Diffbot号称排名第一的网页智能解析真有那么强大嘛?
文章目录
- 前言
- 1. 什么是智能解析
- 2. Diffbot是什么
- 3. 如何使用Diffbot
- 4. 总结
- 5. 致谢
前言
很多爬虫开发者在职业生涯中做得最多的一件事我想应该就是写parse。有时候面对不同的网站重复写着大量的解析规则是非常耗时的,像一些新闻网站难道没有通用的解析算法或者规则吗?有!比如可能很多爬虫工程师都用过的newspaper
但是它的主战场毕竟是英文类的网站,中文的话…
1. 什么是智能解析
什么是智能解析呢?我们听这个语义大概能知道就是解放爬虫开发者双手写解析规则,而是针对一些页面专门写了一套提取规则,常见的可以利用一些算法来完成网页特定元素定位跟抽取路径。比如一则新闻网页,可以通过算法计算出标题是什么,正文从哪到哪,发布时间是什么以及作者在哪个位置等功能

其实吧,我这个键盘侠敲着看似简单。仿佛我的字语之中完成了一切似的。实际上在现实中这是一个非常艰巨任务,作为一个用户来说看到一篇新闻这个用户可以快速知道这篇新闻的标题是什么、发布时间是什么、哪部分是正文。如果换做没有感情的机器,它面临的是什么?我也想把我的思想给它,但是现实它不允许~
我们还暂时不能指望它能赋予人类大脑的思维,现在市面上对于智能解析的算法也有那么几款,比如我知道的:
- 基于jieba分词的newspaper
- 曾经基于模型打分的Readability
- 还有Github上基于符合密度提取的算法
- 然后就是今天说到的Diffbot了
我们可以看到的是智能解析它只是针对HTML页面做一系列的解析提取,但是要让机器去做到智能,所需要用到的知识跟技术是非常广的
曾经我们做新闻解析的时候,也使用过一些开源的解析算法。但是真正面临实际场景的时候,才知道现实总是这么无情!你会发现很多千奇百怪的数据跟页面:
- 比如新闻的正文如何才能取全?剔除与它无关的信息?
- 发布时间不同地区的网站时间呈现都是不一样的,如何智能匹配?
- 乱七八糟的特殊字符跟广告乱入的无耻行为如何检测规避?
没有网站做不到的,只有我们想不到的。我一个铁汁之前就长期负责改新闻通用的解析规则,头发都给整白了

我个人认为能做到一定水准的智能解析基本会涉及:算法、计算机视觉、NLP、机器学习等多个领域的技术。才能真正打造出附有灵魂的智能体
2. Diffbot是什么
Diffbot是国外的一家专门做智能解析服务的公司。它到底是真的有这么神奇还是吹嘘的?各位可以去Diffbot官网看一看,我其实也不知道好不好用,所以我也去注册了一个账号体验了一把它的功能。它们官方曾经做过一个评测,目标则是针对现在市面上使用较广的智能解析工具及算法,测评的结果当然是Diffbot这位大当家的独占第一咯
Diffbot自2010年以来就致力于提取 Web 页面数据,并提供许多AP 来自动解析各种页面。其拥有NLP、机器学习、视觉处理、标记检查等多种算法库
Diffbot一直致力于这一方面的服务,毕竟它就是做页面解析起家的,一直专注这个垂直的领域发展,十年磨一剑!有一定的技术积累跟实力那也是很正常的,可惜呀!没有开源,咱们可以先体验一下效果,毕竟这么多年的研究积累怎么可能让我们白嫖呢!
3. 如何使用Diffbot
但是官方还是有一个福利的,就是可以注册免费体验半个月的账号,惊得我赶紧去注册了一个账号,因为它提供API服务,所以更加便捷,注册账号获取开发者token这个是请求接口的令牌
API接口(参数使用方法等详情大家见Diffbot官方API使用文档):
https://api.diffbot.com/v3/article
我这里也是注册好了一个白嫖的账号
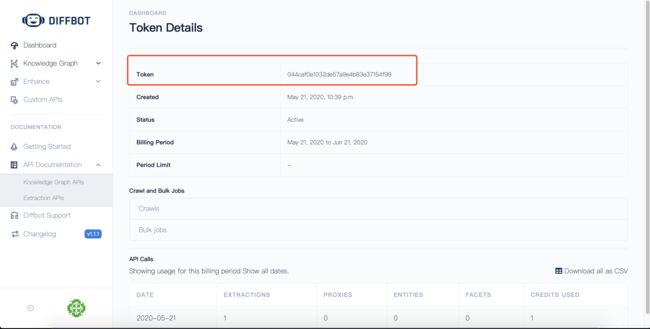
然后再找了一个新闻网站请求一下API测试一下效果:
#! coding: utf-8
import requests
import json
#Diffbot API
url = 'https://api.diffbot.com/v3/article'
params = {
'token': '044caf0e1032de57a9e4b83e37154f98',
'url': 'https://mil.news.sina.com.cn/2020-05-22/doc-iirczymk2930805.shtml',
}
response = requests.get(url, params=params)
print(json.dumps(response.json(), indent=4, ensure_ascii=False))
使用非常简单,把我们需要解析的新闻URL跟我们注册的Token两个参数丢进去(我的这个token可以直接测试,15天过后就不能白嫖了,铁汁只能帮你们到这了)
最终的效果就是数据很全,结构很清晰
我们再看看新闻中出现的图片信息数据解析效果:
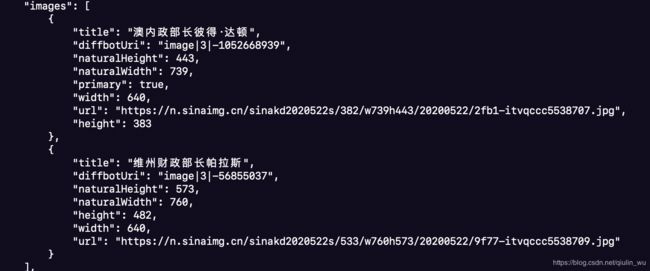
4. 总结
爱玛!花钱的东西用着就是得劲,真香!我把白嫖的Token也贡献出来了,如果你有点良心的话,别白嫖我的文章了,铁汁!
5. 致谢
好了,到这里又到了跟大家说再见的时候了。我只是一个会写爬虫的段子手而已,一个希望有朝一日能够实现财富自由,能够早日荣归故里的游子罢了。希望我的文章能带给您知识,带给您帮助,带给您欢笑!同时也谢谢您能抽出宝贵的时间阅读,创作不易,如果您喜欢的话,点个赞再走吧。您的支持是我创作的动力,希望今后能带给大家更多优质的文章