论文笔记-A Survey on Session-based Recommender Systems
基于session的推荐系统综述
- 1 INTRODUCTION
- 2 FORMALIZATION AND NOTATIONS
- 3 SIGNIFICANCE, COMPLEXITY AND KEY CHALLENGES
- 3.1 Values and Significance
- 3.2 Data Characteristics and Complexity
- 3.3 Key Challenges
- 3.3.1 An Overview of Challenges in SBRS
- 3.3.2 A Categorization of Challenges in SBRS
- 4 AN OVERVIEW OF SBRS
- 4.1 A Brief Evolutionary History of SBRS
- 4.2 Attention in the Research Community
- 5 CATEGORIZATION AND SUMMARIZATION
- 5.1 Categorization from the Research Issue Perspective
- 5.1.1 What to Recommend: A categorization of recommendation scenarios and settings.
- 5.1.2 How to Recommend: A Categorization of recommendation approaches.
- 5.2 A Categorization from the Technical Perspective
- 5.2.1 Model-Free Approaches.
- 5.2.2 Model-based Approaches.
- 5.2.3 Comparisons between Different Technical Approaches.
- 6 MODEL-FREE APPROACHES
- 6.1 Pattern/Rule-based Approaches
- 6.2 Sequential Pattern-based Approaches
- 7 MODEL-BASED APPROACHES
- 7.1 Markov Chain-based Approaches
- 7.1.1 Basic Markov Chain-based Approaches.
- 7.1.2 Latent Markov Embedding-based Approaches.
- 7.2 Factorization Machine-based Approaches
- 7.3 Neural Model-based Approaches
- 7.3.1 Shallow Neural Models.
- 7.3.2 Deep Neural Models.
- 8 PROSPECTS AND FUTURE DIRECTIONS
- 8.1 Session-based Recommendations With General User Preference
- 8.2 Session-based Recommendations Considering More Contextual Factors
- 8.3 Session-based Recommendations With Noisy and Irrelevant Items
- 8.4 Session-based Recommendations for Multi-Step Recommendations
- 8.5 Session-based Recommendations With Cross-session Information
- 8.6 Session-based Recommendations with Cross-domain Information
文章链接
1 INTRODUCTION
推荐系统已经进化为一个基础性的工具,可以帮助用户做出合理的决策和选择,尤其是在大数据环境下,消费者不得不从大量的商品和服务中做出选择。提出了大量的RS模型和技术,许多并已成功应用。在这些RS模型中,content-based RS和协同过滤RS是两个代表性的推荐模型。学界和工业界已经证实了其有效性。
然而,上述的传统的RS仍存在许多缺点。其中一个就是这些模型只关注。其中一个比较严重的缺点是:这些模型只关注用户长期的、静态的偏好,而忽略了短期的交易模式。这种情况下, 用户在某个时间点的兴趣很可能被其历史浏览行为覆盖。这是因为RS挺长将一个基本交易单元(例如一个session)分解成更小粒度上的记录,然后再混合这些记录。这种分裂模式破坏了交易行为,其中就包括用户的偏好信息。
为解决以上问题,有必要考虑交易的结构。换句话说,有必要学习用户的交易行为。SBRS应势而出。这里,一个session可以理解为是包含了很多item(例如商品)的交易。和content-based RS、基于协同过滤的RS不同,SBRS综合考虑了session信息,并将一个session作为推荐的基本单元。如图1的底部所示,SBRS可以最大限度地减少由于忽略或者打破session结构而造成的信息损失。
除了在电子商务领域,SBRS还可以应用在网页推荐、POI推荐、旅游、歌曲、视频推荐等。为包含这些领域,这里的session就不仅仅指交易单元,而是在一段时间内,购买后者浏览的item的集合。
表1是SBRA和其他RS的对比。

