudio)
https://www.zhihu.com/question/63466456/answer/432176729
PYTHON的话建议使用Anaconda:因为它很大,库很多,一旦下载,方便新手操作!(500多M的样子)
- Anaconda 安装管理:https://www.zhihu.com/collection/236101838
- Jupyter notebook 安装管理:https://www.zhihu.com/collection/236101838