SQLServer之创建索引视图
索引视图创建注意事项
对视图创建的第一个索引必须是唯一聚集索引。 创建唯一聚集索引后,可以创建更多非聚集索引。 为视图创建唯一聚集索引可以提高查询性能,因为视图在数据库中的存储方式与具有聚集索引的表的存储方式相同。 查询优化器可使用索引视图加快执行查询的速度。 要使优化器考虑将该视图作为替换,并不需要在查询中引用该视图。
索引视图中列的 large_value_types_out_of_row 选项的设置继承的是基表中相应列的设置。 此值是使用 sp_tableoption设置的。从表达式组成的列的默认设置为 0。 这意味着大值类型存储在行内。
可以对已分区表创建索引视图,并可以由其自行分区。
若要防止 数据库引擎 使用索引视图,请在查询中包含 OPTION (EXPAND VIEWS) 提示。 此外,任何所列选项设置不正确均会阻止优化器使用视图上的索引。 有关 OPTION (EXPAND VIEWS) 提示的详细信息,请参阅 SELECT (Transact-SQL)。
若删除视图,该视图的所有索引也将被删除。 若删除聚集索引,视图的所有非聚集索引和自动创建的统计信息也将被删除。 视图中用户创建的统计信息受到维护。 非聚集索引可以分别删除。 删除视图的聚集索引将删除存储的结果集,并且优化器将重新像处理标准视图那样处理视图。
可以禁用表和视图的索引。 禁用表的聚集索引时,与该表关联的视图的索引也将被禁用。
索引视图创建要求
创建索引视图需要执行下列步骤并且这些步骤对于成功实现索引视图而言非常重要:
-
验证是否视图中将引用的所有现有表的 SET 选项都正确。
-
在创建任意表和视图之前,验证会话的 SET 选项设置是否正确。
-
验证视图定义是否为确定性的。
-
使用 WITH SCHEMABINDING 选项创建视图。
-
为视图创建唯一的聚集索引。
索引视图所需的 SET 选项
如果执行查询时启用不同的 SET 选项,则在 数据库引擎 中对同一表达式求值会产生不同结果。 例如,将 SET 选项 CONCAT_NULL_YIELDS_NULL 设置为 ON 后,表达式 ' abc ' + NULL 会返回值 NULL。 但将 CONCAT_NULL_YIEDS_NULL 设置为 OFF 后,同一表达式会生成 ' abc '。
为了确保能够正确维护视图并返回一致结果,索引视图需要多个 SET 选项具有固定值。 下表中的 SET 选项必须设置中显示的值为RequiredValue列出现以下情况时:
-
创建视图和视图上的后续索引。
-
在创建表时,在视图中引用的基表。
-
对构成该索引视图的任何表执行了任何插入、更新或删除操作。 此要求包括大容量复制、复制和分布式查询等操作。
-
查询优化器使用该索引视图生成查询计划。