在这篇综述中,将对SBRS进行全面系统的概述。将session作为推荐的基本单元,这是近年来一种相对新颖的推荐模型。
2 FORMALIZATION AND NOTATIONS
本节,我们将定义session和SBRS一些相关的概念。
Definition 2.1 (Session). 一个session指的是在一段时间内手机或者购买的item的集合。例如,一次交易中购买的item或用户一小段时间内听的歌曲也可以视为一个session。此外,用户在固定时间段内连续点击的网页也可以看做是一个session。
Definition 2.2 (Session-based recommender systems (SBRS)). 给定已有的session信息,如一个session的部分信息或者历史session,SBRA就是想依据一个session或者多个session之间的复杂关系预测出session中未知的部分或未来可能的session。
因此,SBRS可以分为两种:下一个item的推荐,这种推荐模型推荐的是当前session的一部分;下一个session的推荐。
同城,推荐应用程序,例如基于购物车的业务系统,会包含两个基本对象:user和item。用户集合为 U = { u 1 , u 2 , . . . , u ∣ U ∣ } U = \{u_{1}, u_{2}, ..., u_{|U|}\} U={u1,u2,...,u∣U∣}, item集合为 I = { i 1 , i 2 , . . . , i ∣ I ∣ } I = \{i_{1}, i_{2},..., i_{|I|}\} I={i1,i2,...,i∣I∣}。user和item的交互行为包括:click,buy等,是RS中重要的组成部分。例如,用户点击的所有的item形成click session;用户购买的item又可以形成交易session。通常,在一段时间内,一个用户发生交互的item构成一个session s = { i 1 , i 2 , . . . , i ∣ s ∣ } s = \{i_{1}, i_{2}, ..., i_{|s|}\} s={i1,i2,...,i∣s∣}。Session的集合就是 S = { s 1 , s 2 , . . . , s ∣ S ∣ } S = \{s_{1}, s_{2}, ..., s_{|S|}\} S={s1,s2,...,s∣S∣}。SBRS将未知的session作为目标 t \bm{t} t,利用已有的session信息来预测目标 t \bm{t} t。Session的上下文信息也可以分为两种,这取决于上下文是取自一个session还是多个。
Definition 2.3 (Intra-session context). 当前session记为 s n s_{n} sn,intra-session context C I a C^{Ia} CIa就是在session s n s_{n} sn中已知的item集合。即 C I a = { i ∣ i ∈ s n , i ̸ = i t } C^{Ia} = \{i | i \in s_{n}, i \not= i_{}t\} CIa={i∣i∈sn,i̸=it}, i t i_{t} it就是session s n s_{n} sn中的未知item。
Definition 2.4 (Inter-session context). 当前session记为 s n s_{n} sn, C I e C^{Ie} CIe是在session s n s_{n} sn之前的session集合,即 C I e = { s n − 1 , s n − 2 , . . . , s ∣ C I e ∣ } C^{Ie} = \{s_{n-1}, s_{n-2}, ..., s_{|C^{Ie}|}\} CIe={sn−1,sn−2,...,s∣CIe∣}.
Definition 2.5 (Session-based recommendation task). 给定session,上下文 C C C,基于session的推荐任务就是学习一个映射 f f f,将 C C C映射到推荐目标 t \bm{t} t。session上下文是该任务中主要信息;有时,也会添加item特征,user特征等信息。
Definition 2.6 (Next-item(s) recommendations). 给定一个 C I a C^{Ia} CIa,这种推荐模式就是在 s n s_{n} sn中预测下一个item。
Definition 2.7 (Next-session (next-basket) recommendations). 给定一个 C I e C^{Ie} CIe,这种推荐模式就是预测session s n s_{n} sn中的items。
3 SIGNIFICANCE, COMPLEXITY AND KEY CHALLENGES
3.1 Values and Significance
SBRS在学术界,工业界均很重要。在研究领域,SBRS可以保持session的自然特征,避免局部信息损失。例如,如果不考虑session结构,item的共现信息可能会丢失。这些局部的交易信息,在一些特定业务场景中非常关键。 如果没有session信息, (a)容易产生重复推荐,即推荐相似或已现有相同的item;(b)用户的购物模式将消失,不能进行个性化推荐。(c)用户偏好转移(shift)消失,不能捕捉用户的当前的喜好;从一个session到另一个session时,用户的喜好通常是动态变化的;(d)不能捕捉短期、局部的用户喜好。在实际生产中,上述的RS只能捕捉用户长期或全局的喜好。
