(2)source和sink详解
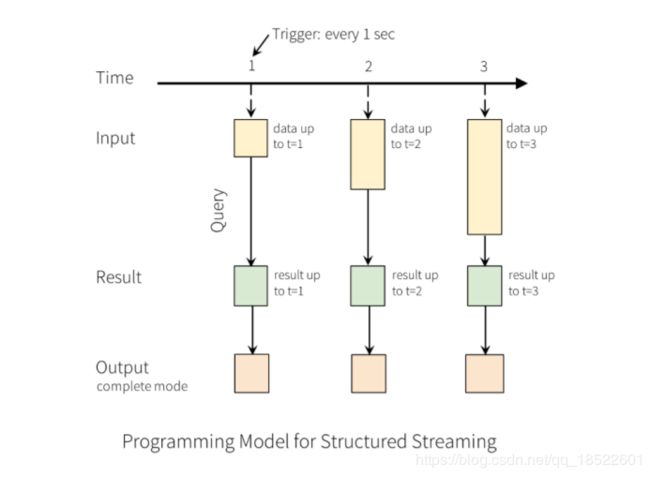
前面第一小节也提到了,Structured Streaming会增量的从source中读取数据,映射成一张表,对该表进行增量的查询分析,然后组合中间状态,再把结果输出到结果表,然后刷到外部存储系统sink。
本小节主要是详细讲解source 和 sink。
1. source
目前支持的内置source有:
1) File Source
从给定的目录读取数据,目前支持的格式有text,csv,json,parquet。容错,文件必须原子操作的方式放置到指定的目录下,很多文件系统支持的move操作即可实现。
path:输入目录,对所有的文件格式通用。
maxFilesPerTrigger:每次触发读取文件的最大数。
latestFirst:是否先处理最新加入的文件,当有很多文件时,该参数有用(默认是false)。
fileNameOnly:检测新文件是否只根据文件名称,而不是整个文件路径,默认是false。假如,该值设置为true,那么下列文件会被认为是同一个文件:
"file:///dataset.txt"
"s3://a/dataset.txt"
"s3n://a/b/dataset.txt"
"s3a://a/b/c/dataset.txt"
2) Kafka Source:从kafka拉取数据。仅兼容kafka 0.10.0或者更高版本。容错。
3) Socket Source(for testing):
从一个连接中读取UTF8编码的文本数据。不容错。
该source的配置主要是两个host 去链接的目标主机; port 去连接的目标端口。
4) Rate Source(for testing)
每秒钟产生给定行数的数据,每个输出包括一个时间戳 timestamp(Timestamp类型,代表消息分发的时间)和value(long类型,起始行是0)。该API用来测试的。
主要配置
rowsPerSecond (默认是1):每秒钟产生数据的行数。
rampUptime(默认是,0s,单位是秒,比如可以初始化为 5s):在生产速率达到rampUptime之前需要热身加速的时间。
numPartitions(),默认是spark的默认并行度。该值代表产生数据的分区数。
source将尽力达到rowsPerSecond,但查询可能受资源约束,并且可以调整numPartitions以帮助达到所需的速度。
2.output modes
创建了source dataframe和组织了相关处理逻辑之后,就剩下以Dataset.writeStream的形式将数据写入到sink。下面,是一些常用的配置:
1). 输出sink 细节:数据格式,位置等。
2). 输出模式:指定输出到sink的内容。
A)Append mode(default):仅仅从上次触发计算到当前新增的行会被输出到sink。仅仅支持行数据插入结果表后不进行更改的query操作。因此,这种方式能保证每行数据仅仅输出一次。例如,带有Select,where,map,flatmap,filter,join等的query操作支持append模式。
B)Complete mode:每次trigger都会将整个结果表输出到sink。这个是针对聚合操作的。
C) Updata mode:仅仅是自上次trigger之后结果表有变更的行会输出到sink。在以后的版本中会有更详细的信息。
3). 查询名称:指定一个便于识别的查询名称。
4). 触发间隔:可选的指定触发间隔,如果没有指定,系统在之前的处理完之后,立即检查数据可用性。如果指定了时间间隔,由于处理时间导致下次出发延迟,那么结束后会立即触发处理。
5). Checkpoint位置:对于一些支持端到端容错保证的sink,最好指定checkpoint信息。并且最好是hdfs 兼容的容错的文件系统。下面会详细讨论。
3.sinks
FileSink:保存数据到指定的目录
noAggDF
.writeStream
.format("parquet")
.option("checkpointLocation", "path/to/checkpoint/dir")
.option("path", "path/to/destination/dir")
.start() Foreach sink:可以在输出的数据上做任何操作。
writeStream
.foreach(...)
.start()Console sink(for debugging):每次trigger都会将结果输出到console或stdout。
aggDF
.writeStream
.outputMode("complete")
.format("console")
.start()memory sink:输出以一个内存表的形式保存在内存中。Append和complete模式都支持。由于数据是保存在driver端的,所以该模式适合小数据量测试。
// Have all the aggregates in an in-memory table
aggDF
.writeStream
.queryName("aggregates") // this query name will be the table name
.outputMode("complete")
.format("memory")
.start()
spark.sql("select * from aggregates").show()
kafkasink
支持stream和batch数据写入kafka
val ds = df
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.start()4.Sink支持的输出模式
| Sink |
Outputmode |
Options |
容错 |
注释 |
| FileSink |
Append |
path:输出路径,必须指定 |
Yes, 仅一次处理 |
支持写入分区表。按照时间分区或许比较好使。 |
| Kafkasink |
Append,Update,complete |
会有专题 |
YES。最少一次处理语义。 |
会有专题 |
| ForeachSink |
Append,Update,Complete |
None |
依赖于具体的ForeachWriter的实现 |
下面会有例子 |
| ConsoleSink |
Append,Complete,Update |
NumRows:每个trigger显示的行数。Truncate:假如太长是否删除,默认是true |
No |
|
| MemorySink |
Append,Complete |
None |
No.但是在Completemode 重新query就会导致重新创建整张表 |
后续sql使用的表名就是queryName |
要触发整个执行流程,必须调用start函数,该函数会返回一个StreamingQuery对象,该对象是正在运行的执行器的一个句柄。可以使用该对象来管理查询,后面详细介绍。
// ========== DF with no aggregations ==========
val noAggDF = deviceDataDf.select("device").where("signal > 10")
// Print new data to console
noAggDF
.writeStream
.format("console")
.start()
// Write new data to Parquet files
noAggDF
.writeStream
.format("parquet")
.option("checkpointLocation", "path/to/checkpoint/dir")
.option("path", "path/to/destination/dir")
.start()
// ========== DF with aggregation ==========
val aggDF = df.groupBy("device").count()
// Print updated aggregations to console
aggDF
.writeStream
.outputMode("complete")
.format("console")
.start()
// Have all the aggregates in an in-memory table
aggDF
.writeStream
.queryName("aggregates") // this query name will be the table name
.outputMode("complete")
.format("memory")
.start()
spark.sql("select * from aggregates").show() // interactively query in-memory table