SET 选项 必需的值 默认服务器值 ,则“默认”
OLE DB 和 ODBC 值,则“默认”
DB-Library 值ANSI_NULLS ON ON ON OFF ANSI_PADDING ON ON ON OFF ANSI_WARNINGS* ON ON ON OFF ARITHABORT ON ON OFF OFF CONCAT_NULL_YIELDS_NULL ON ON ON OFF NUMERIC_ROUNDABORT OFF OFF OFF OFF QUOTED_IDENTIFIER ON ON ON OFF *将 ANSI_WARNINGS 设置为 ON 隐式将 ARITHABORT 设置为 ON。
如果使用的是 OLE DB 或 ODBC 服务器连接,则唯一必须要修改的值是 ARITHABORT 设置。 必须使用 sp_configure 在服务器级别或使用 SET 命令从应用程序中正确设置所有 DB-Library 值。极力建议在服务器的任一数据库中创建计算列的第一个索引视图或索引后,尽早在服务器范围内将 ARITHABORT 用户选项设置为 ON。
确定性视图
索引视图的定义必须是确定性的。 如果选择列表中的所有表达式、WHERE 和 GROUP BY 子句都具有确定性,则视图也具有确定性。 在使用特定的输入值集对确定性表达式求值时,它们始终返回相同的结果。 只有确定性函数可以加入确定性表达式。 例如,DATEADD 函数是确定性函数,因为对于其三个参数的任何给定参数值集它总是返回相同的结果。 GETDATE 不是确定性函数,因为总是使用相同的参数调用它,而它在每次执行时返回结果都不同。
要确定视图列是否为确定性列,请使用 COLUMNPROPERTY 函数的 IsDeterministic 属性。 使用 COLUMNPROPERTY 函数的 IsPrecise 属性确定具有架构绑定的视图中的确定性列是否为精确列。 如果为 TRUE,则 COLUMNPROPERTY 返回 1;如果为 FALSE,则返回 0;如果输入无效,则返回 NULL。 这意味着该列不是确定性列,也不是精确列。
即使是确定性表达式,如果其中包含浮点表达式,则准确结果也会取决于处理器体系结构或微代码的版本。 为了确保数据完整性,此类表达式只能作为索引视图的非键列加入。 不包含浮点表达式的确定性表达式称为精确表达式。 只有精确的确定性表达式才能加入键列,并包含在索引视图的 WHERE 或 GROUP BY 子句中。
其他要求
除对 SET 选项和确定性函数的要求外,还必须满足下列要求:
-
-
执行 CREATE INDEX 的用户必须是视图所有者。
-
创建索引时,IGNORE_DUP_KEY 选项必须设置为 OFF(默认设置)。
-
在视图定义中,表必须由两部分组成的名称(即 schema.tablename**)引用。