通过保留session结构并将session作为基本数据单元,SBRS将保留所有的局部信息。因此,SBRS更能提供可靠的推荐。SBRS更关注局部、动态的session。由于当前的或最近的session中的item已被选中,因此SBRS很容易避免推荐重复或者相似的item。此外,由于每个用户的item都是一个session,就更容易知道其交易模式。此外,SBRS中考虑的是当前或者最近的session中的item,而不是全部session中的item,这样就更容易捕获用户局部或短期内的喜好。更重要的是,SBRS容易捕获用户转移的偏好。
在工业应用领域,SBRS更重要。Session数据比其他数据(item特征,item排序)更重要。
3.2 Data Characteristics and Complexity
SBRS同样具有挑战性。在实际应用中,在session的数据集中是具有一个层级结构的,如图2所示的5级层级结构。从特征级到域级。在这5个层级中,中间的3层是session模型的核心。即item是关键部分,原因有二:一方面,item是session数据中的原子粒度的部件;另一方面,item扮演了大多数session模型中的重要角色。

每个item通过由多个异构的特征描述,如item类别、价格、生产地等。每种特征通常包含多个值。在大多数情况下,item之间的相关性是建立在齐共现的基础之上的。一般情况下,一个域中收集的数据会包含多个session。
3.3 Key Challenges
如图2所示,SBRS在每一个局部都有挑战性。
3.3.1 An Overview of Challenges in SBRS
(a) Inner-session challenges. Inner-session challenges发生在session内部,在session内部,结构复杂。一个层级结构包含多个层,Inner-session challenges就是在item level、feature level、feature value level以及这些level交互时的挑战。
(b) Inter-session challenges. Inter-session challenges是指session之间交互时的挑战,即图2中的session level。一点典型的挑战包括:session异构、session之间的依赖、动态session等。
( c c c) Outer-session challenges. Outer-session challenges是指域level和model level的挑战。
与session相关的上下文指的是session发生时所处的环境信息,例如时间、地点、天气、季节、用户等。在SBRS中应该考虑上下文信息。
3.3.2 A Categorization of Challenges in SBRS
SBRS的所有挑战可以分为四种。
(a) The heterogeneity within each level 每个level是异构的。每个level的元素不同,则特征不同,从而不能平等对待。
- Value异构:特征值分布不同。
- Feature异构:一个item通常包含不同类型的feature,包括类别、数值。
- Item异构:一个session钟的item分布也不相同。
- Session异构:不同的上下文环境导致不用的session。有些可能是无关的,有些可能是噪声。
- Context异构:上下文的信息不同。
(b) The couplings within each level 每个level的耦合信息,即每个level的交互挑战。
- Value-level耦合:同一个特征不同值的交互(intra-feature),和不同特征的值的交互(inter-feature)。
- Feature-level耦合:一个特征可能会影响其他特征。
- Item-level耦合:在一个session钟,item之间的交互。
- Session-level耦合:不同session的交互。在实际的交互场景中,最近的session可能会对当前的session产生影响。
- Domain-level耦合:不同域之间的交互。
- Contextual耦合:不同上下文信息的交互。
( c c c) Other complexities within each level 每个level是相当复杂的。
(d) The interactions between different levels 不同level之间的交互,不同的level可能存在不同的交互关系。
- Feature-item交互。
- Session-item交互。
4 AN OVERVIEW OF SBRS
4.1 A Brief Evolutionary History of SBRS
SBRS研究从1990s以来,就有不同的研究内容:pattern-based RS,rule-based RS,sequence-based RS,transaction-based RS,session-aware RS等。我们将SBRS的研究分为你两个不同的阶段:1990-2010的model-free阶段;2010-至今,基于model的SBRS。第一个阶段,室友数据挖掘技术驱动的,包括模式挖掘、关联规则和序列挖掘。根据相应的文献研究,我们发现,2000s前后是这一阶段的高峰时期。第二阶段是由统计和机器学习驱动的,尤其是一些与时间序列相关的模型,包括马氏链、RNN等。由于深度学习的发展,自2017年以来model-based RS达到了峰值,许多研究相继出炉,可见图4。

