Python正则表达式(含正则表达式速查表)
1、正则表达式的优点
正则表达式能够匹配只要你能描述出来的字符串,对于普通的文本中常用的一些关键词,如果想匹配某种模式很适合用而不是通过普通的contains这种是否含有等匹配。
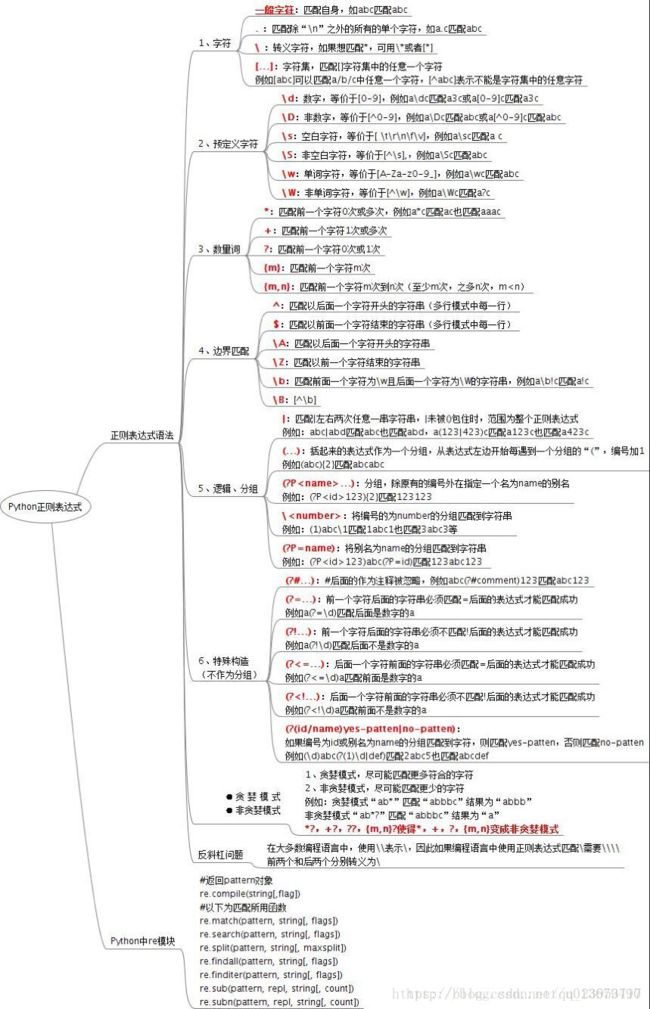
2、python正则表达式速查表
3、python正则表达式使用方法:
首先,导入python的re模块
import re
# 将正则表达式编译成Pattern对象 pattern = re.compile(r'因.+?入院')
# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
notes = '
初步诊断: 1.慢性阻塞性肺病伴急性加重 2.肺部感染 3.冠心病 缺血性心肌病 心功能II级 4.高血压病?' match = pattern . match ( notes )
if match: # 使用Match获得分组信息 print match.group()
re.compile(strPattern[, flag]):
flag可选值有:
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- re.M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
- re.S(DOTALL): 点任意匹配模式,改变'.'的行为
- re.L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
- re.U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
- re.X(VERBOSE): 详细模式。
Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
match属性:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
- group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。 - groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。 - groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。 - start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。 - end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。 - span([group]):
返回(start(group), end(group))。 - expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g、\g引用分组,但不能使用编号0。\id与\g是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。

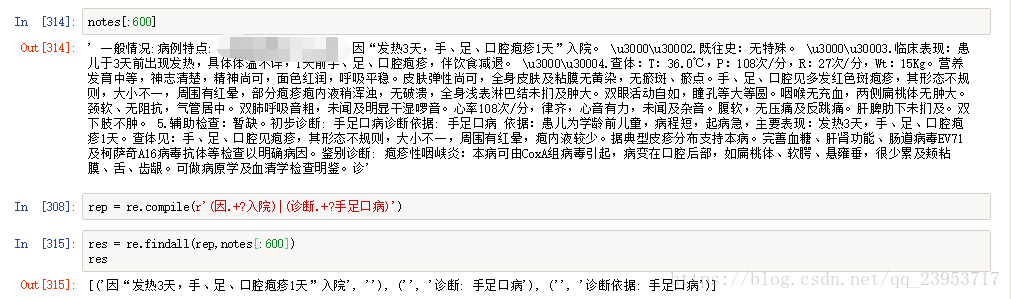
其中,findall是非常好用的,可以直接把匹配的内容以列表的形式返回,示例如下:



4、正则表达式练习地址:
这是一个神器地址,相当好用:http://regexr.com/