用广义加性模型GAM进行时间序列分析
原文:http://tecdat.cn/?p=4130
每当你发现一个与时间对应的趋势时,你就会看到一个时间序列。研究金融市场表现和天气预报的事实上的选择,时间序列是最普遍的分析技术之一,因为它与时间有着不可分割的关系 - 我们总是有兴趣预测未来。
时间相关模型
一种直观的预测方法是参考最近的时间点。今天的股价可能会比昨天的价格更接近五年前的价格。因此,在预测今天的价格时,我们会比最近的价格更重要。过去和现在值之间的这些相关性表明了时间依赖性,它形成了一种流行的时间序列分析技术ARIMA(自回归整合移动平均线)的基础。ARIMA既考虑季节变化又考虑过去的一次性“冲击”以作出未来预测。
但是,ARIMA做出了严格的假设。要使用ARIMA,趋势应该有规律的时期,以及不变的均值和方差。例如,如果我们想分析一个增长的趋势,我们必须首先对趋势进行转型,使其不再增加,而是停滞不前。而且,如果我们缺少数据,ARIMA将无法工作。
为了避免将我们的数据挤压到模具中,我们可以考虑一种替代方法,如神经网络。长期短期记忆(LSTM)网络是一种基于时间依赖性建立模型的神经网络。虽然高度准确,但神经网络缺乏可解释性 - 很难确定导致特定预测的模型组件。
模型
除了使用类似时间点的值之间的相关性之外,我们可以退后一步对整体趋势进行建模。时间序列可以被看作是个体趋势的总和。举例来说,谷歌搜索柿子,一种水果的趋势。
从图1中,我们可以推断柿子可能是季节性的。随着11月份供应量达到峰值,杂货店的顾客可能会被要求谷歌营养知识或柿子食谱。
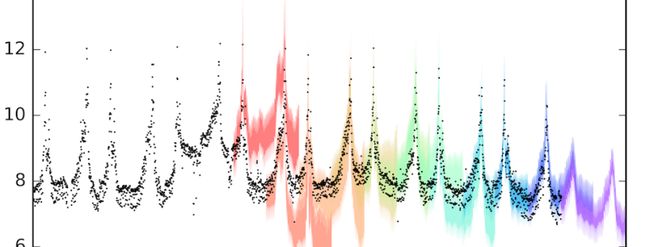

图1.谷歌搜索'柿子'的季节性趋势,来自http://rhythm-of-food.net/persimmon
此外,谷歌搜索柿子的情况在过去几年中也越来越频繁。

图2.来自http://rhythm-of-food.net/persimmon的谷歌搜索“柿子”的总体增长趋势
因此,柿子谷歌搜索趋势可以通过在增长趋势增加的季节性趋势中进行建模,即所谓的广义加性模型(GAM)。
GAM背后的原理与回归相似,不同之处在于代替各个预测因子的求和效应,GAM是平滑函数的总和。函数允许我们对更复杂的模式进行建模,并对它们进行平均,以获得更平滑的平滑曲线。
因为GAM是基于函数而不是变量的,所以它们不受限于回归中的线性假设,即要求预测变量和结果变量以直线移动。此外,与神经网络不同,我们可以分离和研究GAM中各个功能对结果预测的影响。