4.2 Attention in the Research Community
数据挖掘相关的会议,如KDD, CIKM,WSDM,IJCAI,AAAI,ECML,Recsys,WWW,SIGIR。
5 CATEGORIZATION AND SUMMARIZATION
将SBRS研究分为以下几个领域。
5.1 Categorization from the Research Issue Perspective
SBRS研究关注的是推荐什么和如何推荐。推荐什么讨论的是研究任务、场景,这些都是优先设置的;如何推荐,这与3.3节中所列举的挑战是相关的。
5.1.1 What to Recommend: A categorization of recommendation scenarios and settings.
通常情况下,SBRS中获取的session数据可以分为两类。第一个是像购物车一样的(如天猫数据集),这样的session又明确的内在session结构。例如,每个购物车界限清楚。在这种情况下,购物车是自然色session。
另外一种是类似于历史行为的数据,原始数据是事件记录的集合,例如电影数据、POI数据等。Event历史数据通常没有一个自然的session结构;换言之,没有一个明确的边界可以区分events。例如,一个用户经常只看某一部电影。因此,session特征是模糊的,数据不是那么strong。这类数据通常用某些技术,例如时间滑动窗口,将数据分成多个session。这种推荐任务是next event/action推荐。
(a) Next-Item(s) Recommendations. Next-item推荐指的是在一个session钟,推荐下一个或下几个item(session通常是购物车)。Next-item推荐是主流的和常见的推荐任务。如表3,是next-item推荐的相关研究。

(b) Next-Basket Recommendations. 在下一个session中推荐一个item。Next-basket推荐研究相对较少。见表3所示。
( c c c) Next-Event/Action Recommendations. 推荐下一个event/action,如看电影或听歌等。这类研究数据没有session结果,相关研究见表3所示。
5.1.2 How to Recommend: A Categorization of recommendation approaches.
SBRS一个主要的驱动力就是耦合或依赖关系。这是由于特殊的设置导致的:给定session上下文,推荐系统会根据下一个上下文信息来寻找相应的items或events。如何推荐,本质上就是图2每层或不同层之间的复杂的依赖关系。根据session数据的层级结构,相应的推荐方法可以分为5个分支。
(a) Item-level Dependency Modeling. Item-level依赖建模是指对一个session内的item之间或event之间的依恋关系建模。近年来,许多研究是建立在这个分支上的。有几个典型的问题会对模型质量或性能产生影响。
- Ordered vs. unordered items. 现实场景中的session数据通常分为两种类型:有序和无序。根据session中是否存在item的排序关系来确定。例如,在医疗或基因表达数据中,顺序将相当严格。而购物车数据中,顺序是没有意义的,因为顾客挑选item时是随机的。
为此,一些方法假定session中的item有严格顺序,依据item之间的序列关系来确定item的顺序。一种简单的方法是基于序列模式挖掘的RS,显式地挖掘序列模式从而指导推荐。为获取session内item之间的隐藏序列关系,并保留原始的信息,可以采用马氏链、RNN等模型。马氏链和RNN模型在处理序列关系数据集时有巨大优势。
其他方法尝试放松或者抛弃这个顺序假设。基于模式/规则的方法相应而出,它们根据item的共现信息来显式地挖掘模式。为捕获item之间的隐藏关系,采用的方法包括:因子分解机,浅层NN, DNN, CNN。
- First-order dependency vs. higher-order dependency. 一些方法是建立在一阶的依赖关系之上的,只获取item之间的一阶依赖关系。在预测next item时,仅依赖前一个item。方法包括:一阶马氏链,因子分解机。然而,许多session数据不仅包括一阶依赖关系,还包括高阶的依赖关系在这种情况下,基于网络的方法更容易获取高阶依赖关系,这时的网络模型包括浅层和深层网络模型。