-
必须已使用 WITH SCHEMABINDING 选项创建了在视图中引用的用户定义函数。
-
视图中引用的任何用户定义函数都必须由两部分组成的名称(即 schema.function**)引用。
-
用户定义函数的数据访问属性必须为 NO SQL,外部访问属性必须是 NO。
-
公共语言运行时 (CLR) 功能可以出现在视图的选择列表中,但不能作为聚集索引键定义的一部分。 CLR 函数不能出现在视图的 WHERE 子句中或视图中的 JOIN 运算的 ON 子句中。
-
在视图定义中使用的 CLR 函数和 CLR 用户定义类型方法必须具有下表所示的属性设置。
“属性” 注意 DETERMINISTIC = TRUE 必须显式声明为 Microsoft .NET Framework 方法的属性。 PRECISE = TRUE 必须显式声明为 .NET Framework 方法的属性。 DATA ACCESS = NO SQL 通过将 DataAccess 属性设置为 DataAccessKind.None 并将 SystemDataAccess 属性设置为 SystemDataAccessKind.None 来确定。 EXTERNAL ACCESS = NO 对于 CLR 例程,该属性的默认设置为 NO。 -
必须使用 WITH SCHEMABINDING 选项创建视图。
-
视图必须仅引用与视图位于同一数据库中的基表。 视图无法引用其他视图。
-
视图定义中的 SELECT 语句不能包含下列 Transact-SQL 元素:
COUNT ROWSET 函数(OPENDATASOURCE、OPENQUERY、OPENROWSET 和 OPENXML) OUTER 联接(LEFT、RIGHT 或 FULL) 派生表(通过在 FROM 子句中指定 SELECT 语句来定义) 自联接 通过使用 SELECT * 或 SELECT table_name来指定列。* DISTINCT STDEV、STDEVP、VAR、VARP 或 AVG 公用表表达式 (CTE) float*text,ntext,image,XML,或filestream列子查询 包括排名或聚合开窗函数的 OVER 子句 全文谓词(CONTAIN、FREETEXT) 引用可为 Null 的表达式的 SUM 函数 ORDER BY CLR 用户定义聚合函数 返回页首 CUBE、ROLLUP 或 GROUPING SETS 运算符 MIN、MAX UNION、EXCEPT 或 INTERSECT 运算符 TABLESAMPLE 表变量 OUTER APPLY 或 CROSS APPLY PIVOT、UNPIVOT 稀疏列集 内联或多语句表值函数 OFFSET CHECKSUM_AGG *索引的视图可以包含
