用简单的方式讲scrapy-redis爬虫分布式策略
文章目录
- 1. 习惯性唠叨点啥
- 2. 分布式爬虫策略
- 3. 致谢
1. 习惯性唠叨点啥
晨曦无限好、温暖如春、温暖你我的心
冬去春已来,但是感觉最近北京的春风它并不是把春天送到我们的身边来,而是巴不得要把春天赶跑。风很大、天很蓝、太阳很足! 北京有句老话叫“春脖子短”,当你正感受到它的到来时,它可能就要一闪而过了

2. 分布式爬虫策略
作为一名以爬虫开发为职业的工程师来讲的话,在开发爬虫的过程中。很多业务场景需要采集的站往往让我们异想不到,因为它不仅站多而且量还大。很多时候我们都是在自己的机器上开发爬虫,为了发挥爬虫的效率我们也经常会用到多进程、多线程来提升我们爬虫的效率!但是可能在职业生涯中大部分站由于数据量不是很大我们总是选择了单机爬虫的方式。
针对一些小站的话,单机Scrapy爬虫方式完全够用,杀鸡焉用牛刀?
针对一些大站的话,这个时候可能就显得有些无力了。这个时候如果你还是继续选择单机Scrapy采集…过了几天后…
老大或者老板:嗨!采集的怎么样了?数据都采集完了吧?
你说:这个网站数据量真的是巨大啊!我都跑了三天三夜了。正采集着呢!放心吧,我刚初步瞄了一下应该再采三天三夜基本就差不多了!说到这里!
Ta可能扛着40米的牛刀正朝你走来…
本期聊点什么呢?根据之前自己对源码的一些探测跟一些官方资料及自身使用的感受,我们就来聊聊关于爬虫分布式的那点事可好?所以本期聊盘一下分布式爬虫策略。说到分布式爬虫开发及部署,很多人都会联想到Scrapy-redis
某爬虫“大佬”:Scrapy-redis这个框架我用过、我经常用!很好、很强大!

NO!哦买噶!他刚刚说了什么?他跟我说Scrapy-redis是一个框架!可是实际上Scrapy-redis它并不是一个框架!也不是一套什么可以单独运行的东西(要考的哦!)它其实是一套基于Scrapy框架之上的一套组件,它是一个提供可以支持分布式的组件,Scrapy-redis重写了Scrapy一些比较关键的代码,从而用来替换Scrapy本身的一些东西,让Scrapy拥有了支持分布式的功能。
如果没有使用Scrapy-redis而开启多个Scrapy爬虫以为它就能帮助我们达到分布式的效果或者达到高速采集的话这个是个错误的想法!这样做的话第一它的数据重复采集的,因为多个进程之间的内存是不能共享的,所以它们都不知道对方采集了哪些没采集哪些!其实都是自己在玩自己的,怎来效率一说。
其实!最终说到底。Scrapy它不支持分布式主要就是请求、去重都是基于自身内存而不是共享的!所以Scrapy-redis到底做了什么从而让Scrapy支持分布式供能的呢?它将Scrapy中的调度器组件单独抽出来放到了一个大家都能共享的地方!我简单的画一个草图让它更直观一些,大家也能更好的理解Scrapy-redis它的角色
不止做爬虫的小伙伴知道Scrapy,很多人都知道Scrapy它是一个通用的爬虫框架,但是呢!并不能支持分布式。而Scrapy-redis则是为了更方便的实现Scrapy分布式采集而提供了以redis为基础的组件(所以呢!这些组件必须跟Scrapy结合在一起才能用起来)
这套组件的核心就是Redis数据库!数据会统一放到Redis数据库,主要由Master端分配任务,Slaver端也就是我们的各个爬虫端负责采集数据,并且将所有采集的的数据最后全部提交到Master端的redis数据库里。所有的爬虫端它们共享一个redis数据库,说到这里,你拥有它了吗?:
pip install scrapy-redis
Scrapy-redis它主要提供了以下四种组件,这四个组件呢!其实就是替换了原来的Scrapy本身的组件(同时也意味着这四个模块都要做一些修改):
- Scheduler
- Duplication Filter
- Item Pipeline
- Base Spider
- 首先就是调度器Scheduler
Scrapy改造了Python本来的Collection.deque形成了自己的Scrapy,但是Scrapy多个Spider不能共享待采集队列Scrapy.queue,即Scrapy本身不支持分布式,所以Scrapy-redis的作用就是解决就是把这个Scrapy队列换成redis数据库(也就是redis队列)。从同一个redis-server存放要采集的request,便能多个spider去同一个数据库读取 - 然后就是去重Duplication Filter
做过爬虫开发的工程师都知道Scrapy本身是有去重机制的,它的去重主要是在内存中执行的。但是呢!如果我们的请求数到一定量级的时候,会发现Scrapy内存占用非常高!所有在这里我们把这些去重的指纹放到redis数据库里那不仅更方便了,而且还能做持久化!