(b) Session-level Dependency Modelling. 指的是对session之间的依赖关系进行建模。由于session是建立在item之上的,所以对session-level的依赖关系进行建模往往就伴随着item-level的依赖关系建模。Session-level依赖关系建模分为next-item推荐和next-basket推荐。对于next-item推荐来说,session-level依赖关系建模,采用的是session之间的依赖关系,因此要考虑前面的sessions。因此,可以增强先验信息。在next-basket推荐中,session-level依赖关系建模对于获取session之间的依赖关系很有必要。
根据对session之间的依赖关系进行建模,session-level依赖关系建模也分为两种:
- Item dependency modelling. item依赖关系建模是对item之间的转换关系进行建模。Item可能来自不同的session,这种方法首先研究session之间item的转换关系,然后根据当前basket中的item预测下一个basket中出现的item。如因子分解机。
- Collective dependency modelling. 和上述方法不同,集合依赖关系建模通过将每个session作为一个整体来建立session之间的依赖关系。一个session的表示可以通过一个层级网络学习到,该模型首先学习item表示,然后集合session中每个item的表示。在训练过程中,下一个session来知道表示学习。
( c c c) Feature-level Dependency Modelling. 指的是特征之间的依赖关系建模和feature-item关系建模。特征之间的依赖关系是一个item的特征可能会影响另一个特征。例如,不同国家的Apple价格也不一样。Feature-item的依赖关系建模指的是在一个session中,item出现的情况会受其特征的影响。如item属于同一类,但是作用是互补的,因此item会出现在同一个session中。Item feature的参与使得我们能更好的理解item的特征。因此,feature-level的依赖关系建模对冷启动的item是有好处的。
针对冷启动的item推荐目前已经取得了很多进展。但是,feature-level依赖关系建模扔处于早期研究阶段。
(d) Feature Value-level Dependency Modelling & Domain-Level Dependency Modelling. 获取特征内部的依赖关系和特征值与特征item的交互关系。Domain-level依赖关系建模可以获取不同domain之间的依赖关系。据我们所致,在SBRS研究中,还没有人研究特征值-level和domain-level的依赖关系建模。但是这将是一个有前景的研究方向。
5.2 A Categorization from the Technical Perspective
从技术领域进行分类。
5.2.1 Model-Free Approaches.
依赖数据挖掘技术,没有复杂的数学模型。两个传统的方法是:pattern/rule-based RS用来处理无序的session数据;序列模式RS处理有序的session数据。
(a) Pattern/Rule-based Approaches. 首先利用挖掘频繁出现的模式或者连接规则,并用pattern-rule指导推荐。前提假设是消费者会遵从常见的购物模式。例如,用户经常购买面包和牛奶,这就是给购买牛奶的人推荐面包的理由。应用在无序的session数据上。
(b) Sequential Pattern-based Approaches. 为处理有严格顺序的item或基于时间因子的序列数据。首先挖掘一个序列模式,然后根据前面的item推荐出后面的item 。
5.2.2 Model-based Approaches.
基于模型的RS,往往有严格的假定。现有的基于模型的RS,可以分为三类。
(a) Markov Chain-based Approaches. 建立item之间的一阶依赖关系,利用的是转移概率。序列模式建模,模型容易过滤掉不常出现的item,这样会导致信息丢失。而基于马氏链的模型会综合考虑前面所有的item,降低信息损失。
(b) Factorization-based Approaches. 首先分解item的共现矩阵或item-to-item的转移概率矩阵为每个item的表示向量,然后预测接下来的item。这个方法区别于一般的因子分解机方法。
© Neural Model-based Approaches. 利用神经网络学习item之间或session之间的复杂的关系和交互,然后根据交互关系获得相应推荐。根据模型结构,可以分为浅层/深层模型,也成为embeddings model和representation model。