float列; 但是,不能在聚集的索引键中包含此类列。 -
如果存在 GROUP BY,则 VIEW 定义必须包含 COUNT_BIG(*),并且不得包含 HAVING。 这些 GROUP BY 限制仅适用于索引视图定义。 即使一个索引视图不满足这些 GROUP BY 限制,查询也可以在其执行计划中使用该视图。
-
如果视图定义包含 GROUP BY 子句,则唯一聚集索引的键只能引用 GROUP BY 子句中指定的列。
-
使用SSMS数据库管理工具创建索引视图
1、连接数据库,选择数据库,展开数据库-》右键视图-》选择新建视图。
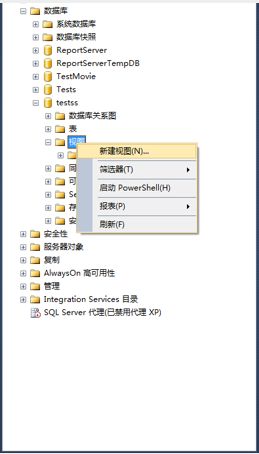
2、在添加表弹出框-》选择要创建视图的表、视图、函数、或者同义词等-》点击添加-》添加完成后选择关闭。
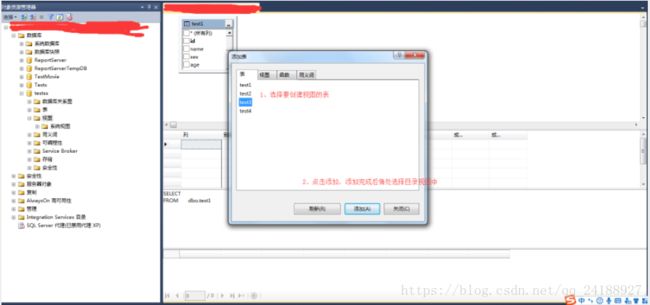
3、在关系图窗格中-》选择表与表之间关联的数据列-》选择列的其他排序或筛选条件。
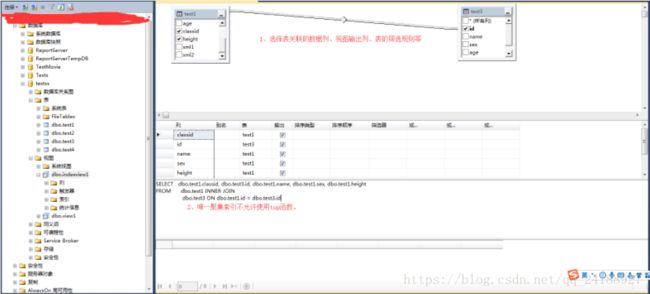
4、右键点击空白处-》选择属性。
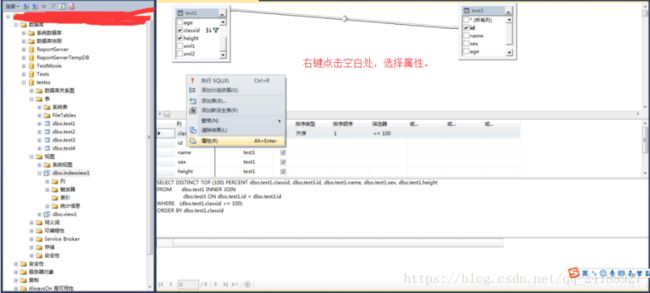
5、在视图属性窗格-》绑定到架构选择是-》非重复值选择是。
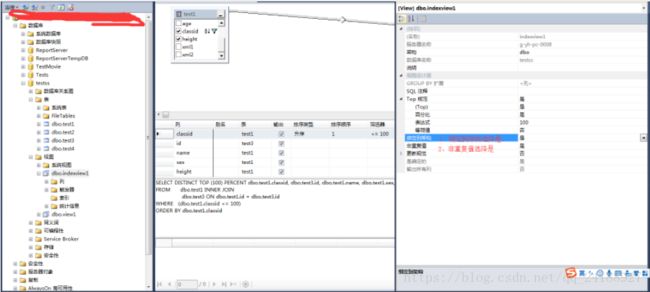
6、点击保存或者ctrl+s-》查看新创建的视图。
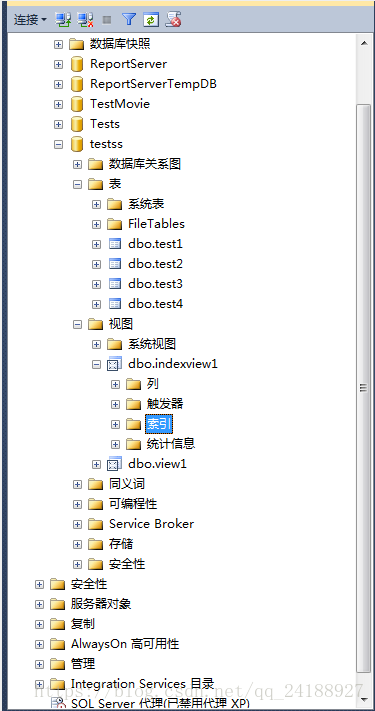
7、在对象资源管理器窗口-》展开视图-》选择视图-》右键点击索引-》选择新建索引-》选择聚集索引。

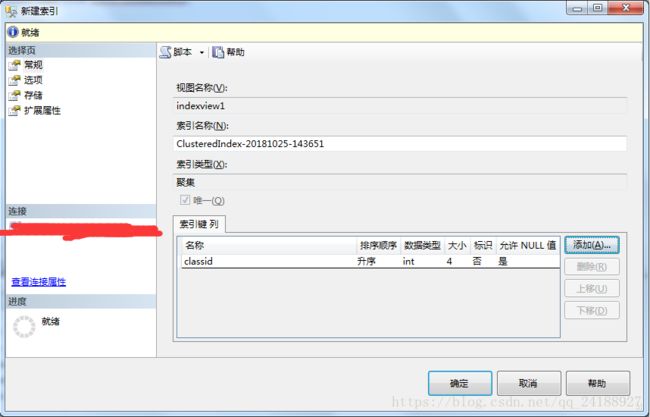
8、在新建索引弹出框-》选择索引数据列-》索引创建步骤可以参考本博主的创建索引博文-》点击确定(创建唯一聚集索引之后才能创建非聚集索引)。
9、在对象资源管理器中查看视图中的索引。
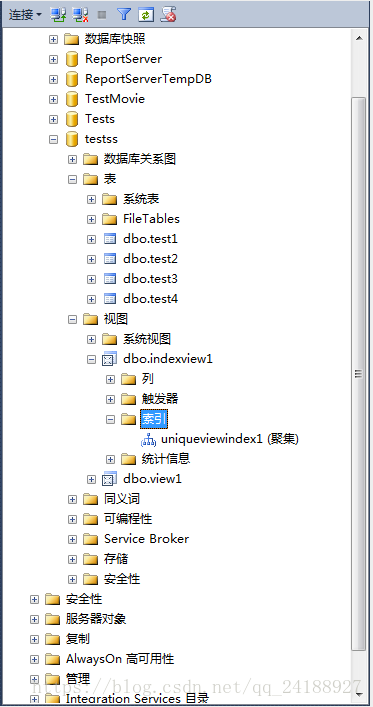
10、刷新视图-》可以创建非聚集索引,步骤同创建聚集索引(此处省略创建非聚集索引)。

11、点击保存或者ctrl+s-》刷新视图-》查看结果。
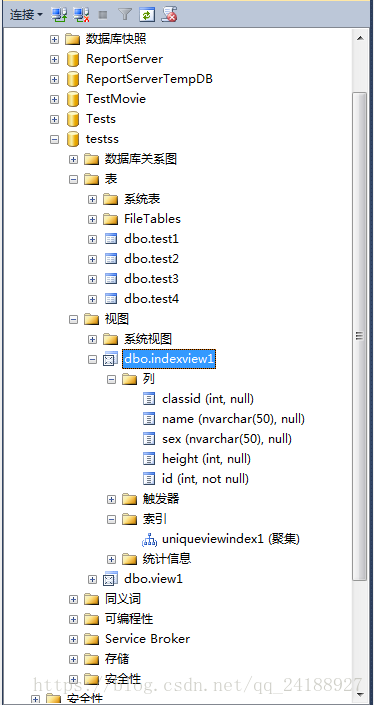
12、使用视图。
使用T-SQL脚本创建索引视图
语法:
--声明数据库引用
use 数据库;
go
--判断视图是否存在,如果存在则删除
if exists(select * from sys.views where name=视图名称)
drop view 视图名称;
go
--创建视图
create
view
--视图所属架构的名称。
--[schema_name][.]