在本教程中,我们将:
查看如何使用GAM的示例。
了解GAM中的函数如何通过重新装配来识别。
了解如何验证时间序列模型。
例如:保存夏令时
住在四季地区的人会知道一个事实:冬季的阳光比夏季少。为了弥补这一缺陷,一些国家在夏季的时候将时钟向前移动了一个小时,为夜间户外活动安排了更多的阳光,并有望减少用于家中取暖和照明的能量。夏季推进时钟的做法称为夏令时(DST),并于20世纪初实施。
但是DST的实际好处仍然存在争议。值得注意的是,DST已被证明会扰乱影响工作绩效甚至导致事故的睡眠模式。因此,无论何时何时调整时钟,人们都会被提示质疑DST的基本原理,而维基百科是答案的来源之一。
为了研究DST页面浏览的趋势,我们首先使用Python脚本从维基百科数据库中提取数据。使用了从2008年到2015年的浏览量。接下来,我们使用由Facebook研究人员发布的称为Prophet的GAM包来进行Python中的时间序列分析。该软件包也可在R中找到。
的先知包是用户友好的,使我们能够指定不同类型的,包括所得到的GAM趋势的功能。有三种主要类型的功能:
总体增长。这可以建模为直线(线性)或稍微弯曲(逻辑)的趋势。在这个分析中,我们使用默认的线性增长模型。
季节性变化。这是使用傅里叶级数模型化的,它只是一种近似周期函数的方法。确切的功能是使用一种称为倒装的过程推导出来的,下一节将对此进行解释。我们可以指定我们是否预计每周或/和年度趋势存在。在这个分析中,我们包括两种情况 - 基于过去的研究,每周趋势似乎是合理的,周末时人们很可能会在室外的网络活动较少,而年度趋势可能与一年两次的时钟转换练习一致。
特别活动。除了模拟常规趋势之外,我们还应该考虑一次性事件。这包括任何现象,无论是政策公告还是自然灾害,都会为平滑的趋势增添涟漪。如果我们不考虑不规则事件,GAM可能会将它们误认为是持续事件,其影响将被错误地传播。
在我们的分析中,特殊事件包括美国钟表来回切换的确切日期。我们还可以在每个事件之前和之后指定窗口,我们预计会有重大影响。例如,在每次切换之前,DST上的联机搜索可能会开始增加。但是时间切换后的搜索行为可能会有所不同,具体取决于时钟是向前还是向后蜿蜒:人们可能更有可能在网上搜索他们睡眠不足的原因,但当他们得到额外的小睡时不会。除了时钟转换日期之外,我们还包括主要的DST相关事件。例如,2010年,由于希伯来语和太阳日历的差异,以色列在异常早期转向冬季时发生了抗议活动。我们分析中包含的事件可以在代码中找到。