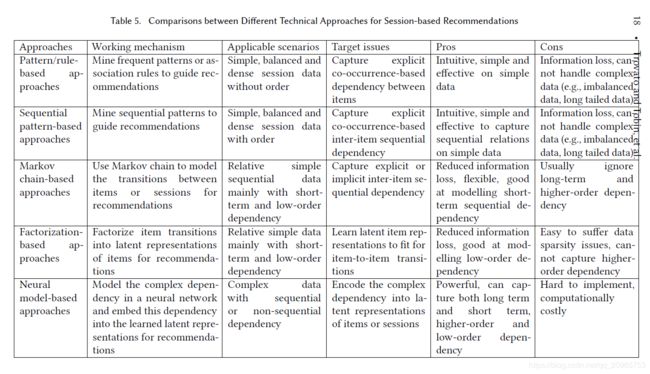
5.2.3 Comparisons between Different Technical Approaches.
不同技术的比较。model-free方法简单,直接,便于实现。由于pattern/rule-based和序列模式的方法只是基于频率进行建模的,这样就会过滤掉不常出现但是可能比较重要的item或模式。因此,model-free方法使用与经常出现的item的数据集。model-based方法对复杂的数据集处理效果更好。一方面,它们不会显式地过滤掉item或模式,将信息保留到最大程度;另一方面,由于方法复杂,可以处理复杂、隐式的数据关系,推荐结果更加可靠。表5是不同方法的比较。
6 MODEL-FREE APPROACHES
主要依赖于数据挖掘尤其是模式挖掘技术。基本思想是通过从session数据中挖掘共有的、显式地模式,然后用于推荐,
6.1 Pattern/Rule-based Approaches
主要包括了三个阶段:frequent模式挖掘,session匹配,item推荐。具体来说,给定item集合 I I I和对应的session集合 S S S,frequent模式集合为 P T = { p 1 , p 2 , . . . , p ∣ P T ∣ } PT = \{p_{1}, p_{2}, ..., p_{|PT|}\} PT={p1,p2,...,p∣PT∣}是用模式挖掘算法挖掘到的。如Apriori和FP-Tree算法。对于给定的、部分session s ^ \hat{s} s^(例如,一次交易中选择的item),如果item i ^ \hat{i} i^存在,那么 s ^ ∪ i ^ ( i ^ ∈ I ∖ s ^ ) \hat{s} \cup \hat{i} (\hat{i} \in I \setminus \hat{s}) s^∪i^(i^∈I∖s^)就是一个frequent pattern,称 { s ^ ∪ i ^ } ∈ P T \{\hat{s} \cup \hat{i}\} \in PT {s^∪i^}∈PT。那么 i ^ \hat{i} i^就是候选item。进一步,如果条件概率 P ( i ^ ∣ s ^ ) > β P(\hat{i} | \hat{s}) > \beta P(i^∣s^)>β,那么就将 i ^ \hat{i} i^加到候选列表中。
除了上面提到的pattern/rule-based RS框架外,还有许多变体。[83]将关联规则挖掘结合到协同过滤中,它们在模式挖掘中取代了最小支持约束来提高效率,以此来避免挖掘和用户无关的规则。考虑到不同item的重要性,[148]和[40]采用连续页面查看来衡量每个页面的重要性,然后利用这个权重,将这个权重加到关联规则挖掘中,简历加权的关联规则RS。通过挖掘用户行为模式,例如,文本导航页,关联规则挖掘则用来获取特定用户的喜好,以此获取更加个性化的推荐。其他工作将模式挖掘结合到协同过滤中来解决一些特殊问题,如稀疏性,健壮性和个性化。Pattern-based RS除了传统的购物车RS外, 还可以用于web推荐,音乐推荐等。
6.2 Sequential Pattern-based Approaches
虽然和pattern-based RS类似,sequential pattern based RS主要有两点不同: 1)它主要利用交叉session推荐来获取session内的依赖关系;2)考虑session的顺序,因此要结合序列数据。sequential pattern based RS也包含了三个阶段:sequential模式挖掘,序列匹配,获取推荐。
给定一个序列集合 Q = { q 1 , q 2 , . . . , q ∣ Q ∣ } Q = \{q_{1}, q_{2}, ..., q_{|Q|}\} Q={q1,q2,...,q∣Q∣},其中序列 q = { s 1 , s 2 , . . . , s ∣ q ∣ } q = \{s_{1}, s_{2}, ..., s_{|q|}\} q={s1,s2,...,s∣q∣}是session的集合。
除了上述描述的基本框架外,还有许多扩展。一个典型的例子就是利用用户相关sequential pattern挖掘来做个性化推荐。另一个扩展是将sequential pattern和协同过滤融合。由于进行了组合,动态的单个模式和通用的偏好模型都将考虑到。
