Precise Detection in Densely Packed Scenes(CVPR 2019)论文解读
一、研究动机
在购物超市中,商品陈列区中摆放了密集而繁多的商品,它们大多是相同或极其相似的,并且位置十分靠近。当前主流的检测网络在这种场景下充满挑战,效果并不是很理想。本文的精确物体检测就是在这种场景基于主流检测方法,提出了以下几个方面的改进:(1)提出Soft-IoU层进行IoU的预测。(2) 引入一个基于EM算法的高斯混合聚类方法来解决探测重叠的问题。(3) 制作了公开数据集SKU-110K,并在相关的零售场景数据集中进行训练和测试,包括SKU-110K, CARPK 和PUCPR+。其与RetinaNet的探测效果对比图如下所示:


其中红框表示RetinaNet效果,蓝色表示本文的方法,©和(d)是(a)和(b)的放大图。
可见在这种场景下探测的主要难点在于怎么确认矩形框的结束和下一个并列矩形框的开始。可见RetinaNet中大多数矩形框是重叠的,而本文的方法个个分明,在精确密集检测中很有优势。
二、研究方法
Soft-IoU层预测IoU
在非密集场景中,NMS可以解决矩形框的重叠。然而,在密集检测中,多个重叠的边界框通常会映像多个紧密排列的目标,其中许多目标获得了高分数。在这种情况下,NMS不能区分重叠物体之间的缝隙,或者抑制物体的不完整检测。为了解决此问题,我们需要针对每个预测框再额外预测一个IoU,这是由一个在RPN后面添加的第三个全连接分支来完成,搭配二值交叉熵。其实,这与IoU-net的想法是一样的,既然零售场景中的密集检测关注交叠探测那么IoU就是一个很好的信息。其中IoU的损失函数如下所示:
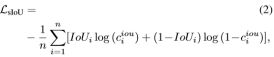
那么训练RPN的loss就由三部分组成,如下式:
![]()
基于EM算法的去交叠
我们将原始的单个物体的探测转化为以一个以探测目标为中心的簇,首先假定来自神经网络输出的N个矩形框由一系列二维高斯核产生,其中矩形框的中心是高斯核的均值,方差用来衡量矩形框的长宽。将这一系列的高斯核叠加得到了混合高斯模型,其中IoU的占比决定了高斯混合模型中的混合系数。模型的概率密度如下式:

这样就可以将其看作一个热力图,将原始的探测问题转换成了基于热力图来判定每个像素与ground truth交叠的置信度,每个区域的权重就是高斯核的混合系数,可以由Soft-IoU层的预测结果进行衡量。
不相交的矩形框探测可以采用高斯混合模型进行聚类得到,那么什么是高斯混合聚类方法,此处简要说明一下:假定我们所有最终的矩形框都是由高斯混合模型生成的,那么我们只要根据数据推出混合模型的概率分布来就可以了,然后混合模型的K个组成部分就对应了K个簇,也就是K个矩形框。因为我们的问题是需要将交叠的矩形框去重叠之后得到非交叠的部分,又因为聚类之后的簇中心代表的就是去重叠之后的矩形框中心(ground truth的中心),那么我们的簇中心必定远小于网络直接生成的N个矩形框,也就是混合模型的高斯核个数K远小于网络产生的矩形框个数。那么我们需要找到这K个高斯核混合而成的概率分布:
![]()
用KL散度来度量两个矩形框的相似度:

而我们寻找的这个由K个高斯核混合的模型是为了最小化预测框和ground truth的KL散度,而解决该最小化问题我们采用了EM的思想。首先,E步会将预测出来的每个矩形框对应到与其距离最近的簇中心如下式:

然后,M步是重新估计模型的参数:
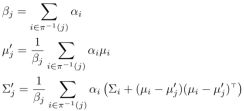
整个流程和K-means聚类差不多,聚类簇数目的选定采用层次聚类的结果,还会采用辅助手段进行验证:依据一张图片的像素面积去除以一件商品的像素面积,这种方法要求拍摄的距离固定以及商品的像素面积事先测定(感觉有点不智能啊!):
![]()
除此之外,还有一个后处理步骤用于去除一些置信度较低但是和其它高斯核交叠率超阈值(也就是距离过近KL散度过小)的高斯核,所以实际最后得到的高斯核要小于K,写为K’。
为了获取最终的探测结果,我们将网络预测的矩形框中心点落在K’个高斯核标准差以内的所有矩形框求均值作为该探测结果的中心。最后效果如下图:

构建SKU-110K标准数据集
基于商场中商品陈列区的目标检测数据集,主要是针对密集目标见检测和细粒度目标检测在零售行业的应用。
三、实验内容及分析
该方法是基于RetinaNet,在GPU加速的情况下,添加Soft-IoU和EM-Merger的速度与基础模型差不多,具体时间如下表:

其AP,MAE和RMSE指标结果如下表:

在自己提出的数据集SKU-110K上探测效果对比图如下所示:

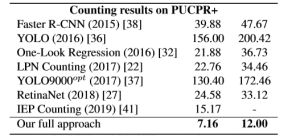
除此之外,在CARPK和PUCPR+数据集上的MAE和RMSE的结果如下表所示:

四、总结
针对实体零售场景下密集商品的探测问题构建了一个相应场景的数据集,并且发现此场景下现有的探测模型具有以下问题:目标的密集性导致大量的边框有交叠,无法做到个个分明。针对这个问题提出了两个方法来改进:增加Soft-IoU层来预测每个预测框与ground truth的IoU,并且采用高斯核替代探测框的方式构建基于EM的高斯核聚类方法从而筛选重叠的探测框。