除上述之外,Prophet包还要求我们指定先前的值,这些值决定了趋势线对数据值变化的敏感程度。较高的灵敏度会导致更多锯齿状的趋势,这可能会影响对未来值的普遍性。当我们验证我们的模型时,可以调整Priors,我们将在本教程后面看到。
现在,我们可以继续适应GAM。图3显示了总体增长,特殊事件和季节性变化的结果函数:
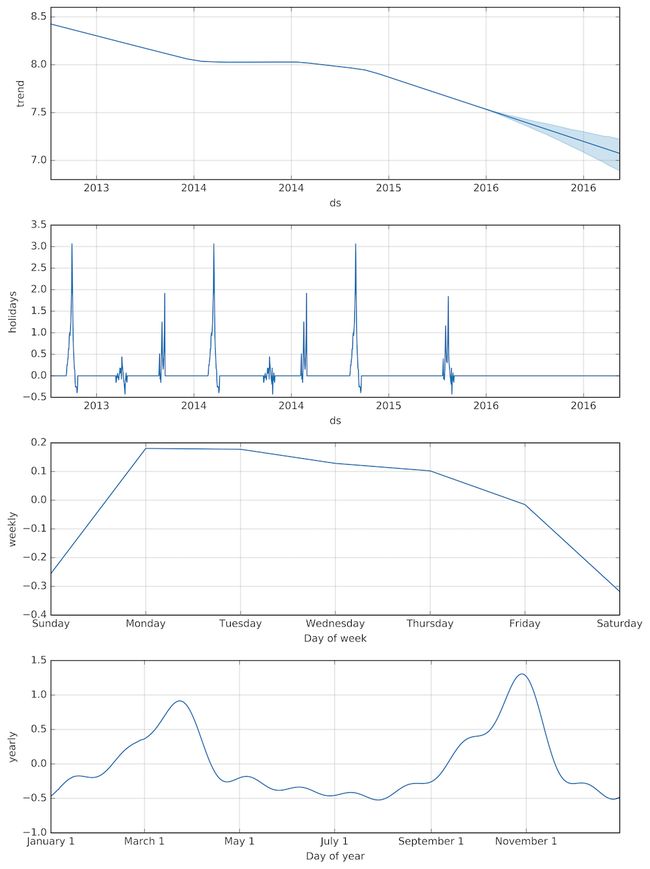
图3.包含GAM预测DST维基百科文章页面视图的函数。在整体趋势和特殊事件(即'节假日')的前两张图中,X轴标记为'ds',代表'日期戳记'。出现重复的年份标签,因为网格线与每年的相同日期不一致。
我们可以看到,DST维基百科文章的整体页面浏览量多年来一直在下降,这可能是由于竞争在线来源解释DST。我们还可以观察与特殊事件相吻合的页面浏览量峰值是如何计算的。每周趋势显示,人们最有可能在星期一阅读DST,最不可能在周末阅读。最后,年度趋势显示,页面浏览量在三月底和十月底发生高峰期,即时间转换发生的时间段。
我们不需要知道包含在GAM中的确切预测函数是很方便的。相反,我们只需要指定一些约束条件,最好的功能就会自动为我们导出。GAM如何做到这一点?
反拟合算法
为了找到适合数据的最佳趋势线,GAM使用称为倒装的程序。反拟合是一个迭代地调整GAM中的函数的过程,以便它们产生使预测误差最小化的趋势线。一个简单的例子可以用来说明这个过程。
假设我们有以下数据:

图4.示例数据集,由两个预测变量和一个结果变量组成。
我们的目标是找到适用于预测因子的适当函数,以便我们可以准确预测结果。
首先,我们致力于为预测变量1找到一个函数。一个好的初始猜测可能是将它乘以2:

图5.将“乘以2”函数应用于预测器1的模型的结果。
从图5可以看出,通过对预测变量1应用“乘以2”的函数,我们可以完美地预测50%的结果。但是,还有改进的空间。
接下来,我们致力于为预测变量2找到函数。通过分析拟合预测变量1函数的预测误差,我们可以看到,只要预测变量2具有正值,只需将结果加1即可达到100%的准确度,并且别的什么都不做(即signmoid函数)。
这是一个倒装过程的要点,总结了以下步骤:
步骤0:为一个预测器定义一个函数并计算出结果的误差。
步骤1:为最能减少错误的下一个预测器推导一个函数。
步骤2:对所有预测变量重复步骤1,并进一步重复循环以在必要时重新评估其功能,直到预测误差不能进一步最小化。
现在我们已经拟合了我们的模型,我们需要对其进行测试:它能够准确预测未来的值吗?