7 MODEL-BASED APPROACHES
7.1 Markov Chain-based Approaches
利用马氏链在给定一个session内的一系列item以后,预测下一个item。为降低模型复杂度,许多RS都建立在一阶马氏链上。
7.1.1 Basic Markov Chain-based Approaches.
一般来说,基本的基于马氏链的RS很简单:首先在训练集的item序列上计算转移概率,然后将用户的购物序列和利用转移概率计算出的序列进行匹配。概率比较高的item将放到推荐列表中。
给定session集合 S S S,每个session s s s是有序的item序列。马氏链将所有的session编码到一个图 G G G中,每个item是一个节点,item的共现信息作为边。每个item的频率和共现信息作为边的权重。每个session是G中的一条路径。
马氏链是一个元组 { S T , P t , P 0 } \{ST, \bm{P_{t}}, P_{0}\} {ST,Pt,P0}, S T ST ST是状态空间,包含了 G G G中所有可见的节点; P t \bm{P_{t}} Pt是 m ∗ m m * m m∗m的转移概率矩阵; P 0 P_{0} P0是每个状态的初始概率。一阶转移概率定义为:
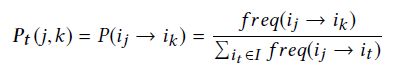
然后就可以刘勇上述一阶马氏链模型估计shopping path的概率:
![]()
给定item序列,可以选择概率比较更高的shopping path,并取给定的item作为先验信息。
除上面定义的基本马氏链RS外,还有许多变体。如,结合一阶和二阶马氏链模型;提出基于隐马氏链的概率模型。通过结合其他因素,一高推荐的准确性。
7.1.2 Latent Markov Embedding-based Approaches.
LME-based RS首先将马氏链嵌入到欧式空间中,然后计算item的转移概率,依据是欧氏距离。可以解决稀疏性问题。每个item i i i表示成向量 v i \bm{v_{i}} vi,是一个 d d d维向量,转移概率 P ( i j − 1 → i j ) P(i_{j-1} \rightarrow i_{j}) P(ij−1→ij)。Shopping path q ′ = { i 1 → i 2 → . . . → i l } q ' = \{i_{1} \rightarrow i_{2} \rightarrow ... \rightarrow i_{l}\} q′={i1→i2→...→il}的概率为:
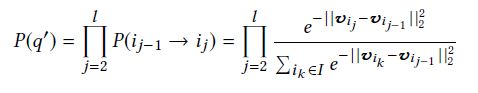
为获得个性化推荐,[46]提出PME模型,将users和items映射到欧式空间。[39]提出个性化排序肚量embedding学习。
7.2 Factorization Machine-based Approaches
近来,因子分解机常用来做推荐模型。一旦从观测数据中获得了个性化转移概率,对于每个用户 u u u就建立了一个转移矩阵 A u \bm{A^{u}} Au。因此,对于所有用户,转移Tensor A \rm{A} A。
因子分解模型仅建立在item的共现转移矩阵上,只能获取item的序列模型,但是忽略了用户的偏好。[82]结合矩阵分解和协同过滤来获取个人偏好和item转移模式。
7.3 Neural Model-based Approaches
基于神经网络的方法。
7.3.1 Shallow Neural Models.
浅层网络,或称为嵌入模型,包含浅层网络结构。将session中的item映射到一个隐空间,然后获取item之间的关系。隐向量表示包含了丰富的信息。
如[57]。wide-in,wide-out模型。首先将用户ID和item ID映射到隐向量表示,然后组合作为给定的上下文表示,输出预测的item。
网络利用Logistic函数映射用户 u u u和item i i i:
v u = σ ( W : , u 1 ) \bm{v_{u}} = \sigma(\bm{W_{:, u}^{1}}) vu=σ(W:,u1)
v i = σ ( W : , i 2 ) \bm{v_{i}} = \sigma(\bm{W_{:, i}^{2}}) vi=σ(W:,i2)