其实在Scrapy本身中用集合实现的request去重功能,Scrapy中已经发送的request指纹放入到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在指纹中,说明这个request发送过,如果没有则继续操作,这个核心的去重功能是这样实现的:
class RFPDupeFilter(BaseDupeFilter):
"""Request Fingerprint duplicates filter"""
def __init__(self, path=None, debug=False):
self.file = None
self.fingerprints = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
#打开去重文件requests.seen
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
@classmethod
def from_settings(cls, settings):
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(job_dir(settings), debug)
def request_seen(self, request):
# self.request_fingerprint就是一个指纹集合
fp = self.request_fingerprint(request=request)
# 这就是去重的核心操作
if fd in self.fingerprints:
return True
# 添加到集合中
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
在Scrapy-redis中去重由Duplication Filter组件来实现的,它通过redis的set不重复的特性,巧妙的实现了Duplication Filter去重功能。Scrapy-redis调度器从引擎接受request,将request的指纹存入redis的set检查是否重复,并将不重复的request push写入redis的request queue
引擎请求request(Spider发出的)时,调度器从redis的requestqueue队列里面根据优先级pop出一个request返回给引擎,引擎将此request发给spider处理
举个栗子: 我们现在有一个爬虫,它已经运行采集了一段时间,但是这个时候呢,可能因为人为操作或者异常情况导致它中断了。那么我们再执行的时候它会接着读取redis数据库里面的请求指纹,之前采集过的它自然就不会再去发送了。如果这个爬虫我们用Scrapy来做的话,它就不能像以上情况一样,一旦中断内存就会被清空了,再次采集就要从头继续了!也就是说一招回到解放前…
- 第三个就是管道文件这块Item Pipeline
它也提供了一套模板,我们都知道之前在Scrapy里面数据都是直接交给管道文件最后进行存储操作的。那现在呢?这个数据不再是交给管道了,而是交到redis数据库统一管理。最后取提取我们的数据也是有一套模板从redis数据库抽取存储到我们本地的数据库系统或文件系统做一个持久化!因为redis它也是基于内存,万一哪一天你关机也会清空 - 第四个就是我们爬虫的类也会改变Base Spider
Scrapy原生的框架有两个类:Spider、CrawlSpider。这两个类在scrapy-redis里面也会做修改。它会被修改成以redis为核心的两个爬虫类!不再使用Scrapy原有的Spider类,重写的RedisSpider继承Spider和RedisMixin这两个类!RedisMixin是从redis读取url的类
当我们生成一个Spider继承RedisSpider时,调用setup_redis函数,这个函数会去连接redis数据库,然后会设置signals:
- 一个是当spider空闲时候的signal,会调用spider_idle函数,这个函数调用schedule_next_request函数,保证spider是一直活着的状态,并且抛出DontCloseSpider异常。
- 一个是当抓到一个item的signal,会调用item_scraped函数,这个函数也会调用schedule_next_request获取下一个request。
我们来看看官方的Scrapy-redis架构图,做一些详细的梳理:
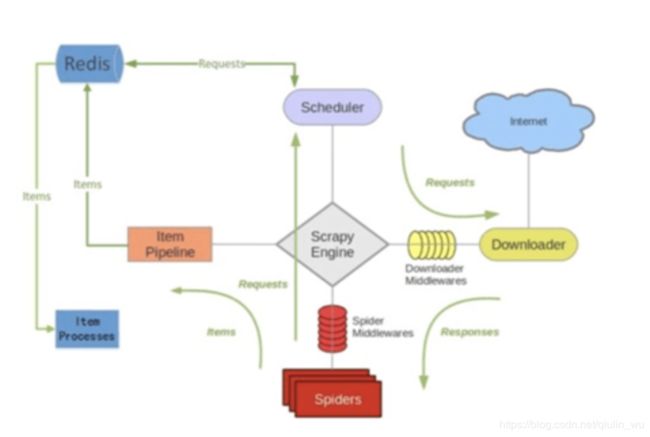
首先!我们可以看到在Scrapy-redis架构图中调度器将所有的请求不再放到下载器里面,而是放到redis数据库里面。redis数据库分别放有存数据、存请求队列、存请求指纹的三个库!那么这些请求发松到redis数据库里面首先要做什么呢?你知道吗?当然是先做一个指纹比对,确定这个请求之前有没有被收集过(每个request到redis数据库里面都会留下一个指纹)
请求全部进到队列之后,然后redis数据库会把这些请求再挨个出队列,交给调度器,这个时候调度器才会把请求交给下载器去下载。也就是说!原来这个调度器进的这个Scrapy框架的调度会把请求打到Scrapy本身的请求队列里,Scrapy它也有自己的去重,最后再交给下载器去下载。但是现在统一交给了redis数据库!