验证时间序列模型
交叉验证是评估模型预测未来价值有效性的首选技术。但是,时间序列模型是交叉验证不起作用的一个例外。
回想一下,交叉验证涉及将数据集分成随机子样本,用于重复训练和测试模型。关键的是,训练样本中使用的数据点必须独立于测试样本中的数据点。但这在时间序列中是不可能的,因为数据点是时间依赖的,所以训练集中的数据仍然会与测试集数据携带基于时间的关联。这需要不同的技术来验证时间序列模型。
我们可以根据时间段对它们进行切片,而不是随着时间对我们的数据点进行采样。如果我们想在未来一年(即预测时间范围)测试模型的预测准确性,我们可以将数据集划分为一年(或更长)的培训分部,并使用每个分部预测其下一年的数值。这种技术被称为模拟历史预测。作为指导,如果我们的预测范围是一年,那么我们应该每半年进行一次模拟预测。图6显示了11个DST维基百科页面浏览量的模拟预测结果。
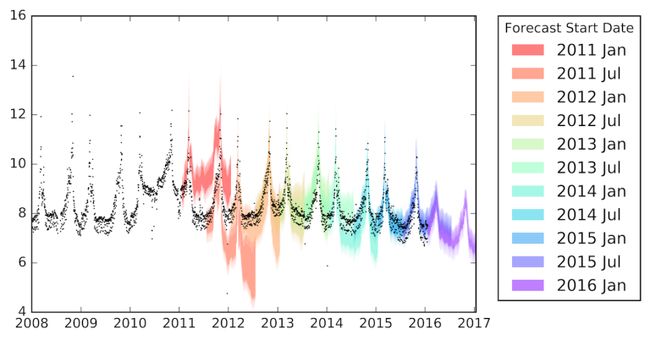
图6. DST维基百科页面浏览的模拟历史预测。
在图6中,预测范围为一年,每个培训部分包含三年的数据。例如,第一个预测频段(红色)使用2008年1月至2010年12月的数据来预测2011年1月 - 2011年12月的观点。我们可以看到,除了前两个模拟预测外,这些模拟预测被异常高的页面活动所误导在2010年,预测通常与实际值重叠。
为了更好地评估模型的准确性,我们可以从所有11个模拟预测中获取平均预测误差,并将其与预测时间范围进行比较,如图7所示。注意,随着我们试图进一步预测未来,误差会如何增加。
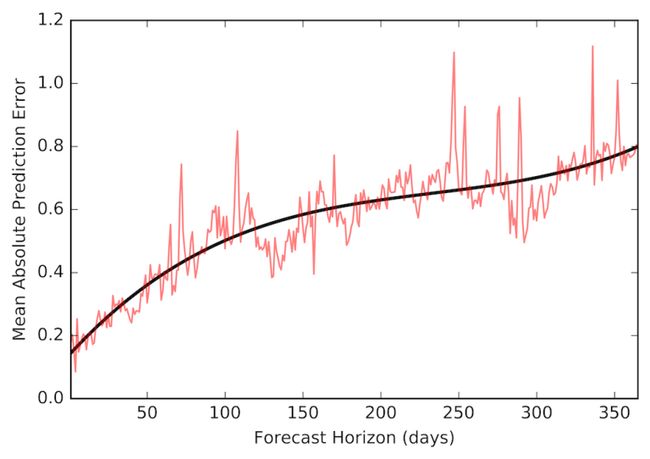
图7.预测范围内的预测误差。红线表示11个模拟预测的平均绝对误差,而黑线表示该误差的平滑趋势。
回想一下,我们需要调整的一个参数是先验值,它决定了我们的趋势对数据值变化的敏感程度。一种方法是尝试不同的参数值,并通过如图8所示的图进行比较。正如我们所看到的,过大的事先导致不太普遍的趋势,从而导致更大的错误。

图8.比较不同的先前值导致的预测误差。
除了调整先行者之外,我们还可以调整基础增长模型,季节性趋势和特殊事件的设置。对我们的数据进行可视化也有助于我们识别和删除异常值。例如,我们可以通过排除2010年的数据来改进预测,在此期间页面浏览次数非常高。
限制
正如你可能猜测的那样,在时间序列中有更多的训练数据不一定会导致更准确的模型。异常值或快速变化的趋势可能会加剧任何预测工作。更糟糕的是,对时间序列产生永久影响的突然震荡也可能使所有过去的数据无关紧要。
因此,时间序列分析最适合稳定和系统的趋势,我们可以通过可视化来评估趋势。
概要
时间序列分析是一种技术,可以推导出一段时间内的趋势,可用于预测未来的数值。广义相加模型(GAM)通过识别和累加多个函数来实现这一点,从而得到最适合数据的趋势线。
GAM中的函数可以使用反拟合算法来识别,该算法迭代地拟合和调整函数以减少预测误差。
时间序列分析最适合稳定和系统的趋势。