其中, W 1 , W 2 \bm{W^{1}}, \bm{W}^{2} W1,W2是权重矩阵.利用这种方法,每个用户和item都被映射成向量。
此外,将item特征融入到网络中可以解决冷启动推荐问题。
7.3.2 Deep Neural Models.
SBRS深度网络模型始于2016年,如GRU4Rec。在GRU4Rec基础上,提出了一系列模型。基于RNN的模型占据了主导地位,因为大多数session数据是序列化的。基于DNN的模型用来优化不同的表示,基于CNN的模型经常用来提取局部特征。
(a) RNN-based Models. Session集合 S S S, s s s是一次交易中的item集合,GRU4Rec将每个Session建模成一个序列,预测下一个元素的概率分布。GRU是RNN单元,延长状态更新如下:
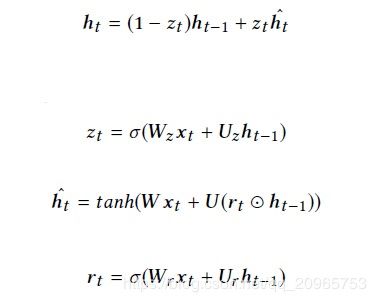
每个GRU单元表示一个隐藏状态,GRU层包含了一系列GRU单元。输入 x t x_{t} xt是session s s s中的item i t i_{t} it的嵌入表示。因此,给定session s s s中的历史item,可以预测下一个item的概率分布。
为改进GRU4Rec,[124]采用序列处理和dropout来做数据增强。另外,预训练模型也经常使用。[11]提出了分层的RNN来提取交叉session的信息。
除了上述的GRU外,还有很多RNN的变体。DREAM学习用户的动态表示,其他的扩展包括:1)变分推理,处理不确定稀疏业务;2)其他信息如item特征,上下文因素。3)注意力机制。
(b) DNN-based Models. 除了RNN,DNN也可以用于SBRS中,尤其是当session中的item没有顺序时。[144]中,使用DNN学习session表示。
(b) CNN-based Models. CNN也可以用于SBRS中,原因有:1)CNN放松了session中item的顺序假定,模型更鲁邦;2)局部学习能力强,高效提取union-level依赖关系。
8 PROSPECTS AND FUTURE DIRECTIONS
分析不足和SBRS未来研究方向。SBRS是一个相对较新的领域。
8.1 Session-based Recommendations With General User Preference
SBRS通常忽略了一般用户的偏好,而其他传统方法却可以获取到。这可能导致不可靠的推荐。如何学习一般用户的喜好以及如何应用带SBRS中是一个挑战,这里谈论两点。
将用户偏好融入到SBRS中。用户对于他们购买的item的偏好可以利用user-item偏好矩阵获取。一个直观的方法是先利用传统方法预测用户在候选item上的偏好,然后利用偏好数据调整候选列表。例如,两个候选item在特定上下文中有相似的概率,一个对于特定用户来说有较高的偏好,那么该item会被放在前面。另外一种方法是将两个因素综合考虑。[155]利用GAN实现。
如何在没有偏好数据时将用户体验融入SBRS。现实情况中,偏好数据并不总司可以获取到的,因为用户不会对他们购买的所有item进行评分,这种情况下,基于购物车的交易数据通常认为是用户偏好的隐式反馈。
8.2 Session-based Recommendations Considering More Contextual Factors
推荐上下文是指在推荐时实际的环境。如季节,时间,地点,流行趋势等。这些会对推荐性能产生巨大影响,上下文信息在SBRS中很少采用。需要将更多因素融入到SBRS中,例如CRNN。
8.3 Session-based Recommendations With Noisy and Irrelevant Items
目前,sequential SBRS,如基于RNN,马氏链的模型都假设item有强依赖关系。然而,在实际业务数据中可能不是这样。随机选择的item和推荐的item可能没有关系,推荐结果可能会被噪声误导。
8.4 Session-based Recommendations for Multi-Step Recommendations
购物事件包含了多个步骤。例如,用户买了面包,他随后可能买芝士。
8.5 Session-based Recommendations With Cross-session Information
用户对next-item选择不仅仅取决于同一个session中的item,还可能取决于其他session中的item。
8.6 Session-based Recommendations with Cross-domain Information
用户购买的item涉及多个产品类别(域),不同的域可能不是独立的。