--视图名称。 视图名称必须符合有关标识符的规则。 可以选择是否指定视图所有者名称。
[dbo][.]视图名称
--视图中的列使用的名称。 仅在下列情况下需要列名:列是从算术表达式、函数或常量派生的;两个或更多的列可能会具有相同的名称(通常是由于联接的原因);视图中的某个列的指定名称不同于其派生来源列的名称。 还可以在 SELECT 语句中分配列名。
--如果未指定 column,则视图列将获得与 SELECT 语句中的列相同的名称。
--column
with
--适用范围: SQL Server 2008 到 SQL Server 2017 和 Azure SQL Database。
--对 sys.syscomments 表中包含 CREATE VIEW 语句文本的项进行加密。 使用 WITH ENCRYPTION 可防止在 SQL Server 复制过程中发布视图。
--encryption,
--将视图绑定到基础表的架构。 如果指定了 SCHEMABINDING,则不能按照将影响视图定义的方式修改基表或表。 必须首先修改或删除视图定义本身,才能删除将要修改的表的依赖关系。
--使用 SCHEMABINDING 时,select_statement 必须包含所引用的表、视图或用户定义函数的两部分名称 (schema.object)。 所有被引用对象都必须在同一个数据库内。
--不能删除参与了使用 SCHEMABINDING 子句创建的视图的视图或表,除非该视图已被删除或更改而不再具有架构绑定。 否则, 数据库引擎将引发错误。
--另外,如果对参与具有架构绑定的视图的表执行 ALTER TABLE 语句,而这些语句又会影响视图定义,则这些语句将会失败。
schemabinding
--指定为引用视图的查询请求浏览模式的元数据时, SQL Server 实例将向 DB-Library、ODBC 和 OLE DB API 返回有关视图的元数据信息,而不返回基表的元数据信息。
--浏览模式元数据是 SQL Server 实例向这些客户端 API 返回的附加元数据。 如果使用此元数据,客户端 API 将可以实现可更新客户端游标。 浏览模式的元数据包含结果集中的列所属的基表的相关信息。
--对于使用 VIEW_METADATA 创建的视图,浏览模式的元数据在描述结果集内视图中的列时,将返回视图名,而不返回基表名。
--当使用 WITH VIEW_METADATA 创建视图时,如果该视图具有 INSTEAD OF INSERT 或 INSTEAD OF UPDATE 触发器,则视图的所有列(timestamp 列除外)都可更新。 有关可更新视图的详细信息,请参阅“备注”。
--view_metadata
--指定视图要执行的操作。
as
select_statement
go
--创建索引详情请参考索引博客
if not exists (select * from sys.indexes where name=索引名称)
--设置索引
create
unique
clustered
index
索引名称
on
dbo.视图名
(列名 [ asc | desc],列名 [ asc | desc],......);
go
示例:本示例演示在视图上创建一个唯一聚集索引。
--声明数据库引用
use testss;
go
--判断视图是否存在,如果存在则删除
if exists(select * from sys.views where name='indexview1')
drop view indexview1;
go
--创建视图
create
view
--视图所属架构的名称。
--[schema_name][.]