另外指纹到底是什么呢?问得很好!
听这个字面意思可能很多人至少都判断出它是唯一的,毕竟我们人类本身的手指指纹不就是嘛,我以前看的那些什么警匪片,在犯罪现场警察叔叔都会带上手套在那里细心收集着什么,那就是在收集犯罪份子遗留在现场的证据痕迹其中就包括指纹。其实指纹在这里的意思就是如果请求URL资源位置是同样的话,那么这个指纹就是相同的。如果redis数据库之前的一个指纹存在那么新增的就会被舍弃!
另外在Scrapy中个跟“待爬队列”直接相关的就是调度器Scheduler它负责对新的request进行入列操作(加入到Scrapyqueue),取出下一个要采集的request等操作。它把待采集队列按照优先级建立了一个字典结构,如下:
{
优先级0:队列0
优先级1:队列1
优先级2:队列2
}
根据request中的优先级,来决定该入哪个队列,出列时则按优先级较小的优先出列,再来看看Scrapy中的Scheduler:
def enqueue_request(self, request):
"""add一个请求到队列"""
# 负责检查request是否已被请求 如果是则返回True
if not request.dont_filter and self.df.request_seen(request):
# 如果request的dont_filter我们没有设置True则去重,不进队列
self.df.log(request, self.spider)
return False
# 将request add到磁盘队列
dqok = self._dqpush(request)
if dqok:
# 如果成功 记录一次状态
self.stats.inc_value('scheduler/enqueued/disk', spider=self.spider)
else:
# 不能add到磁盘队列则会add到内存队列
self._mqpush(request)
self.stats.inc_value('scheduler/enqueued/memory', spider=self.spider)
self.stats.inc_value('scheduler/enqueued', spider=self.spider)
return True
def next_request(self):
"""从队列中获取一个request"""
# 优先从内存的队列中pop
request = self.mqs.pop()
if request:
self.stats.inc_value('scheduler/dequeued/memory', spider=self.spider)
else:
# 不能获取的时候从磁盘队列队里获取
request = self._dqpop()
if request:
self.stats.inc_value('scheduler/dequeued/disk', spider=self.spider)
if request:
self.stats.inc_value('scheduler/dequeued', spider=self.spider)
# 最后再将获取到的request返回给引擎
return request
为了管理这个比较高级的队列字典,Scheduler需要提供一系列的方法。但是原来的Scheduler已经无法使用,所以使用Scrapy-redis的Scheduler组件
管道文件这里我再细说一下!如果我们单独写的Scrapy爬虫项目,数据在管道里面比如我们存到本地JSON或者本地数据库都可以在管道文件里面写。但是现在这个管道文件我们可以写!也可以不写!为什么呢?因为如果写的话,就不能再做修改或者把数据再存储到我们的本地!当然你如果非要这么做也是可以存储到本地的,因为它毕竟要经过管道文件这一块,但是!这样做的话就失去了分布式的意义了!
这样做的话,我们的数据没有做集中存储,最后都存储在各个爬虫端,如果我们个人或者公司的爬虫项目部署在不同的地区,美国那边有几个,香港那边有几个,菲律宾也有几个…最后如果都存储在爬虫端的话,后期再集中整合也是非常费劲的一件事!(如果我们爬虫架构这么干的话估计第二天就要…哈哈。所有千万不能这么干)
所以我们统一存储在redis数据库最后再单独写一个ItemProcesses把它们抽取出来!当然也可以不拿,一直放在redis数据库里,但是这种luo奔的方式还是有较高的风险系数,因为迟早有一天这些数据会丢失(嘘!baby,我们一起让时间说真话,好吗?)
这就是Scrapy-redis这套组件的整体流程跟一些策略以及它跟原生的Scrapy之间的一些区别。其实它跟原生的scrapy框架流程不一样的只是所有调度都以redis组件为核心来展开!
3. 致谢
好了,到这里又到了跟大家说再见的时候了。我只是一个会写爬虫的段子手而已,一个希望有朝一日能够实现财富自由,能够早日荣归故里的游子罢了。希望我的文章能带给您知识,带给您欢笑!同时也谢谢您能抽出宝贵的时间阅读,创作不易,如果您喜欢的话,点个关注再走吧。您的支持是我创作的动力,希望今后能带给大家更多优质的文章