--视图名称。 视图名称必须符合有关标识符的规则。 可以选择是否指定视图所有者名称。
dbo.indexview1
--视图中的列使用的名称。 仅在下列情况下需要列名:列是从算术表达式、函数或常量派生的;两个或更多的列可能会具有相同的名称(通常是由于联接的原因);视图中的某个列的指定名称不同于其派生来源列的名称。 还可以在 SELECT 语句中分配列名。
--如果未指定 column,则视图列将获得与 SELECT 语句中的列相同的名称。
--column
with
--适用范围: SQL Server 2008 到 SQL Server 2017 和 Azure SQL Database。
--对 sys.syscomments 表中包含 CREATE VIEW 语句文本的项进行加密。 使用 WITH ENCRYPTION 可防止在 SQL Server 复制过程中发布视图。
--encryption,
--将视图绑定到基础表的架构。 如果指定了 SCHEMABINDING,则不能按照将影响视图定义的方式修改基表或表。 必须首先修改或删除视图定义本身,才能删除将要修改的表的依赖关系。
--使用 SCHEMABINDING 时,select_statement 必须包含所引用的表、视图或用户定义函数的两部分名称 (schema.object)。 所有被引用对象都必须在同一个数据库内。
--不能删除参与了使用 SCHEMABINDING 子句创建的视图的视图或表,除非该视图已被删除或更改而不再具有架构绑定。 否则, 数据库引擎将引发错误。
--另外,如果对参与具有架构绑定的视图的表执行 ALTER TABLE 语句,而这些语句又会影响视图定义,则这些语句将会失败。
schemabinding
--指定为引用视图的查询请求浏览模式的元数据时, SQL Server 实例将向 DB-Library、ODBC 和 OLE DB API 返回有关视图的元数据信息,而不返回基表的元数据信息。
--浏览模式元数据是 SQL Server 实例向这些客户端 API 返回的附加元数据。 如果使用此元数据,客户端 API 将可以实现可更新客户端游标。 浏览模式的元数据包含结果集中的列所属的基表的相关信息。
--对于使用 VIEW_METADATA 创建的视图,浏览模式的元数据在描述结果集内视图中的列时,将返回视图名,而不返回基表名。
--当使用 WITH VIEW_METADATA 创建视图时,如果该视图具有 INSTEAD OF INSERT 或 INSTEAD OF UPDATE 触发器,则视图的所有列(timestamp 列除外)都可更新。 有关可更新视图的详细信息,请参阅“备注”。
--view_metadata
--指定视图要执行的操作。
as
select a.id,a.age,a.height,a.name,b.id as classid from dbo.test1 as a
inner join dbo.test3 as b on a.classid=b.id
--要求对该视图执行的所有数据修改语句都必须符合 select_statement 中所设置的条件。 通过视图修改行时,WITH CHECK OPTION 可确保提交修改后,仍可通过视图看到数据。
--with check option;
go
if not exists (select * from sys.indexes where name='umiqueindexview1')
--设置索引
create
unique
clustered
index
umiqueindexview1
on
dbo.indexview1
(name asc);
go
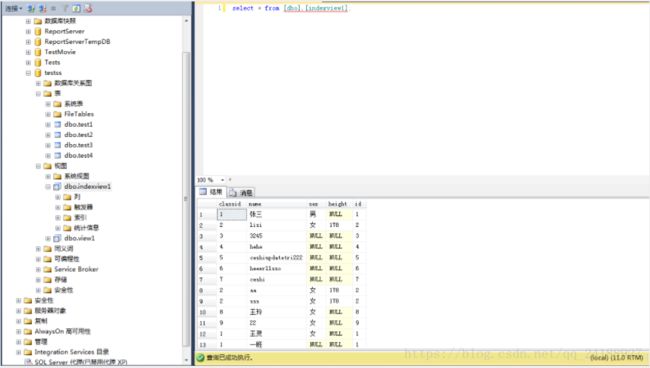
示例结果:因为数据量太小,查询时间和效果不是很明显。
